
ARTICLES
What’s new in Amazon Redshift – 2022, a year in review | 7 min | Cloud | Manan Goel | Amazon Web Services Blog
Take a little step back again and take a look at what Amazon did over the last year. Read about more than 40 of the launched features in Amazon Redshift to help customers with their top data warehousing use cases, for example:
- Self-service analytics
- Easy data ingestion
- Data sharing and collaboration
- Data science and machine learning
- Secure and reliable analytics
- Best price performance analytics
The above-mentioned are described in more detail in the article, enjoy!
Big Ideas in Tech for 2023: An a16z Omnibus | 30 min | Tech | Andreessen Horowitz "a16z" Blog
a16z asked their partners to spotlight one big idea that startups in their fields would tackle in 2023. From entertainment franchise games to the precise delivery of medicines or small modular reactors to loads of AI applications. In the article are 40+ builder-worthy pursuits for the year ahead.
P.S. More summaries and predictions for 2023 in this edition of DATA Pill.
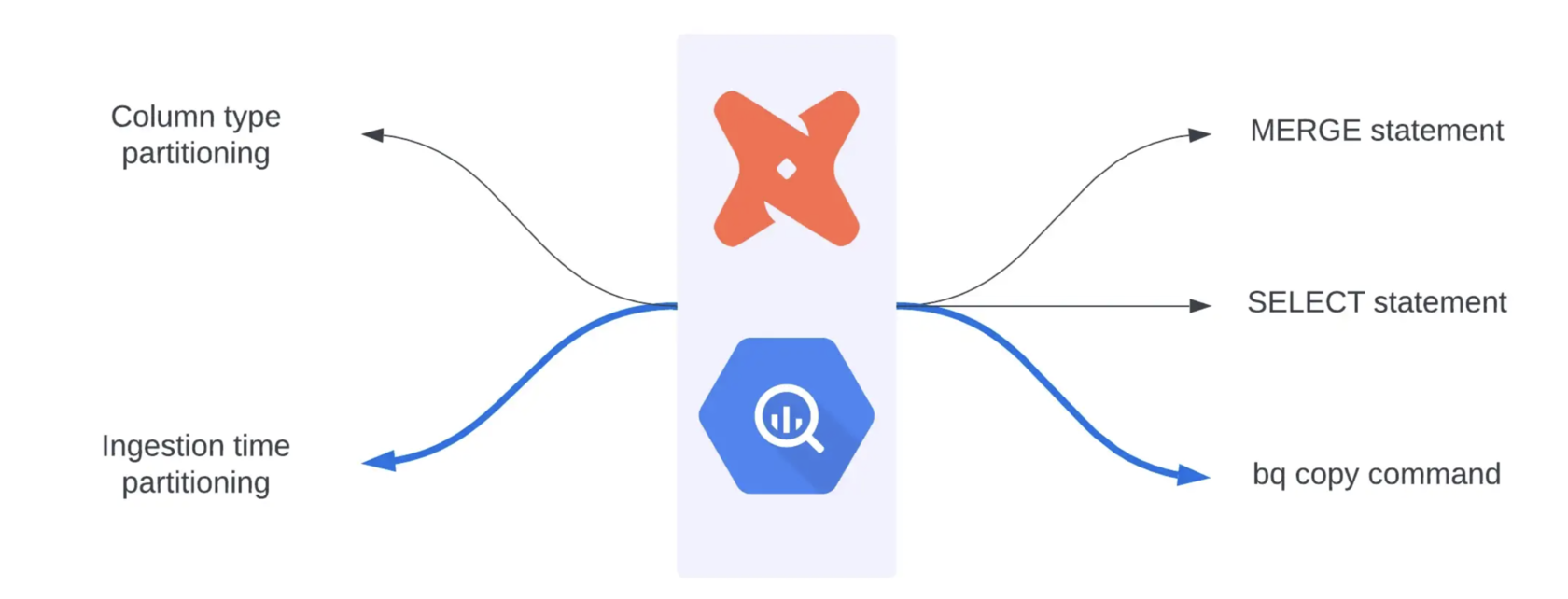
BigQuery Ingestion-Time Partitioning and Partition Copy With dbt | 7 min | Data Engineering | Christophe Oudar | Teads Engineering Blog
How can you achieve better performance from your models? Read the story on how Teads built an internal SQL query executor tool to wrap the execution of BigQuery Jobs, that now is a part of their go-to solution.
Software Engineering Roadmap For Data Scientists | 12 min | Data Science | Youssef Hosni | Personal Blog
Some tips from Youssef on how to develop software and programming skills as a data scientist. For people who already have strong programming skills and would like to take it to the next level. 10 areas to work on and how to do it is already waiting for you to read.
Read the review of the book Fundamentals of Data Engineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons.
What will you find here?
- The Data Engineering Lifecycle and its undercurrents
- Principles of a good Data Architecture
- Types of data architecture
and a little about choosing technology, security and privacy, and the future of Data Engineering.
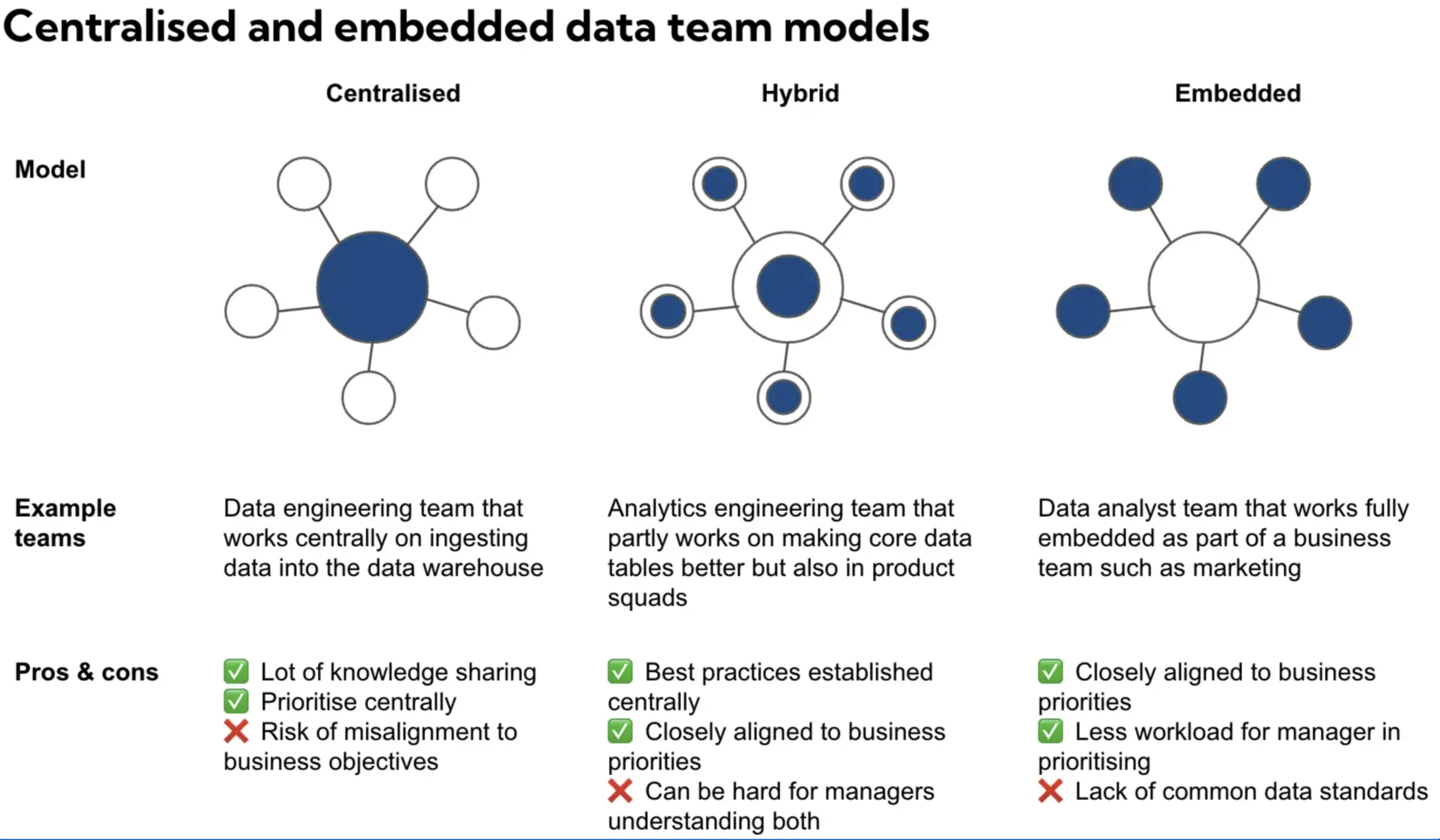
Data team structure: embedded or centralized? | 4 min | Data Engineering | Mikkel Dengsøe | Personal blog
If you are building a Data team you have to decide what structure you will make. Mikkel answers some of the most frequently asked questions.
- Should my data team operate centralized or embedded?
- What technical implications does this have?
- What’s the right data team constellation?
Recycling Kubernetes Nodes | 7 min | Kubernetes | Ilkin Mammadzada | yelp blog
Manually managing the lifecycle of Kubernetes nodes can become difficult as the cluster scales. Especially if your clusters are multi-tenant and self-managed. You may need to replace nodes for various reasons, such as OS upgrades and security patches. One of the biggest challenges is how to terminate nodes without disturbing the tenants. This blogpost is on how they managed this at yelp.
Deep Learning for Infinite (Multi-Lingual) Keywords | 7 min | ML | Sachinthaka Abeywardana | Canva blog
How Canva used a CLIP-inspired model to suggest keywords for template labeling in multiple languages. In this blog post Sachinthaka will walk you through how they gathered the data, designed the model architecture, trained with the special loss function that they chose and finally discuss the results.
TUTORIALS
Best practices for using Terraform | 15 min | Cloud | Google Cloud Blog
If you have already got started with Terraform, this one can be something of interest for you. This is a document that provides guidelines and recommendations for effective development with Terraform across multiple team members and work streams.
NEWS
New Built-in Functions for Databricks SQL | 5 min | Data Engineering | Daniel Tenedorio, Entong Shen and Serge Rielau | Databricks Blog
An announcement about a useful subset of the new functions.
-LOG10 function accepts a numeric input argument and returns the logarithm with base 10 as a double-precision floating-point result,
-LOWER function accepts a string and returns the result of converting each character to lowercase.
What does this mean for your data processing journeys? Read more and find examples of how they may prove useful.
PODCAST
Safely Test Your Applications And Analytics With Production Quality Data Using Tonic AI | 46 min | AI | host: Tobias Macey; guest: Adam Kamor | Data Engineering Podcast
The most interesting and challenging bugs always happen in production, but recreating them is a constant challenge, due to differences in the data that you are working with. Building your own scripts to replicate data from production is time consuming and error-prone. Listen to the episode where Adam Kamor explores:
- the factors that make this such a complex problem to solve,
- the approach that he and his team have taken to turn it into a reliable product,
- how you can start using it to replace your own collection of scripts.
DATA TUBE
MLOps Q&A with Marcin Zabłocki | 11 min | MLOps | Marcin Zabłocki | GetInData
In this Q&A session, Marcin answers the following:
- How expensive is it to run pipelines in Vertex AI pipelines compared to running them in AirFlow (GCP Composer)?
- How do you test a pipeline?
- Is there a way to convert the Kedro pipeline to Apache Beam?
Plus more MLOps-related questions.
CONFS EVENTS AND MEETUPS
Paper Talks - Emergent Abilities of Large Language Models | 2 Feb | Webinar
The next Paper Talks meeting is coming! A meeeting for anyone interested in Data Science or Machine Learning. If you join the event, you will be able to meet the Analytics team and talk with them about a paper called “Emergent Abilities of Large Language Models”. They are encouraged to be active and leave comments about the paper before the event. No registration needed!
Optimizing data in Apache Iceberg: Performance strategies & Foundations of Data Teams | 16 Feb | Double Webinar
1 Optimizing data in Apache Iceberg: Performance strategies with Dipankar Mazumdar
In this talk, Dipankar will walk you through the various data & file optimization strategies that help to achieve robust performance in #ApacheIceberg.
- Small file problem in Iceberg: Compaction strategy
- Reorganization of data within data files
- Sorting, Hierarchical sorting
- Problems with normal sorting strategies
- Z-order clustering for multiple dimensions
2 Foundations of Data Teams with Jesse Anderson
- What happens when we’re misled or unaware of what a solid foundation for data teams means?
- When a data team is missing or understaffed, the entire project is at risk of failure.
This talk will cover the importance of a solid foundation and what management should do to fix it. To do this Jesse will be sharing a real-life analogy to show how we can be misled and what this means for our success rates.
Snowflake on Snowflake: Building Sales Analytics in Cloud | 1 March | Webinar
During this webinar you will learn about:
- Snowflake’s sales data ecosystem
- The architecture of our Sales Data Cloud Several
- Sales Data Cloud use cases including; business analytics (customer 360, forecasting, notification system) and data science (data enrichment, predictive modeling)

________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig in previous editions DataPill
