
ARTICLES
One StreamProcessor to rule them all | 7 min | Data Engineering | Robert Sahlin | Personal Blog
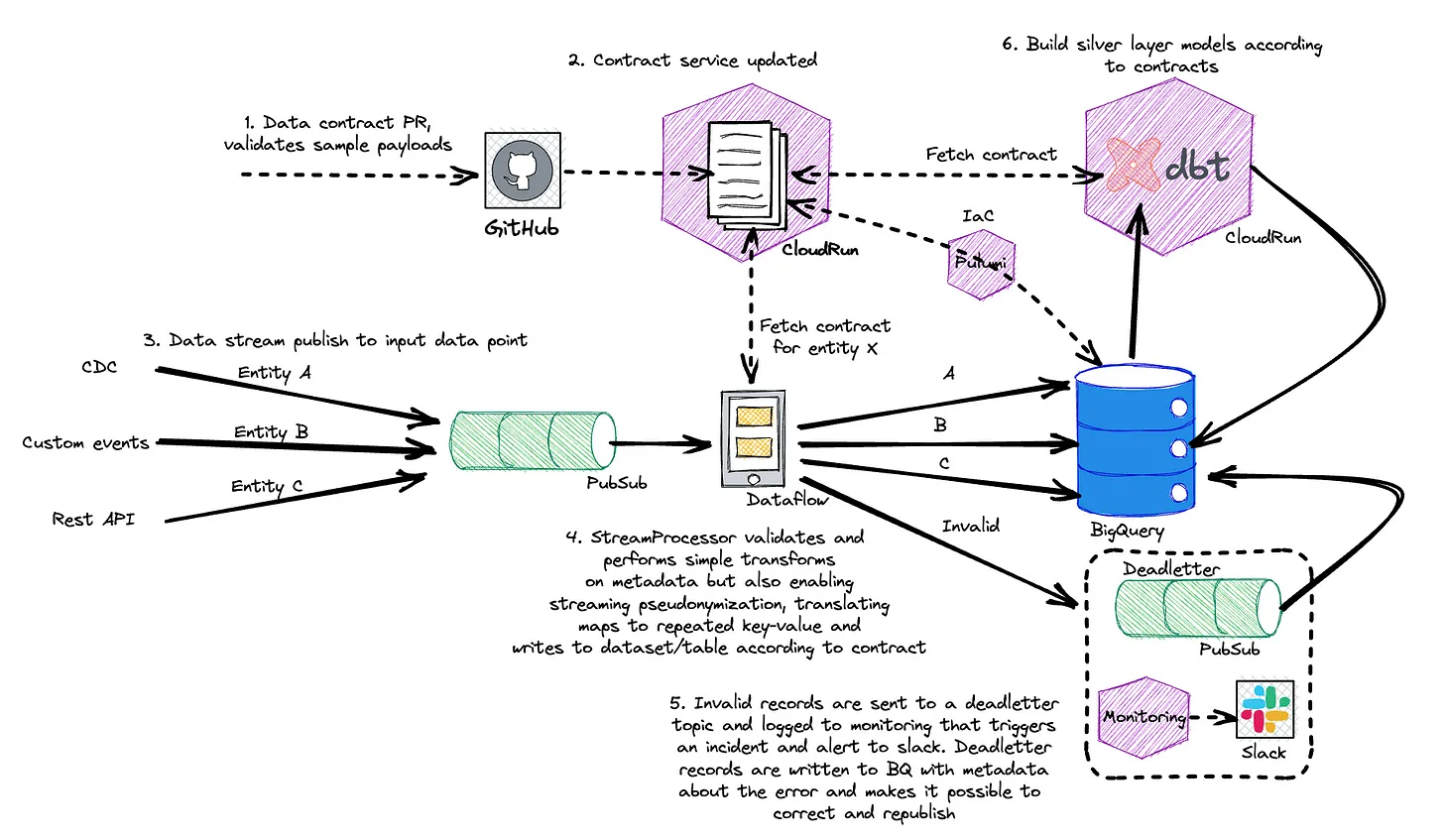
Dive into a story about how during the past six months, Mathem transitioned to a data platform team, emphasizing data contracts and a unified architecture. This involves streaming Beam jobs, GCP Dataflow and DBT for data warehousing. StreamProcessor consolidates data streams, optimizing resource usage whilst data contracts handle the schema and metadata, and enable customized data processing.
Debugging Ad Delivery At Pinterest | 7 min | Data Engineering | Nishant Roy | Pinterest Engineering Blog
This blog describes how we built a system to swiftly answer these questions without requiring deep technical expertise or a context. Read more about the three goals they had:
- Improving advertiser satisfaction by reducing the time taken to resolve their issues
- Automating the data analysis and generating recommendations for the advertiser to improve the delivery rate
- Coveraging all system components (indexing, budgeting/pacing, candidate generation, ranking, ad funnel, auction, etc.)
Dive into the challenges they faced, like Data Coverage, microservices, accessibility to Non-Engineering teams and the solutions they have made.
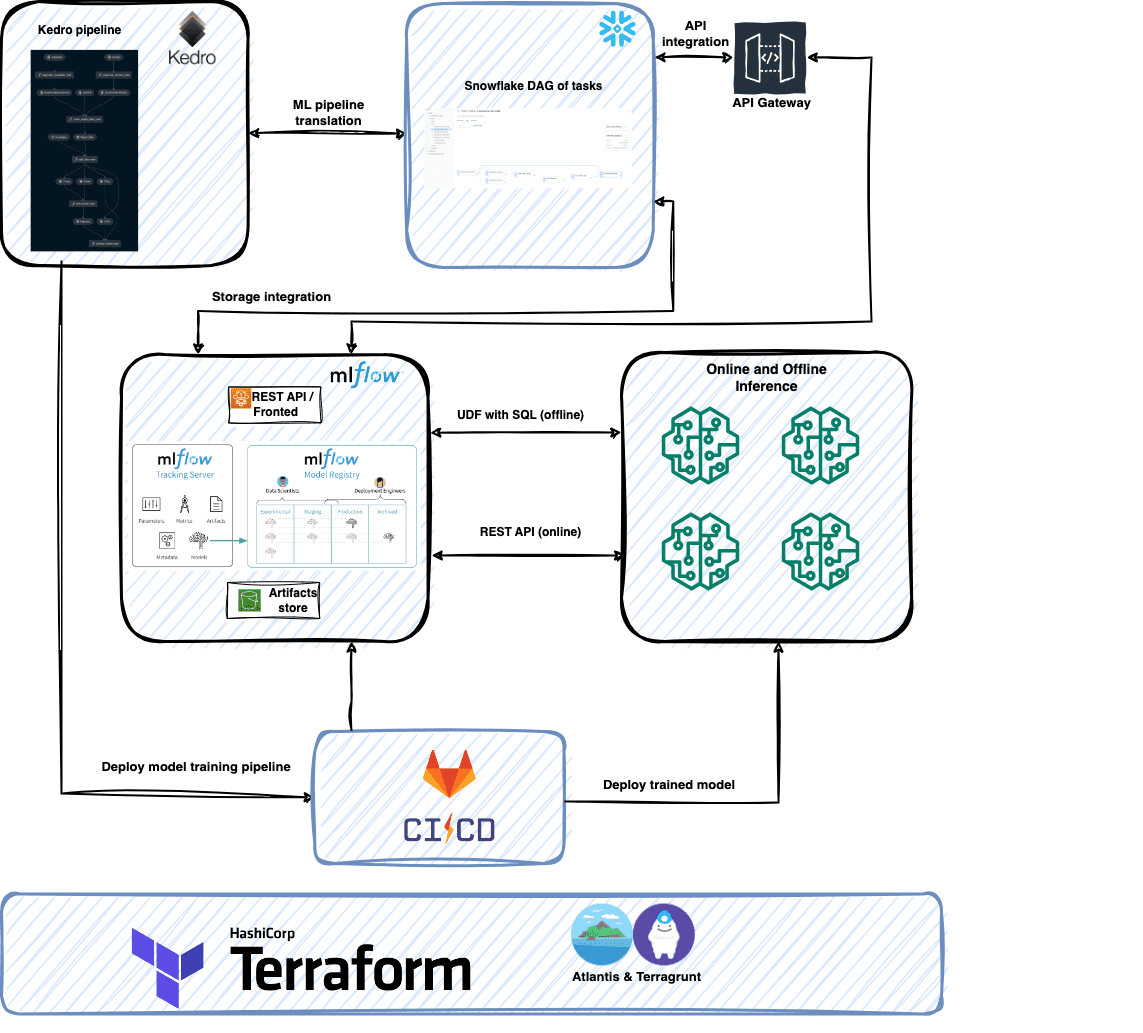
From 0 to MLOps with ❄️ Part 2: Architecting the cloud-agnostic MLOps Platform for Snowflake Data Cloud | 9 min | Data Analysis | Marcin Zabłocki, Marek Wiewiórka, Michał Bryś | GetInData | Part of Xebia Blog
Remember the first part of the article from the DATA Pill 56 edition where Marcin, Marek and Michał presented their kedro-snowflake plugin that enables you to run your Kedro pipelines on the Snowflake Data Cloud in 3 simple steps? Your wait for the next part is over right now. Dive into the instructions on how you can implement the end-to-end MLOps platform on top of Snowflake powered by Kedro and MLflow.
TUTORIALS
Managing complex infrastructure using AWS CDK and Go | 6 min | Cloud | Konstantinos Bessas | Xebia Blog
If you are interested in getting started with the AWS CDK in combination with Go language then this text is for you. Compare the Python and the Go implementation and identify the differences and solutions on how you can implement the same functionality, but in these different programming languages.
Accelerate data science feature engineering on transactional data lakes using Amazon Athena with Apache Iceberg | 10 min | Cloud | Vivek Gautam, Naresh Gautam, Harsha Tadiparthi, Mikhail Vaynshteyn | AWS Blog
In this one, the AWS team demonstrates how to perform feature engineering using Athena with Apache Iceberg. You can also read about using the CTAS query to create an Apache Iceberg table on Athena from an existing dataset in Apache Parquet format, adding new features in an existing Apache Iceberg table on Athena using the ALTER query, and using UPDATE and MERGE query statements to update the feature values of existing columns.
TOOLS
GPT Engineer | 4 min | AI | Anton Osika | Github
Specify what you want it to build, the AI asks for clarification, and then builds it. GPT Engineer is made to be easy to adapt, extend and make your agent learn how you want your code to look. It generates an entire codebase based on a prompt.
DATA LIBRARY
Guide to Recommendation Systems | ML | Michał Stawkowski, Borys Sobiegraj, Adrian Dembek, Michał Madej | GetInData | Part of Xebia
Let’s explore the recommendation systems definition, how they work, how you can implement them, what benefits you can get from recommendations and how you should measure the performance and business value of recommender systems. At the end you can read about the GID ML Framework and how it can help you in developing your recommendation systems.
NEWS
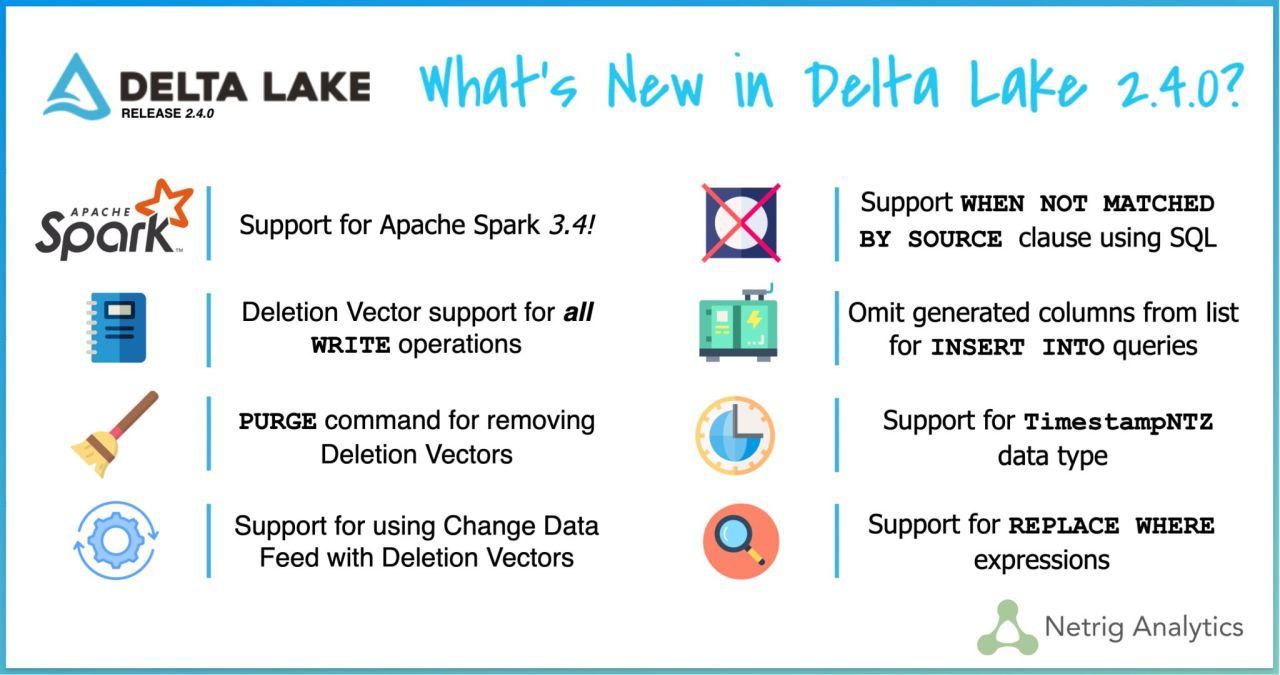
Delta Lake 2.4.0 | 3 min | Data Engineering | Allison Portis | Github
We are excited to announce the release of Delta Lake 2.4.0 on Apache Spark 3.4. Similar to Apache Spark™, we have released Maven artifacts for both Scala 2.12 and Scala 2.13.
The key features in this release are as follows, for example:
- Support for Apache Spark 3.4.
- Support writing Deletion Vectors for the DELETE command. Previously, when deleting rows from a Delta table, any file with at least one matching row would be rewritten. With Deletion Vectors, these expensive rewrites can be avoided. See 'What are deletion vectors?' for more details.
- Support for all write operations on tables with Deletion Vectors enabled.
Introducing Azure OpenAI Service On Your Data in Public Preview | 6 min | AI | Andy Beatman | Microsoft Blog
Microsoft announces Azure OpenAI Service in public preview. Harness the power of OpenAI models like ChatGPT and GPT-4 with your data. Revolutionize data interaction, analysis, and gain valuable insights. Discover features, use cases, data sources, and the next steps in leveraging Azure OpenAI Service.
Dremio’s Generative AI Features for Easy Analysis | 3 min | AI | Dremio Blog
Mayo Clinic teams up with Google Cloud to boost patient care. AI-powered tools will make it simpler for doctors to find important info and improve clinical workflows. This collaboration ensures HIPAA compliance for secure data access and informed decision-making.
DATA TUBE
Column-level lineage is coming to the rescue | 34 min | AI | Paweł Leszczyński, Maciej Obuchowski | Berlin Buzzwords 2023
OpenLineage is a standard for metadata and lineage collection that is growing rapidly. Column-level lineage is one of its most anticipated features of the community that has been developed recently.
Listen to the talk where Paweł and Maciej:
- show foundations for column lineage within OpenLineage standard,
- provide real-life demo on how is it automatically extracted from Spark jobs,
- describe and demo column lineage extraction from SQL queries,
- show how the lineage can be consumed on Marquez backend.
They aim to provide demos to focus on practical aspects of the column-level lineage which are interesting to data practitioners all over the world.
PODCAST
Data Journey with Jakub Janicki - Data, Analytics, and Big Data industry | 60 min | Data Analytics | host: Adam Kawa; guest: Jakub Janicki | Radio DaTa
Let’s listen to a talk with Jakub, who has over 15 years of experience in the financial industry, especially in using data & analytics at banks. Before joining Commerzbank in 2019, he had been working at mBank and Alior Bank.
In this episode, you can find out:
- How banks use data & analytics
- Types of data that banks analyze, e.g., payments, clickstream, chatbot conversations
- Importance of personalized approach to every customer and its real-world examples
- Use of AI in the banking industry, e.g., Doc AI, Personalized AI assistants & advisors
and much more.
CONFS EVENTS AND MEETUPS
Snowflake Warsaw Meetup | Warsaw | 27th June
Learn from the trailblazers from some of Poland’s leading companies how they leverage data to solve their most demanding data challenges, and connect with your fellow data leaders from across the country. You will have an opportunity to listen to Marek Wiewiórka’s presentation: From 0 to MLOps with ❄️Snowflake Data Cloud that is related to text you could read in the articles section.
Sage With Snowflake’s Data Cloud Deployment Framework | Online webinar | 18th July
Join and learn how to effectively manage your Snowflake costs using advanced techniques from the Data Cloud Deployment Framework. Gain insights into tracking, monitoring, reporting, and receiving alerts to allocate costs across teams and business entities. You will learn how to:
- Utilize DCDF concepts to capture and monitor usage data.
- Leverage chargebacks and showbacks for tracking and allocating cloud infrastructure and services costs.
- Proactively notify your team with native alerts and resource monitors.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
