
ARTICLES
From Image Classification to Multitask Modeling: Building Etsy’s Search by Image Feature | 7 min | Data Engineering | Eden Dolev, Alaa Awad | Etsy Blog
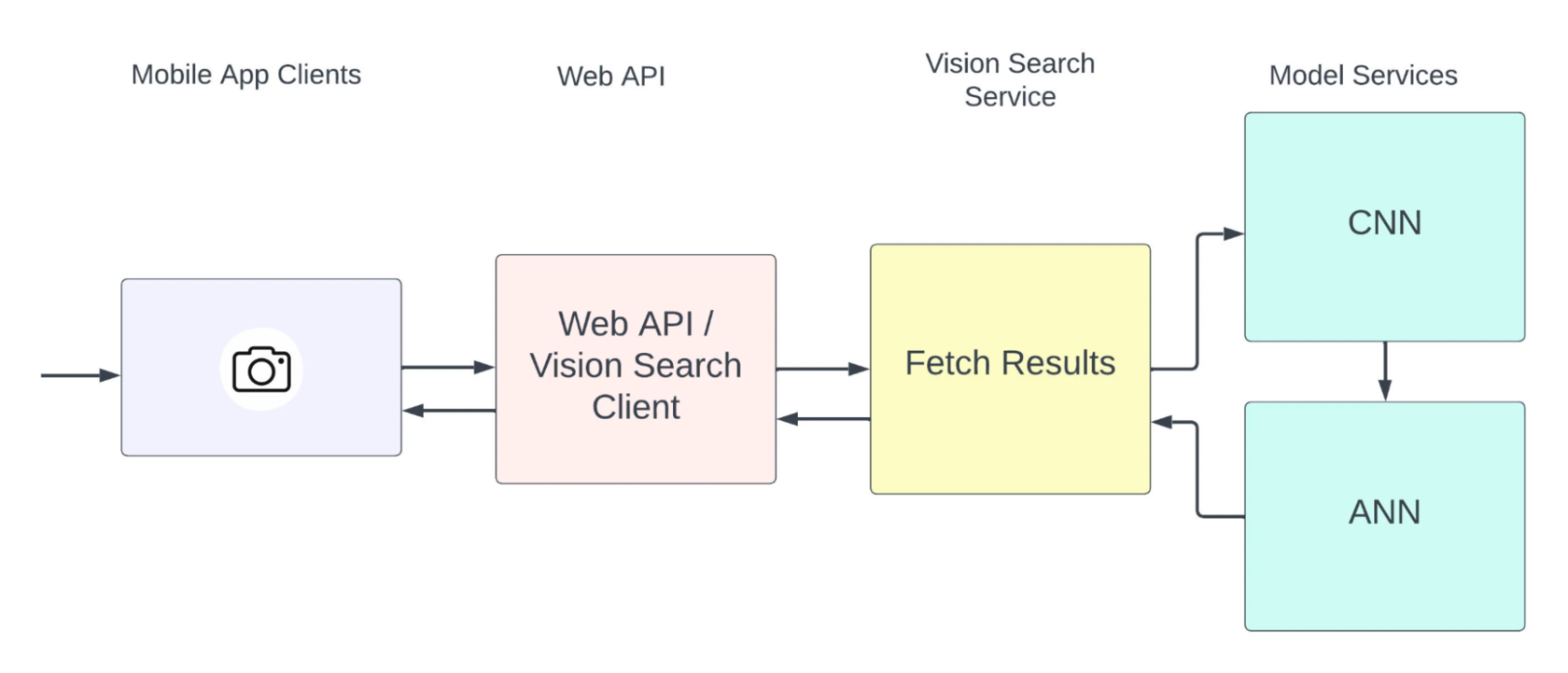
This image-based discovery tool on Etsy’s mobile apps is available now. Read the story on how the Etsy team was able to take a proof-of-concept hackathon project, and turn it into a production feature to help make the millions of unique and special items on Etsy more discoverable for buyers.
Dependency Management at Scale | 5 min | Data Engineering | Adrian Comisel | Yelp Engineering Blog
Keeping project dependencies up to date is crucial, but there is a Yokyo Drift. It actively scans all repositories in use at Yelp and submits pull requests that upgrade any outdated dependencies, and tracks and monitors the progress of these upgrades. Let’s take a quick look at this solution.
Run your first, private Large Language Model (LLM) on Google Cloud Platform | 16 min | LLM | Michał Bryś | GetInData | Part of Xebia Blog
Imagine you want to develop a personalized language model (LLM) powered assistant for generating financial report summaries whilst ensuring the utmost privacy for your organization, but also guaranteeing the utmost privacy for your organization is a challenge.
In his latest blog post, Michal delves into three essential aspects:
- The obstacles that must be surmounted to achieve this goal.
- The approach you can adopt to construct your very own LLM-based assistant.
- Detailed instructions on how to implement this solution on the Google Cloud Platform.
Fine Tuning vs. Prompt Engineering Large Language Models | 9 min | LLM | Niels Bantilan | MLOps Community Blog
Let's dive into this blog post, where Niels describes prompt engineering and fine-tuning in more detail, gives a practical sense of how they are different, and provides you with a few heuristics that will help you begin your fine-tuning journey.
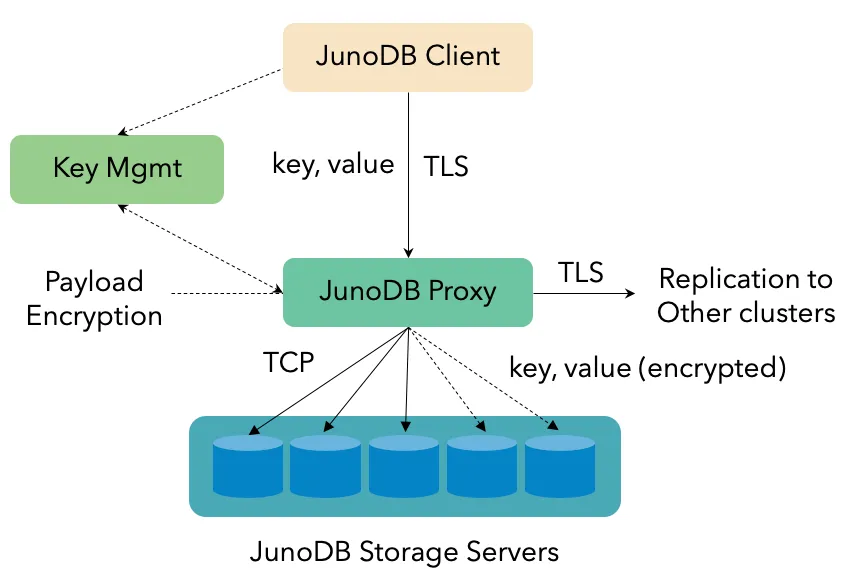
Unlocking the Power of JunoDB: PayPal’s Key-Value Store Goes Open-Source | 11 min | Data Engineering | Yaping Shi | The PayPal Technology Blog
Do you want to have an extremely scalable, secure and highly available NoSQL infrastructure? Meet JunoDB, PayPal’s open-source project available on Github.
JunoDB is a distributed key-value store that plays a critical role in powering PayPal’s diverse range of applications. Virtually every core back-end service at PayPal relies on JunoDB, from login to risk to final transaction processing.
Dive into common use cases, a high-level architecture overview, and more.
Why Modern Data Platforms don’t do ETL anymore | 3 min | Data Science | Christian Lauer | Geek Culture blog
Read and check if you agree with Christian’s opinion that modern data platforms are nowadays shifting away from ETL processes due to high costs, slow pace, high amounts of resources and a high state of inflexibility.
TUTORIAL
From 0 to MLOps with ❄️ Snowflake Data Cloud in 3 steps with the Kedro-Snowflake plugin | 8 min | MLOps | Marcin Zabłocki, Marek Wiewiórka, Michał Bryś | GetInData | Part of Xebia Blog
Marcin, Marek and Michał unveil their newest Kedro-Snowflake plugin. Thanks to this, you can streamline your ML pipelines in Kedro and effortlessly execute them in a scalable Snowflake environment, and all it takes is three simple steps.
Join a streaming data source with CDC data for real-time serverless data analytics using AWS Glue, AWS DMS, and Amazon DynamoDB | 8 min | Cloud | Manish Kola, George Komninos, Santosh Kotagiri, Noritaka Sekiyama, and Chiho Sugimoto | Amazon Web Services Blog
Building and maintaining a transactional data lake that involves real-time data ingestion and processing has multiple variable components and decisions to be made, such as what ingestion service to use, how to store your reference data, and what transactional data lake framework to use.
Dive into the implementation details of such a pipeline, using AWS native components as the building blocks and Apache Hudi as the open-source framework for a transactional data lake.
NEWS
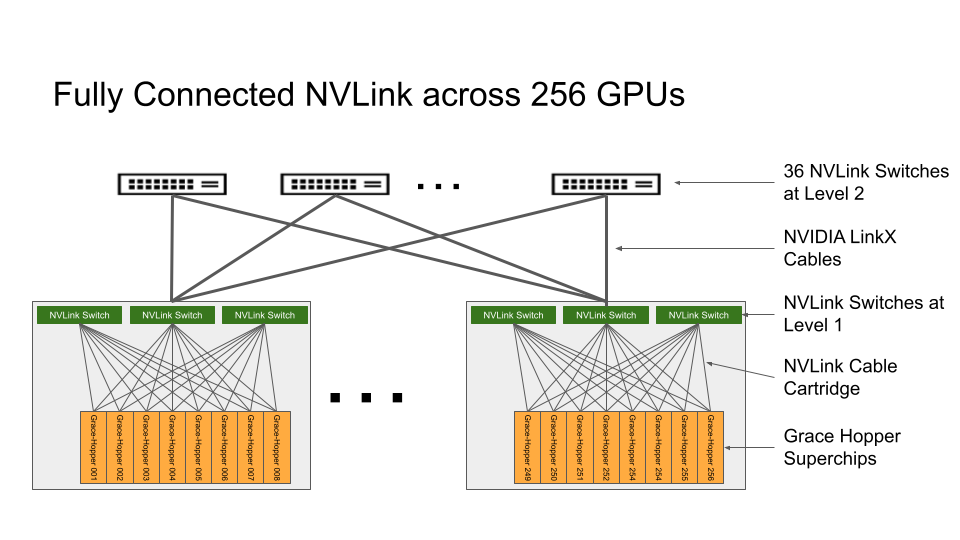
Announcing NVIDIA DGX GH200: The First 100 Terabyte GPU Memory System | 4 min | AI | Pradyumna Desale | Nvidia Developer
During COMPUTEX 2023, NVIDIA made an exciting revelation by introducing the NVIDIA DGX GH200. This groundbreaking development in GPU-accelerated computing is set to revolutionize handling massive AI workloads. Apart from highlighting the critical elements of the NVIDIA DGX GH200's architecture, this announcement also explores the capabilities of NVIDIA Base Command, which facilitates swift deployment, expedites user onboarding and streamlines system management processes.
PODCAST
Data Strategy: Key Principles and Best Practices | 56 min | Data Engineering | Host: Richie Cotton; Guest: Boyan Angelov | DataTalks.Club Podcast
In this episode, you will discover how organizations leverage data to make informed decisions, drive innovation and gain a competitive edge. Tune in to this episode to uncover critical strategies for building a robust data foundation, optimizing data governance and unlocking the true potential of your data assets.
CONFS EVENTS AND MEETUPS
LLMs in Production | 15-16th June | Online
Join 50 Speakers from Stripe, Meta, Canva, Databricks, Anthropic, Cohere, Redis, Langchain, Chroma, Humanloop and so many more.
It is a two day conference of talking with some of our favorite people at the forefront of using LLMs in the wild, and an in-person workshop in San Francisco on how to build and deploy LLM based apps hosted by Anyscale.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
