
ARTICLES
Using BigQuery Change Data Capture with dbt Incremental | 5 min | BigQuery | Jay Lewis | Feefo Product Engineering Blog
Change history (pre-GA) allows tracking the history of changes to a BigQuery table. This allows the user to incrementally maintain a table replica outside of BigQuery, avoiding costly copies. An interesting use case on how to link it with dbt incremental models (be aware of limitations).
How we built a Modern Data Platform in 4 months for Volt.io, a FinTech scale-up | 19 min read | Data Platform | Paweł Kociński & Rafał Zalewski | GetInData Blog
The data journey with Volt.io. In this blog post you can find the architecture of the Modern Data Platform.
A designed and built Modern Data Platform based upon Cloud components including:
- data ingestion (Airbyte),
- data transformation (dbt),
- orchestration (Amazon Managed Workflows for Apache Airflow)
- data warehouse (Snowflake).
Autotuner API for Apache Spark — Optimize Apache Spark at Scale | 4 min read | Apache Spark | Kartik Nagappa | Dev Genius Blog
The Sync Autotuner API enables you to continuously monitor and tune your Apache Spark jobs at scale by making it easy to harness the capability of the Sync Autotuner in a programmatic manner.
The Sync Autotuner will quickly provide you with the most optimal set of cluster configurations, in terms of cost, runtime and infrastructure selection. Furthermore, it is able to do this using data from a single run.
Deep Learning for Search Ranking at Etsy | 10 min read | Deep Learning | Lucia Yu, Congzhe Su, Cung Tran & Robert Forgione | Etsy Blog
Etsy’s journey from a decision tree model to a unified deep learning model for search ranking.
Along the way we had to modernize our ML development pipeline, and we moved to open-source tools and functions – with TF Ranking, TensorFlow's learning-to-rank library, at the core, along with off-the-shelf losses and metrics – to build the new model.
Streaming Data into Apache Iceberg Tables Using AWS Kinesis and AWS Glue | 10 min | Streaming | Alex Merced | Subsurface Community
This tutorial aims to show how you can take advantage of the power of Iceberg tables and the convenience of AWS Glue for streaming.
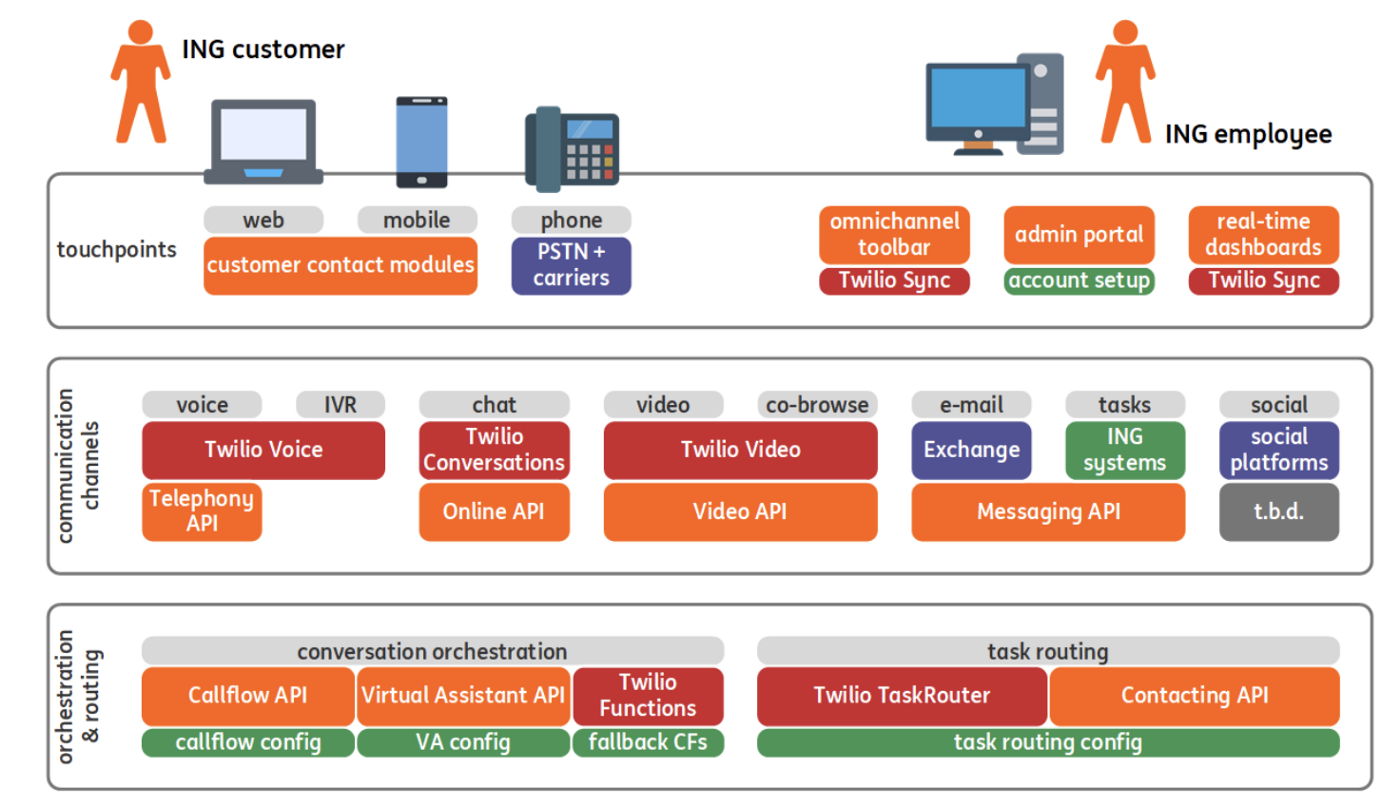
ING Contact Center 2.0 — Creating Resilient APIs | 6 min | DevOps | Ayush Mittal | ING Blog
The ING journey to the CC 2.0 platform, the patterns in the CC 2.0 applied to achieve high availability and resiliency.
Probabilistic Data Structures and Algorithms in NoSQL databases | 10 min read | Databases | Michał Knasiecki | Allegro Tech Blog
What would you say if you stored 1 000 records in a database, and the database claimed that there were only 998 of them? Behavior like this is not necessarily an error, as long as you use a database that implements probabilistic algorithms and data structures. Solutions based on these methods allow for some inaccuracy in the results, but in return they are able to provide us with great savings in the resources used.
In this post, you will learn about two probability-based techniques, see experiments and consider when it is worth using a database like this.
Building & Operating High-Fidelity Data Streams | 18 min | Streams | Sid Anand | InfoQ Blog
- The 2 most important top-level metrics for any streaming data pipeline are lag and loss. Lag expresses the amount of message delay in a system. Loss measures the magnitude of loss as messages transit the system.
- Most streaming data use-cases require low latency (i.e. low end-to-end message lag) but they also require low or zero loss. It is important to understand that performance penalties do exist when building a loss-less pipeline – i.e. to build for zero loss, you need to give up some speed. However, there are some strategies to minimize lag over an aggregate of messages (i.e. increase throughput via parallel processing). By doing this, we may have a lag floor, but we can still maximize throughput.
Pursuing Lineage from Airflow using Custom Extractors | 6 min | Airflow | Maciej Obuchowski & Michael Robinson | OpenLineage Blog
The OpenLineage Airflow integration detects which Airflow operators your DAG is using and extracts lineage data from them using extractors.
NEWS
Discovering novel algorithms with AlphaTensor | 10 min | Alhussein Fawzi, Matej Balog, Bernardino Romera-Paredes, Demis Hassabis, Pushmeet Kohli | Research | Deep Mind Blog
In our paper, published today in Nature, we introduce AlphaTensor, the first artificial intelligence (AI) system for discovering novel, efficient, and provably correct algorithms for fundamental tasks such as matrix multiplication. This sheds light on a 50-year-old open question in mathematics about finding the fastest way to multiply two matrices.
Apache StreamPark | Stream Processing
A new streaming application development framework and operation platform is incubating. Although it's hard to understand what this framework is... it seems like this:
- it's a library/ framework over the Flink Datastream API that allows you to create applications more easily, e.g. by extracting configurations into yaml
- a project framework with CLI , which allows you to write SQL jobs in a file and submit jobs to a cluster
- a set of extra connectors - please note that there is also JDBC with 2PC or http sink, that fit into this framework!
- something (but don't know what!) to facilitate deployment on K8s
New startup CPU boost improves cold starts in Cloud Run, Cloud Functions | 10 min | Cloud | Steren Giannini | Google
Google has announced the startup CPU boost for Cloud Run and Cloud Functions 2nd gen. This new feature allows the user to drastically reduce the cold start time of Cloud Run and Cloud Functions.
Internal testers and private preview customers reported the following startup time reductions for their Java applications:
- up to 50% faster for the Spring PetClinic sample application
- up to 47% faster for a Native Spring w/GraalVM service
- up to 23% faster for plain Java Cloud Functions
Introducing Make-A-Video: An AI system that generates videos from text | 3 min | AI | Steren Giannini | Meta AI
Meta announced Make-A-Video, a new AI system that lets people turn text prompts into brief, high-quality video clips.
Google showcases TensorStore ML open-source software library | 5 min | ML | Ben Wodecki | AI Business
Google has unveiled TensorStore, a C++ and Python open-source software library designed to decrease ML system development time.
The library, developed by Google Research, is designed to avoid issues relating to storing and manipulating data, providing users with an API capable of handling large datasets without requiring the use of powerful devices.
PODCAST
2022 State of DevOps Survey | 44 min | DevOps | hosts: Stephanie Wong and Chloe Condon; guests: Nathen Harvey and Derek DeBellis | GCP Podcast
The talk about key findings in the 2022 DevOps report published by Google, especially in the security space. Some of the most notable findings include the adoption of DevOps security practices and the decreased incidence of burnout on teams who leverage security practices. Nathen and Derek elaborate on how this year’s research has changed from last year and what remained the same.
DataTube
Stream Designer | The Visual Builder for Kafka Pipelines in Confluent Cloud | 6 min | Streams | Jon Fancey | Confluent
Confluent announced: Stream Designer which will enable you to:
- Boost developer productivity by reducing the need to write boilerplate code
- Unlock a unified end-to-end view to update and maintain pipelines throughout their lifecycle
- Accelerate real-time initiatives with sharable and reusable pipelines on an open platform
CONFS EVENTS AND MEETUPS
Airbyte Hacktoberfest | by 2 November | event for the community
Airbyte is handing out prizes to anyone who helps to build or edit a connector.
Anyone who submits a connector within the event dates will receive $500 and Airbyte swag.
Google Cloud NEXT’ 22 | 11-14 0ctober | Online
24 hours of broadcast from around the world professionals: Noram, Tokyo, Bengaluru, Munich stages. Live programming and much more.
Big Data Tech Warsaw Summit | 29-30 March 2023 | online and onsite | Call For Presentation till 15 November
A chance to speak in front of an audience of Big Data professionals.
More than 500 professionals will attend the conference to hear dozens of technical presentations. One of them could be yours ;) BDTW has opened a call for presentation.
