
ARTICLES
The Rise of DataOps | 12 min | DataOps | Prukalpa | Towards Data Science Blog
Today, 75% of executives don’t trust their own data, and only 27% of data projects are successful. DataOps could be the resolution for data chaos.
Gartner released predictions that DataOps will fully penetrate the market in 2–5 years.
In this comprehensive article, Prukalpa explains what DataOps is and its assumptions and values.
Intrinsically interpretable models: explaining a linear regression model | 4 min read | Data Science | Frida Karvouni | AH Technology Blog
In this article, the marginal contributions of a linear regression model are calculated.
Conclusions:
Explaining a linear regression model is a straightforward process which is easily implemented. Calculating the marginal contributions gives a clear view of the mechanics of the model. This allows a data scientist to validate the output, explain the predictions to stakeholders with more confidence and tune the model based on the findings.
7 Tips For Optimizing Apache Flink Applications | 13 min read | Data Science & Engineering | Yaroslav Tkachenko, Kevin Lam & Rafael Aguiar | Shopify Blog
A very helpful resource for Flink development. Let's see the first two:1 Having the right profiling tools on hand are key to getting insights into how to solve a performance problem. In the case of Shopify they are:
- Async-profiler
- VisualVM
- jemalloc + jeprof
- Eclipse Memory Analyzer (Eclipse MAT)
- Of course why, and what for are the two things you'll discover in this article.
- Flink doesn’t support serializing Scala’s BigDecimal values, but it can serialize Java ones
- Flink doesn’t support serializing Scala ADTs implemented with a sealed trait and a few case objects, typically representing an enum-like data structure.
- To sum up, after fixing these issues, they noticed a 20 percent throughput increase.
Why we migrated to a Data Lakehouse on Delta Lake for T-Mobile Data Science and Analytics Team | 15 min read | Cloud Computing | Robert Thompson, Geoff Freeman | Delta Lake Blog
The T-Mobile journey to cloud computing. From weekly reporting in Excel and PowerPoint in 2018, through V1 - Delta Lake (TMUS) to finally: V2 - Data Lakehouse.
What were the drivers for change, architecture and approach of both iteration and centralization.
Automated Machine Learning (AutoML) with BigQuery ML. Start Machine Learning easily and validate if ML is worth investing in or not | 10 min read | ML | Michał Bryś | GetInData Blog
AutoML can be an easy start to a Machine Learning journey. We'll be introduced to some AutoML models, followed by an example of the AutoML Classifier model trained in BigQuery ML. Michał discusses:- AutoML's applicability with examples
- limitations
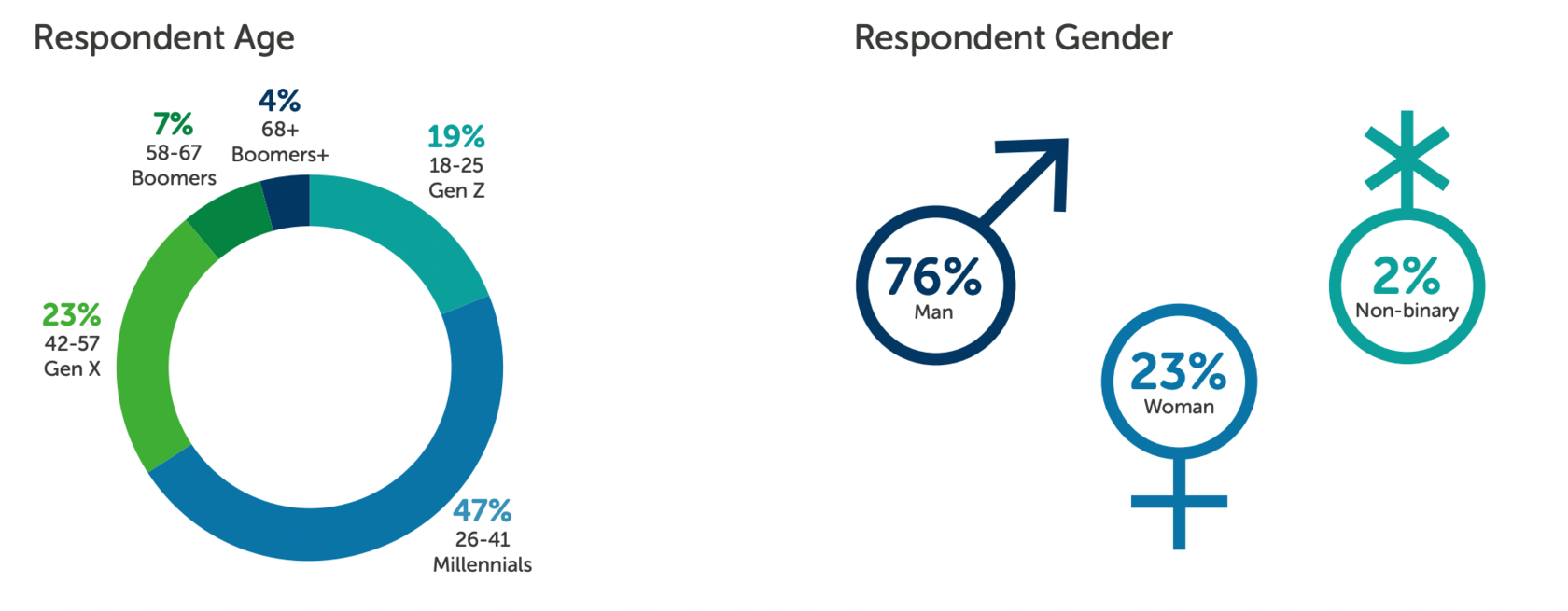
State of Data Science | 5-45 min | Data Science | ANACONDA
Who are Data Scientists, what expectations do they have and what percentage of their time is spent on data preparation versus training models? All can be found in this report.
Managing a BigQuery data warehouse at scale | 8 min | BigQuery | Christophe Oudar | Teads Engineering Blog
An article on how Teads manage the BigQuery data warehouse and how they monitor and manage three important topics:
- Slow queries
- Slots usage
- Table and field sizes
BI tools: Three Generations | 8 min | BI | Louise de Leyritz | Castor App Blog
Business Intelligence tools have gone through three main stages of evolution: Traditional BI, Self-Service BI and Augmented Analytics. All three are characterized in this read.
Why does Self-Service BI Fail and What could Enterprises do to Turn the Tide? | 5 min read | Modern Data Stack | Anh Tran | Analysis With Anh Blog
Common issues with self-service BI tools e.g.:
- flexibility comes with liability - almost infinite possibilities of analysis can be overwhelming. That is why the majority of critical reports and dashboards that are consumed by multiple teams should ideally be taken care of and automated by IT experts
- 75% of managers lack data literacy. This means they can’t understand organizational figures to retrieve any meaningful information from them.
NEWS
Airflow 2.4.0 | 5 min read | GitHub
Fresh from github, still piping-hot release of Airflow 2.4.0
The most anticipated change is this one:
New to this release of Airflow is the concept of Datasets to Airflow, and with it a new way of scheduling dags: data-aware scheduling.
https://airflow.apache.org/docs/apache-airflow/stable/concepts/datasets.html
We're working with Astronomer to make this integration seamless - and data-aware Airflow will help a lot.
Druid 24.0.0 | 5 min read | GitHub
Druid has really caught up! From Clickhouse to even closed source DWHs, while keeping the unique millis-latency OLAP queries execution.
In this release they’ve added INSERT INTO/REPLACE INTO, which allows SQL-based batch ingestion and also in-druid data transformation with SQL (imagine dbt on Druid right now …)
DATA LIBRARY
MLOps: Power Up Machine Learning Process - Build Feature Stores Faster | 85 pages | MLOps | Jakub Jurczak | GetInData
Covers pretty much everything about the Feature Store: how to build a well-functioning Feature Store, which Feature Store to choose and an example of MLOps Platform architecture.
Also provides a more extended insight into the dependencies of ML processes.
Check it out, especially if you're struggling with latency, data silos, data drift or data skew! (free download)

TOOLS
Flink Table Store | 10 min to dig GitHub
Flink Table Store is a data lake storage for streaming updates/deletes changelog ingestion and high-performance queries in real time.
DataTube
Beam Summit 2022 Playlist | Apache Beam
A goldmine of knowledge from the conference, focused around Apache Beam and data and stream processing.
CONFS AND MEETUPS
Last chance to meet in Gdańsk next week:
DATAMASS SUMMIT | 29-30 September | Gdańsk
Big Data, Data Science, Machine Learning and AI, all in the context of cloud solutions.
Remember about 10% discount with this code: DATAPILL10!
for 2 or more participants – 20% OFF
