
ARTICLES
Apache Arrow: The Future of Data Engineering | 4 min | Data Engineering | Ravish Kumar | Data Engineer Things
In this one, Ravish provides insights into the benefits and applications of Apache Arrow, shedding light on its potential to revolutionize data engineering practices. Let’s delve into how Apache Arrow's columnar memory format is poised to reshape data processing and analytics, enhancing performance, interoperability, and standardization across various systems and languages.
Apache Kafka as Workflow and Orchestration Engine | 16 min | Data Streaming | Kai Waehner | Personal Blog
The blog explores Kafka's role as a workflow engine for automating business processes, noting its reliability. It suggests considering specialized tools for scenarios involving human interaction or complex workflows. Understanding design patterns like SAGA, exploring tools like Camunda, and factoring in microservices and domain-driven design helps in deciding between Kafka and alternatives like Apache Flink for stateful workflows.
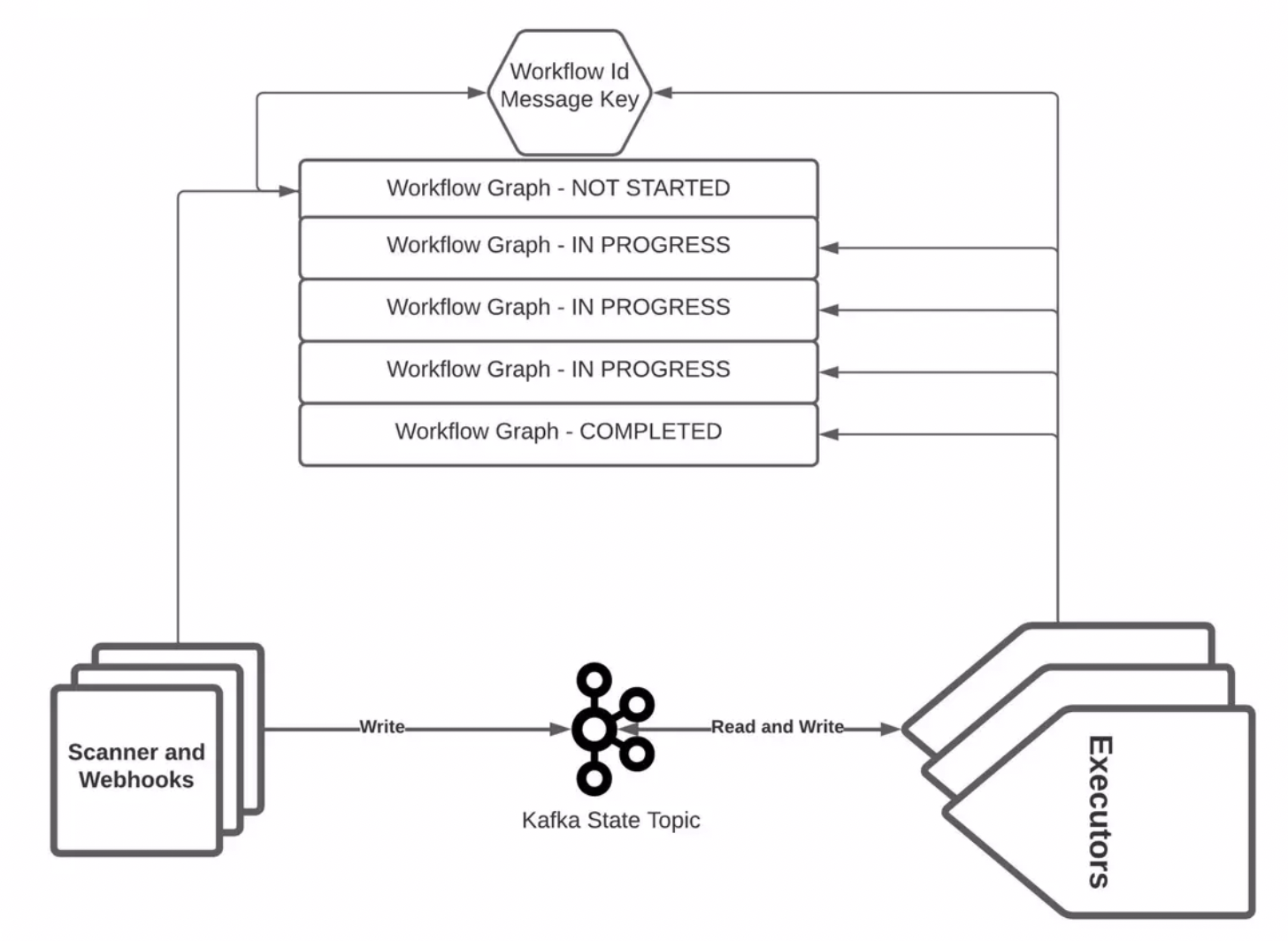
Real-time Machine Learning: considerations based on Fraud Detection use case | 17 min | ML | Michał Madej | GetInData | Part of Xebia Blog
Batch features encompass relatively static information, such as customer demographics and product attributes, while streaming features are derived from real-time data and tied to immediate events like aggregated live actions, social media sentiment analysis and IoT sensor data. This blog post explores the critical role of real-time machine learning in specific contexts, particularly focusing on its significance in areas like fraud detection.
TUTORIALS
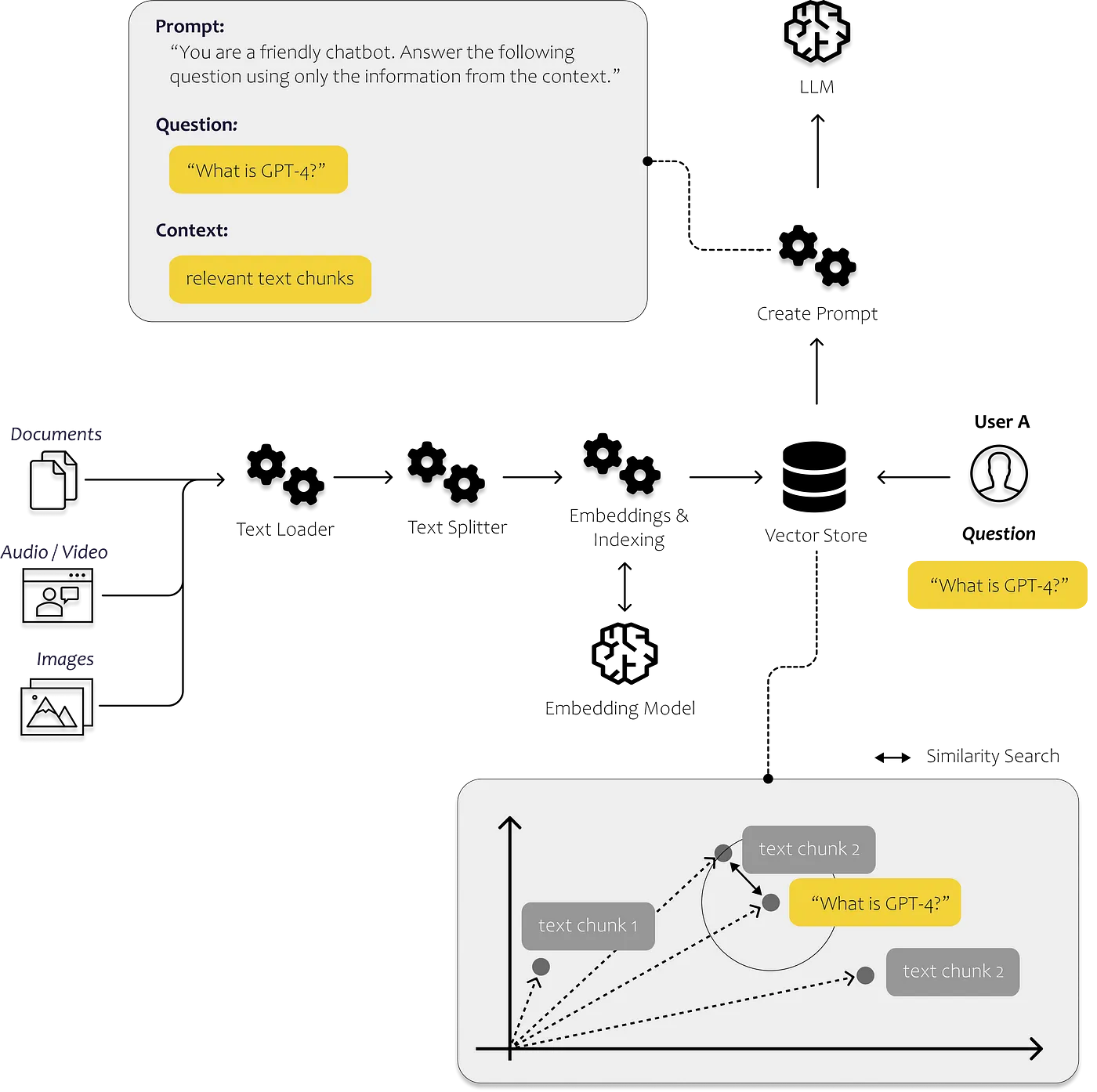
All You Need to Know to Build Your First LLM App | 26 min | LLM | Dominik Polzer | Towards Data Science
Let’s dig into a step-by-step tutorial to Document Loaders, Embeddings, Vector Stores and Prompt Templates. Read and let know more about why we need LLMs, what is LangChain and Fine-Tuning vs. Context Injection comparison.
The tutorial includes:
1. Loading documents using LangChain
2. Splitting Documents into Text Chunks
3. From Text Chunks to Embeddings
4. Define the LLM you want to use
5. Define Prompt Template
6. Creating a Vector Store
Increase query speed with Forward Indexes on JSON columns | 9 min | SQL | Cockroach Blog
This tutorial delves into the innovative use of forward indexes on JSON columns, shedding light on the optimization strategies employed to enhance database performance and query efficiency.
SQL-only LLM for text generation using Vertex AI model in BigQuery | 5 min | LLM | Abirami Sukumaran | Google Cloud Blog
This one shows how to summarize source code from GitHub repos and identify programming languages using Vertex AI's Large Language Model. This model serves as a hosted remote function in BigQuery, utilizing the GitHub Archive Project's dataset of 2.8 million open source repositories available in Google BigQuery Public Datasets.
NEWS
Coming Soon: Confidence — An Experimentation Platform from Spotify | 5 min | Data Engineering | Tyson Singer | Spotify Engineering Blog
Spotify introduces "Confidence," a new commercial product aimed at software development teams. Drawing from over a decade of experience in enabling large-scale experimentation, Confidence simplifies the user testing setup, coordination, analysis and optimization, ensuring rapid idea validation and impactful outcomes. The platform's flexibility and scalability ensure that experimentation becomes an integral component of your organization's practices.
Introducing the dbt adapter for Synapse Data Warehouse in Microsoft Fabric | 6 min | Data Engineering | Mark Pryce-Maher | Microsoft Blog
Microsoft announces the preview of the dbt plugin adapter for the Synapse Data Warehouse in Microsoft Fabric (preview). This data platform-specific adapter plugin allows you to connect and transform data into Synapse Data Warehouse in Microsoft Fabric. This is continuing Microsoft’s focus on integration and partnership with dbt Labs.
DATA ODDITY
Researchers Publish Attack Algorithm for ChatGPT and Other LLMs | AI | Anthony Alford | InfoQ
CMU researchers created LLM Attacks, an algorithm automating adversarial attacks on various large language models (LLMs) like ChatGPT, achieving up to 84% success on GPT-3.5/4, and 66% on PaLM-2. It innovates by automatically crafting prompt suffixes to bypass safety mechanisms, displaying 88% effectiveness on the AdvBench benchmark against Vicuna, outperforming a 25% baseline success rate.
DATA TUBE
Fraud Detection use case by Klarna | 40 min | ML | Vaibhav Singh and Corrie Bartelheimer | AI Guild
Watch a use case in production: “Automated credit risk assessment. How Klarna scales online shopping transactions”. Klarna story, transaction features, feature generation architecture and much more are waiting for you here.
PODCAST
Data Journey with Dainius Kniuksta (Forecast) - Data and AI in the people & project management | 50 min | AI | Host: Adam Kawa Guest: Dainius Kniuksta | Radio DaTa Podcast
Let’s listen to a talk with Dainius Kniuksta that includes:
- Data that is collected and analysed at Forecast e.g. projects, budgets, scope, time and people
- Data & AI-driven use-cases at Forecast e.g. reporting, warnings, similarity of tasks, work anomaly and burnout
- Insights that can be taken from using Forecast related to people management, suitability (80% of accuracy currently), passion and career paths
- Tech, data & the MLOps stack used to develop ML/AI models at Forecast e.g. NLP libraries, Google Bard, AWS, SageMaker, TensorFlow, Amplitude, home-grown solutions
and more.
LLMs on Azure | 1 h 14 min | LLM | Hosts: Michael Berk, Ben Wilson Guest: Jeff Procise | Top End Devs Podcast
Let’s listen to a talk with Jeff Procise, founder of Wintellect, an Azure-focused software consulting company. Expect to learn about your next LLM MVP on Azure, the societal impact of AI, the bifurcation of model size and much more.
CONFS EVENTS AND MEETUPS
Building data-intensive applications with real-time data streaming | Virtual Hands-on Lab | 16th August 11 AM CEST
In today's landscape, businesses can harness extensive data for customer benefit, but numerous enterprises face challenges in readying vast datasets for analysis and delivering immediate insights through real-time data streaming. Explore the realm of crafting data applications with real-time data streaming by participating in Snowflake’s complimentary, instructor-led hands-on lab.
You will learn how to:
- ingest near real-time data sets into Snowflake
- create Kafka producer and consumer apps
- integrate Snowpipe streaming SDK with Kafka consumer apps
- populate Snowflake tables with time-series data in JSON format
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
