
ARTICLES
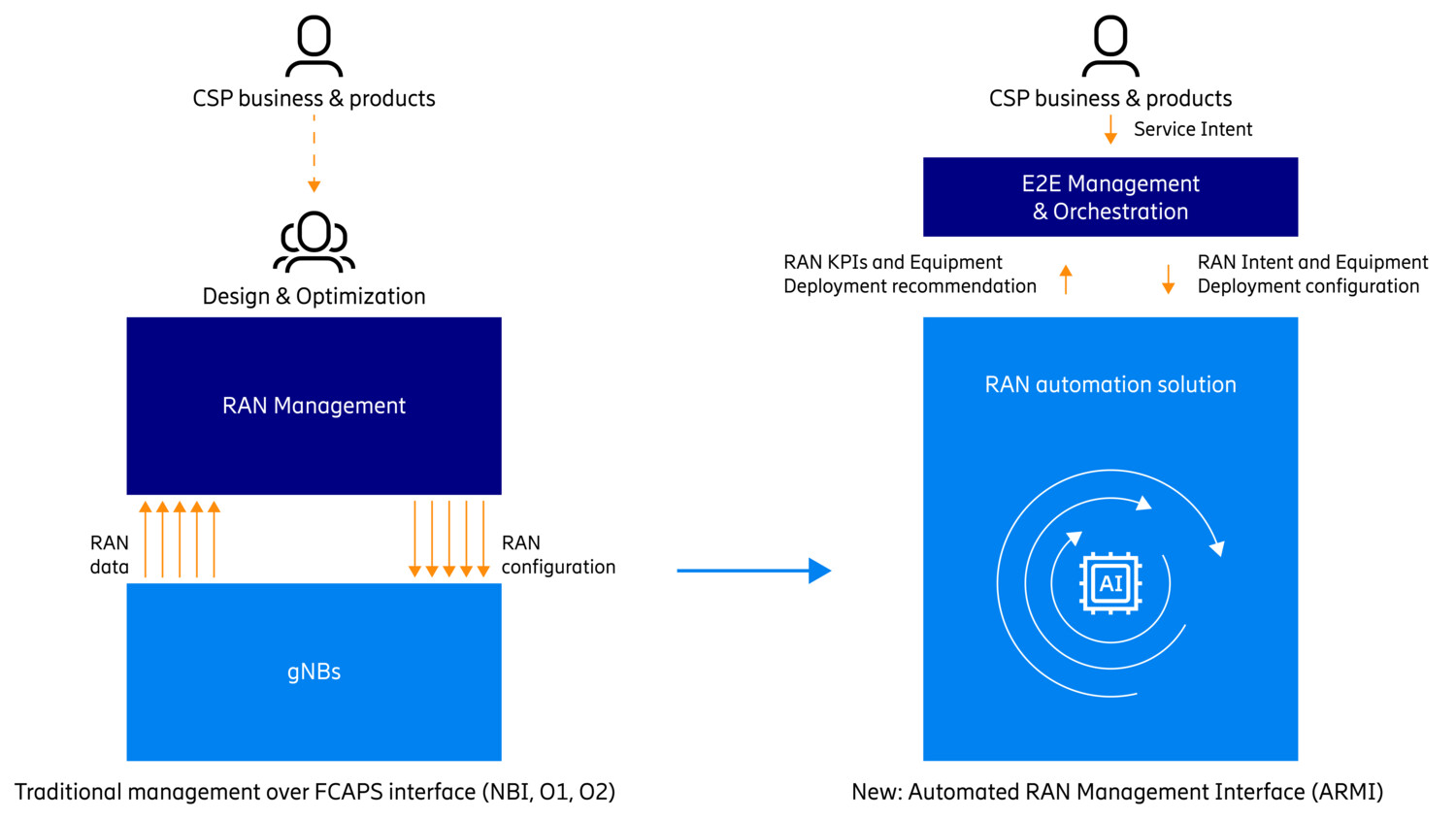
How to leverage intent-based automation with AI/ML for 5G RAN | 8 min | AI/ML | Ayodele Damola, Mathias Sintorn, Ajay Gautam | Ericsson Blog
The journey toward a Zero-touch network parallels the evolution from cars to self-driving vehicles. In the context of 5G complexities, automating Radio Access Networks (RANs) becomes vital. Intent-based Automation in RANs is pivotal in refining operations, boosting network performance, and enabling innovative services. This approach is a pioneer for achieving a Zero-touch network, revolutionizing network management and introducing new service offerings.
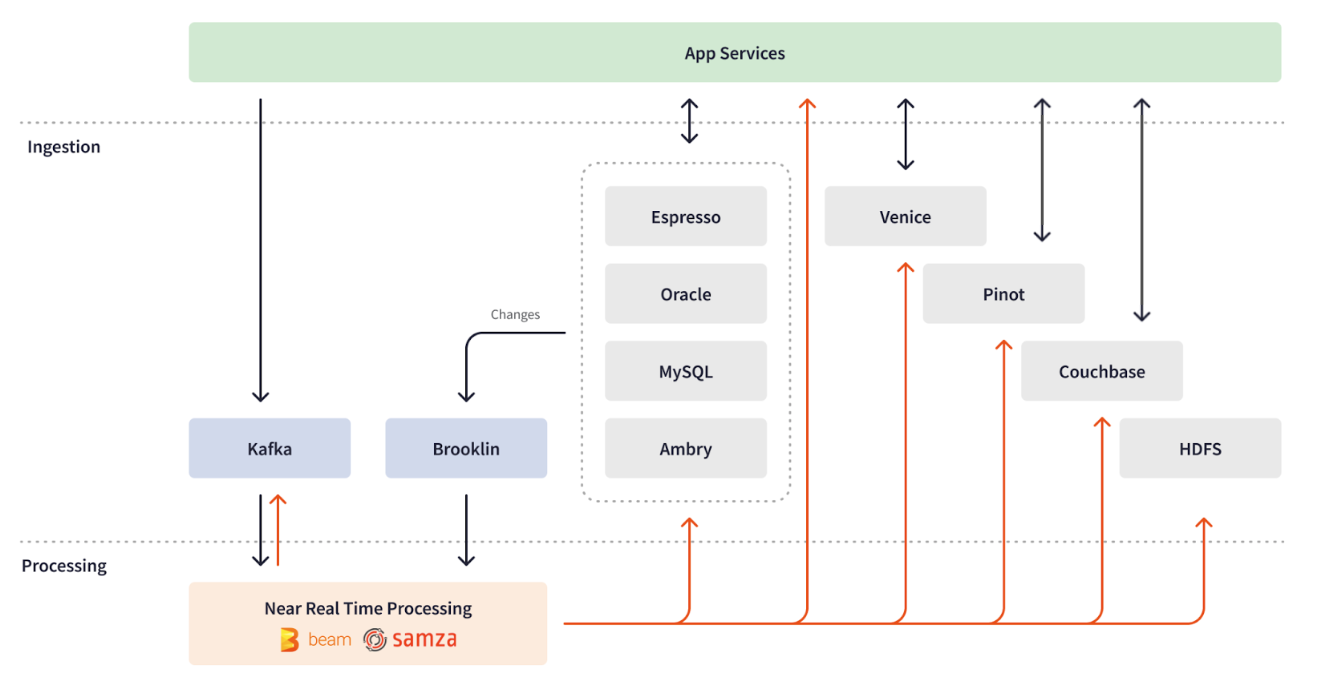
Revolutionizing Real-Time Streaming Processing: 4 Trillion Events Daily at LinkedIn | 7 min | Real-Time Streaming | Bingfeng Xia, Xinyu Liu | LinkedIn Engineering Blog
LinkedIn relies heavily on Apache Beam to process over 4 trillion events daily through thousands of pipelines, enabling real-time data processing across crucial services for their 950 million members. The case study details how Apache Beam's unified framework has significantly impacted streaming processing, reducing latency, optimizing costs, enabling real-time ML feature generation, improving user experiences through personalized services and improving abuse detection.
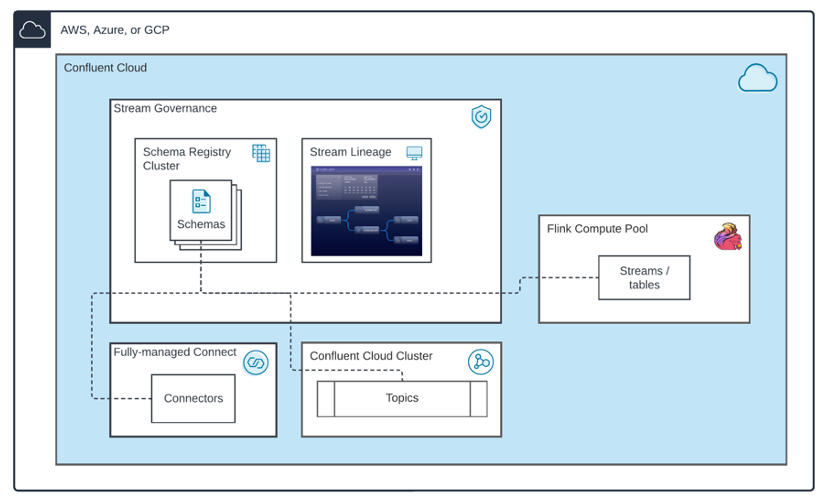
The Future of Business Analytics: Artificial Intelligence and Data Streaming | 10 min | AI | Zach Hamilton | Confluent Blog
In this blog, you’ll get to discover some of the problems, challenges and solutions facing the field of AI/ML-driven business analytics, focused on what is at its core—data. You’ll walk away with a better understanding of what you’re up against when it comes to doing real-time business analytics with AI/ML, optimizing your data infrastructure, and preparing analyst teams and technologies to use the highest quality data for the job.
How we reduced our docker build times by 40% | 5 min | Data Engineering | Niels Claeys | datamindedbe
This blog post delves into strategies for accelerating CI pipelines and improving Docker build times. It showcases two impactful changes: storing build cache information remotely and utilizing the link option while adding and copying files into Docker images, ultimately leading to a 40% reduction in overall build times.

TUTORIALS
Using undocumented AWS APIs | 6 min | Cloud | Jacco Kulman | Xebia Tech Blog
Discover how Jacco developed an 80-line Python code to automate the process, providing comprehensive insights into services, actions and more for policy validation and potential tool development.
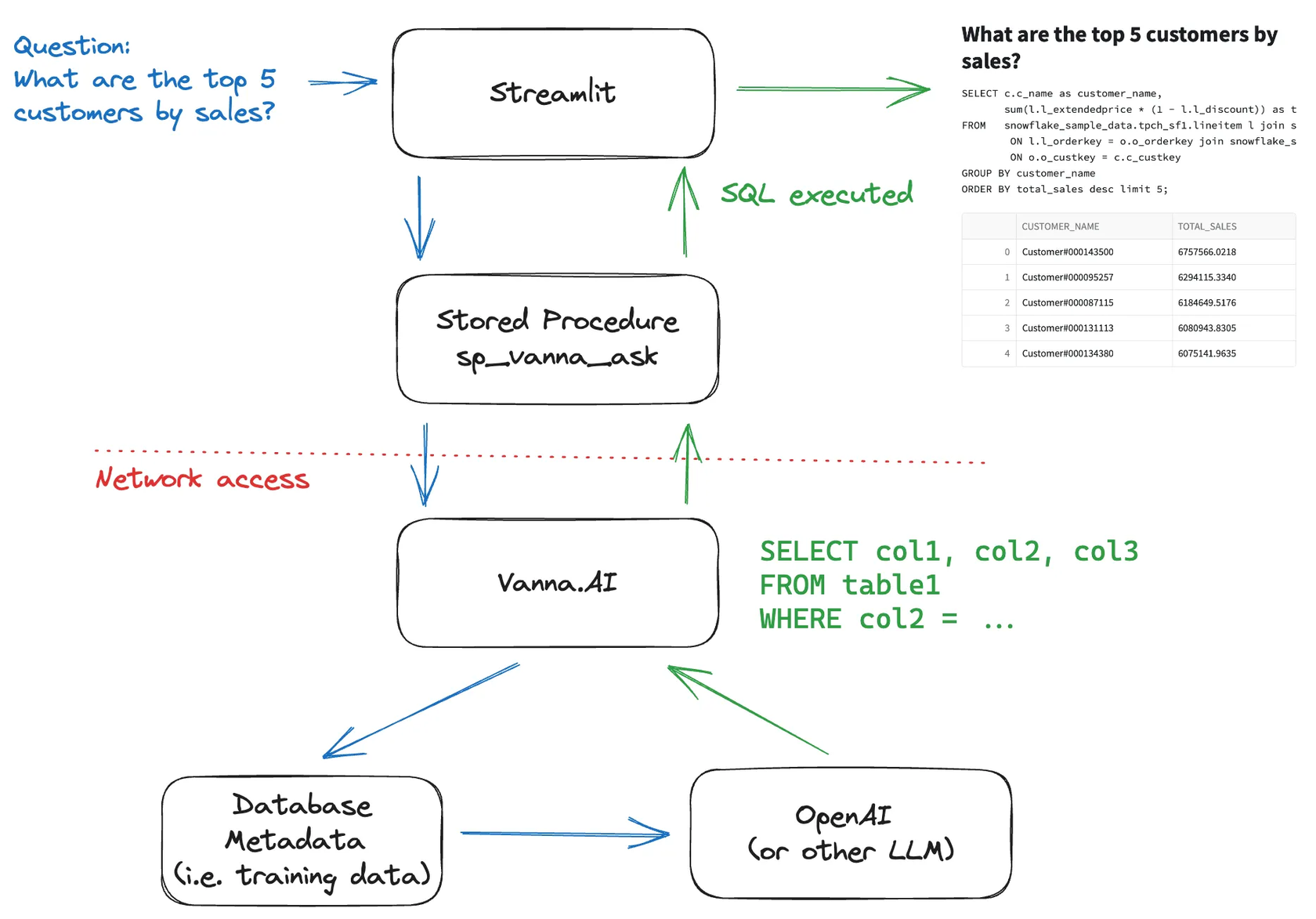
Using Snowflake + Snowpark + Streamlit + Vanna AI to chat with your database | 5 min | Data Engineering | Zain Hoda | Personal Blog
This tutorial will show you how to use Snowpark Stored Procedures to let you chat with your Snowflake data using Snowflake’s new built-in Streamlit integration.
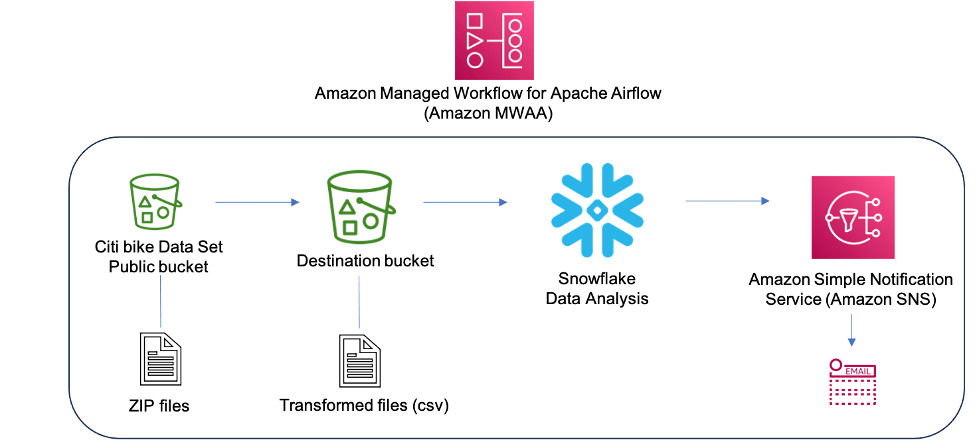
Use Snowflake with Amazon MWAA to orchestrate data pipelines | 7 min | Data Engineering | Payal Singh, Manuj Arora, James Sun, Bosco Albuquerque | AWS Tech Blog
Read an overview of orchestrating a data pipeline by employing Snowflake operators within an Amazon MWAA environment. It outlines the necessary steps to establish integration between Amazon MWAA and Snowflake. The solution presents an automated, comprehensive workflow, encompassing data ingestion, transformation, analytics and consumption.
NEWS
Lakehouse Monitoring | 3 min | Data Engineering | Databricks
Databricks Lakehouse Monitoring allows teams to oversee their entire data pipelines, from data and features to ML models, all without needing extra tools. Using Unity Catalog, it ensures data and AI assets are high-quality, accurate and dependable by providing detailed insights into their lineage.
TOOLS
K9s |Data Engineering
K9s is a terminal based UI designed to interact with your Kubernetes clusters. The aim of this project is to make it easier to navigate, observe and manage your deployed applications in the wild. K9s continually watches Kubernetes for changes and offers subsequent commands to interact with your observed resources.
Kor | Data Engineering
Kor is a tool to discover unused Kubernetes resources. Currently, Kor can identify and list unused:and more.
- ConfigMaps
- Secrets
- Services
- ServiceAccounts
- Deployments
DATA TUBE
Next-generation data analytics with BigQuery and PaLM | 38 min | LLM | Chris Crosbie, Seamus Abshere | Google Cloud Tech
Learn about BigQuery's built-in machine learning capabilities and how to use Vertex AI's LLMs directly within BigQuery. You'll see how these tools make tasks like sentiment analysis and entity extraction easier. Plus, there'll be a live demo showing how Faraday uses these powerful models in BigQuery to predict customer behavior.
PODCAST
Data, engineering and analytics at Pleo | 27 min | Data Engineering | Adam Kawa, Agnieszka Bomersbach | Radio DaTa Podcast
Topics that we talk about include:and more…
- What Pleo is, who uses it and how it works
- How data is collected and utilized by Pleo
- Pleo's data tech stack, Including GCP, BigQuery, Kafka, Metabase and Looker
- Pleo's approach to Generative AI
- Differences in working with data at Pleo, Acast, and Skyscanner
CONFS EVENTS AND MEETUPS
Big Data Technology Warsaw Summit 2024 | Call For Papers | 10th-11th April 2024
We invite you to go through the process of speaking proposal submission – you will find the necessary details in the link. The 10th edition of the Big Data Technology Warsaw Summit takes place on 10th-11th April 2024. More than 500 professionals will attend the conference to listen to technical presentations given by dozens of speakers from top data-driven companies.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
