
ARTICLES
Operating Flink Is Hard: What does this really mean? And how to go about it? | Data Processing | 10 min | Sharon Xie | Decodable Blog
Why Flink stream jobs require microservice‑style discipline - capacity planning, checkpoint health, backpressure, ownership by multiple teams - and offers best practices for metrics, staging, and monitoring to manage complexity.
Preventing Revenue Loss With Real-Time A/B Test Monitoring | Streaming | 15 min | Lukasz Krawiec | Expedia Group Technology - Engineering Blog
How Expedia uses real-time A/B test monitoring with Apache Flink to detect anomalies early, preventing revenue loss and improving experiment reliability.
Is dbt Fusion the death of dbt Core? | 5 min | Platform Engineering | Toby Mao, Andrew Madson | Tabico Cloud Blog
Is dbt Core dead? What ‘source available’ really means, why dbt Labs’ shifting to Fusion, and how it marks the end of dbt’s open source innovation.
Stanford’s lecture on building AI agents in a 28-point summary | 8 min | AI | Aadit Sheth
1/ Chain-of-thought prompting works because it slows down the model’s reasoning. Slower = smarter.
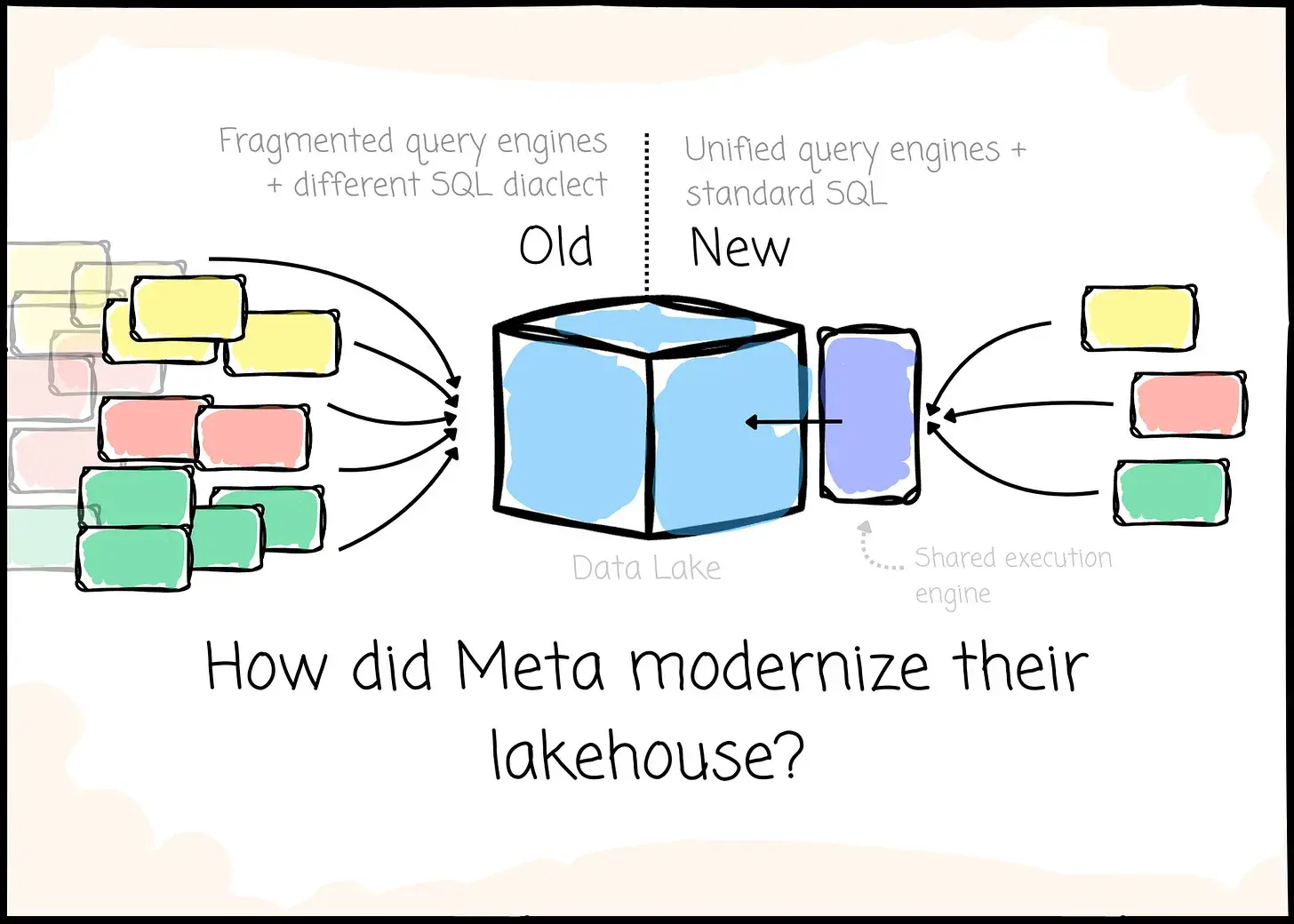
How did Meta modernize their lakehouse? | 10 min | Lakehouse | Vu Trinh | Data Engineer Things Blog
How Meta’s initial approach caused them troubles and their effort to fix them at the organizational scale.
TUTORIALS
Dimensional Data Modeling with Databricks | 15 min | Lakehouse Architecture | Mariusz Kujawski| Personal Blog
A practical guide to dimensional data modeling in Databricks using Delta Lake, Unity Catalog, and Delta Live Tables to build scalable, BI-ready star schemas and fact/dimension tables.
Centralized Monitoring for Data Pipelines: Combining Azure Data Factory Diagnostics with Databricks System Tables | 7 min | Data Architecture | Rik Adegeest | Xebia Blog
How to bridge that gap by combining ADF diagnostic settings with Databricks system tables. How to create a centralized overview to analyze the amount of data ingested and the end-to-end runtime for a specific use case.
NEWS
Collibra acquires data access startup Raito | 3 min | Data Governance | Rebecca Szkutak | TechCrunch Blog
TOOLS
Apache Flink MQTT Source Connector | 3 min | Streaming | George Leonard | Personal Blog
Enabling real-time ingestion of IoT data streams into Flink pipelines using Eclipse Paho.

Launching: The Boring Semantic Layer | 7 min | Data Engineering | Julien Hurault | Ju Data Engineering Newsletter
Introduces a lightweight Python semantic layer built on Ibis, designed for simplicity and version control.
PINNACLE PICKS
Your last week top picks:
Apache Polaris™ (incubating) Now Supports 3X Concurrent Transactions with New Relational JDBC Persistence Layer | 3 min | Data Infrastructure | Prashant Singh | Snowflake Builders Blog
Polaris now supports more parallel transactions with lower latency, thanks to a refactored JDBC-backed persistence layer.
How Nexthink built real-time alerts with Amazon Managed Service for Apache Flink | 10 min | Streaming Architecture | Nikos Tragaras, Raphaël Afanyan, Lorenzo Nicora, Simone Pomata, and Subham Rakshit | AWS Blog
From database polling to event-time alerting, Nexthink explains how they rebuilt monitoring with Apache Flink on AWS.
How Kafka Saved Our Payment System And Helped Us Scale to 10 Million Users | 5 min | System Design | Himanshu Singour | Personal Blog
A fragile payment flow became a scalable, event-driven architecture using Kafka. One topic, many consumers, instant results.
____________________
Have any interesting content to share in the DATA Pill newsletter?
