ARTICLES
How Discord stores trillions of messages | 10 min | Data Engineering | Bo Ingram | Discord Blog
In 2017 the Discord team shared their experience with storing billions of messages. After 5 years it is time for an update. Read the story on how the Discord team changed their data as they matured, what troubles they faced and how they solved them.
What are Graph Neural Networks and why should you consider using them in your Recommendation System? | 20 min | ML | Michał Stawikowski | GetInData | Part of Xebia Blog
As businesses strive to provide personalized experiences to their customers, recommendation systems play a crucial role. However, traditional recommendation systems have limitations when it comes to handling complex relationships between users and items. This is where GNNs come in. Graph Neural Networks are part of an extremely active and rapidly growing field of research. They are representatives of one of the most powerful groups of machine learning algorithms, which are Artificial Neural Networks. Let’s explore the potential of Graph Neural Networks (GNNs) in improving recommendation systems.
Prioritizing Home Attributes Based on Guest Interest | 7 min | ML | Joy Jing | Airbnb Tech Blog
How Airbnb leverages ML to derive guest interest from unstructured text data and provide personalized recommendations to Hosts. They do this through a scalable, platformized, and data-driven engineering system. This blog post describes the science and engineering behind the system.
High-Performance Data Teams Don’t Care About Data Quality | 11 min | Data Science | Sven Balnojan | Personal Blog
It turns out that high-performing data teams should not try to “increase data quality”, but increase the speed and the quality of their work — at the same time. 9 good practices to help your data team increase their performance are ready to be read.
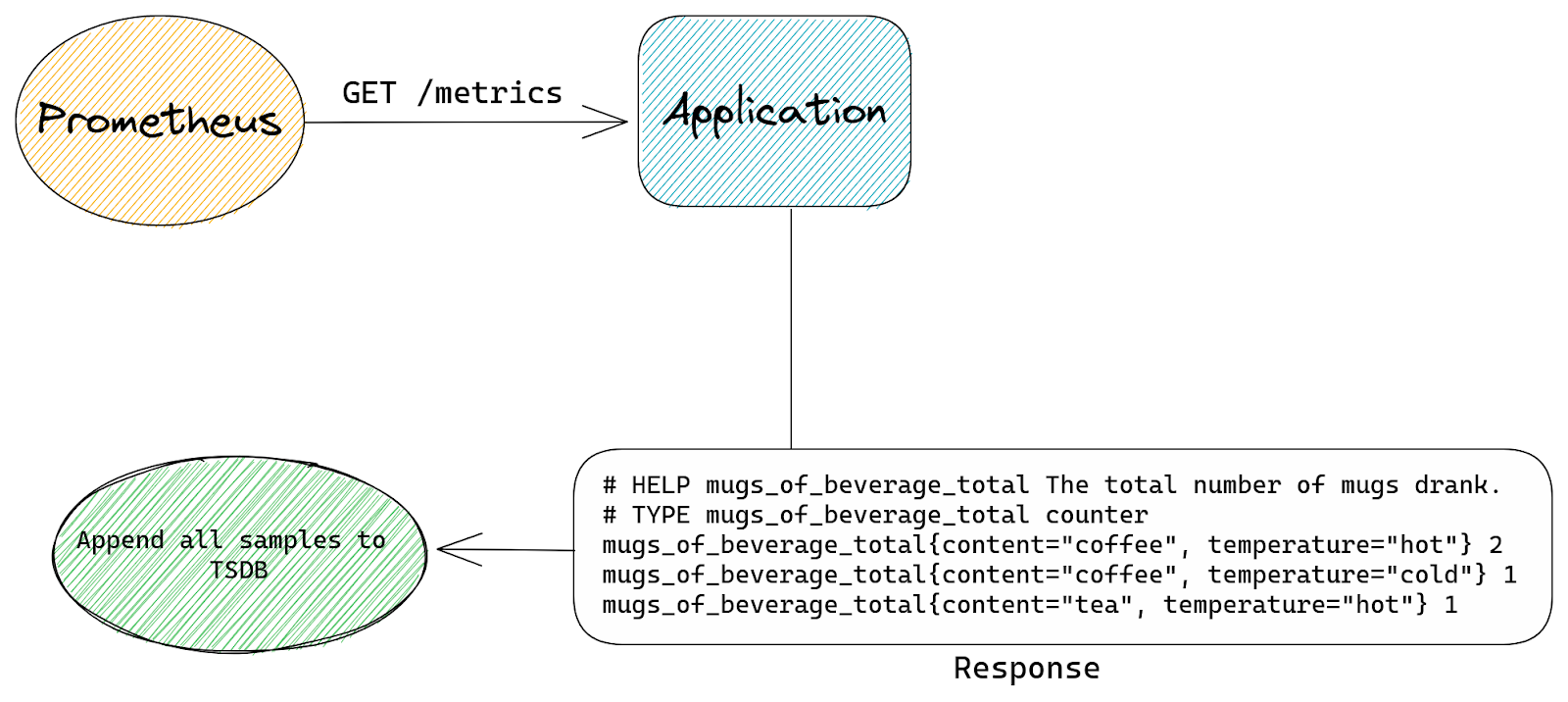
How Cloudflare runs Prometheus at scale | 23 min | Data Engineering | Łukasz Mierzwa | Cloudflare Blog
Let’s cover some of the issues one might encounter when trying to collect many millions of time series per Prometheus instance with Łukasz. Learn how Prometheus uses memory in six steps:
- HTTP scrape
- new time series or an update?
- appending to TSDB
- memory-mapping old chunks
- writing blocks to disk
- garbage collection
…and way way more is waiting for you.
The Future of Data is Real-Time | 5 min | Data Engineering | Eric Sammer | Data Science Central Blog
If your organization is already feeling pressure to deliver analytics faster and faster to support real-time use cases, be prepared for that pressure to only increase over time. Start thinking now about how your transition to real-time data stacks can support your data teams, with tools designed for the job at hand and read more about Eric’s point of view on this situation.
Kubernetes Infrastructure At Medium | 5 min | Kubernetes | Eddie Barth | Medium Engineering Blog
Kubernetes has a ton of complexity, and has an unlimited number of possible configurations based on an organization’s needs. Dig into how Medium use Kubernetes to manage micro-services.
TUTORIAL
Running dbt on Google Cloud’s Vertex AI Pipelines | 7 min | Cloud | datatonic Blog
How can you use Vertex AI and dbt in an efficient and cost-effective way to orchestrate Machine Learning workloads? The 4 steps dbt on Vertex AI Pipelines tutorial explains it in an easy way.
How to create and deploy an AWS CloudFormation custom provider in less than 5 minutes | 8 min | Cloud | Mark van Holsteijn | Xebia Blog
Learn how to create and deploy an AWS CloudFormation custom provider in less than 5 minutes using a Python copier template. This blog post with a tutorial and copier template has everything you need to quickly build, deploy and maintain a new custom AWS CloudFormation Provider.
NEWS
Introducing Webhooks in dbt Cloud | 3 min | Cloud | Jeremy Hutt | dbt Blog
Announcement about how dbt made it possible for dbt Cloud to notify other applications and tools when certain events take place in dbt Cloud, through outbound webhooks.
Debezium 2.2.0.Alpha3 Released | 3 min | SQL | Chris Cranford | Debezium Blog
Debezium is pleased to announce the third alpha release in the 2.2 release stream, Debezium 2.2.0.Alpha3. It includes a plethora of bug fixes, improvements, breaking changes and a number of new features including, but not limited to, optional parallel snapshots, server-side MongoDB change stream filtering, surrogate keys for incremental snapshots, a new Cassandra connector for Cassandra Enterprise and much more.
TOOLS
Spark-testing-base | Apache Spark | Holden Karau
A cool testing library for Apache Spark apps. It comes with a bunch of tools and test fixtures that help you write unit tests for Spark Streaming and SQL apps. It’s available on GitHub and works with popular testing frameworks like JUnit and ScalaTest.
VIDEO
Machine Learning (ML) Framework | 5 min | Data Science & ML | Borys Sobiegraj | GetInData | Part of Xebia
The GetInData ML Framework is a set of complete blueprints for solving typical machine learning problems. It is an open-source project designed to help data scientists and machine learning engineers streamline their workflow with reusable building blocks, best practices and guidelines. In this short demo, Borys demonstrates f. eg. how Kedro can help Data Science teams.
PODCAST
How to Build Data and ML Products Users Love | 36 min | ML | Host: Jon Krohn Guest: Brian T. O’Neill | Super Data Science
In this one, you will learn a lesson from Brian, who says that teams will have to answer the question "what is the value that we're here to provide?" before adding that teams must begin by answering the right questions.
Senior stakeholders often bring forth problems and suggestions, but it's data scientists who must begin by asking the right questions to create effective solutions. In an ideal world, a Data Product Manager would bridge the gap between both sides to facilitate communication and problem-solving.
Check out further insights on this topic.
CONFS EVENTS AND MEETUPS
Upgrade your Scaleup from using Spreadsheets to Data Platform | 14th March 2023 | Online
Do you want to know how to increase your data capabilities and become a data-driven company? Join the first webinar in the series ‘Building a Data-Driven Company’ and learn what an implemented Modern Data Platform can look like and how it can assist you during your journey into modern analytics.
PetSmart Drives Personalization With Customer 360 on Databricks | March 16, 2023 9am PT / 12pm ET | Online
Maximize your efficiency, delight your customers and drive your retail business to new levels of performance. The Databricks Lakehouse for Retail is designed to help businesses like yours handle data, analytics and AI on one platform. Learn how PetSmart has unified data, analytics and AI on Databricks to build personalized experiences.
You’ll find out how:
- Databricks helps you empower your employees to collaborate in real time and build personalized experiences
- PetSmart is building a Customer 360 on Databricks to power meaningful customer engagements at scale
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill