
ARTICLES
3 years managing Kubernetes clusters, my 10 lessons | 4 min | DevOps| Herve Khg | Personal Blog
Embarking on a three-year journey managing Kubernetes clusters, Hevre shares critical lessons on infrastructure, deployment optimization, scalability, and security. Read the insights tailored for newcomers and seasoned Kubernetes experts cultivated from three years of experience.
From analytics to actual application: the case of Customer Lifetime Value | 9 min | Data Analytics | Katherine Munro | Towards Data Science Blog
This blog covers:
- What is CLV?
- Do you really need CLV prediction? Or can you start with historic CLV calculation?
- What can your company already gain from historic CLV information, especially when you combine it with other business data?

Four ways generative AI is set to transform the telecom industry | 7 min | AI | Athanasios Karapantelakis, Pegah Alizadeh, Abdulrahman Alabbasi, Kaushik Dey, Alexandros Nikou, Fitsum Gaim Gebre | Ericsson Blog
This article delves into the concept of generative AI, shedding light on its ability to create new content and its impact on various industries, with a spotlight on the success of OpenAI's ChatGPT. The focus is on understanding how generative AI might change the telecom industry, providing insights into its applications, such as generating content in forms understandable by humans and machines, exploring semantic communication, and facilitating the creation of digital twins more straightforwardly.
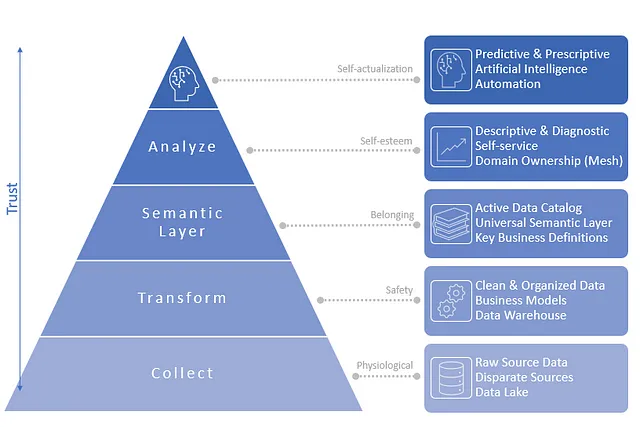
Self-Service Data Analytics as a Hierarchy of Needs | 15 min | Data Analytics | Andrew Taft | Towards Data Science Blog
Delve into the history and struggles of self-service business intelligence tools, noting a gap between expectations and actual use. It introduces a "Self-Service Hierarchy of Needs," outlining critical stages for successful self-service data analytics. Read more about core elements. It offers a straightforward six-step approach to building a data-driven organization and improving self-service.
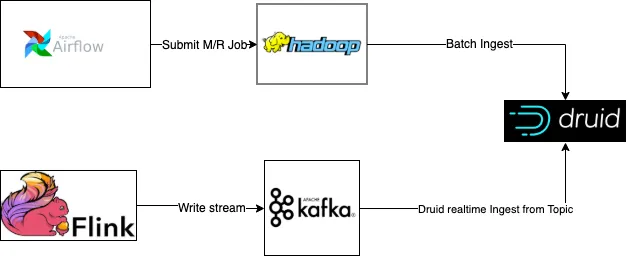
Druid Deprecation and ClickHouse Adoption at Lyft | 12 min | Data Platform | Ritesh Varyani, Jeana Choi | Lyft Engineering Blog
This post takes you through Lyft's Apache Druid journey, spotlighting its role in geospatial querying and managing time-series data. It then unfolds the natural progression towards adopting ClickHouse as the go-to sub-second analytic system, addressing challenges and shaping Lyft's dynamic data infrastructure.
TUTORIALS
What does it take to let ChatGPT manage my Todoist tasks? | 7 min | AI | Jordi Smit | Xebia Blog
Jordi created an LLM agent that can autonomously perform actions in Todoist. The agent uses REACT's prompting technique to communicate with the user and complete tasks. This tutorial discusses how to handle edge cases and mistakes made by the LLM.
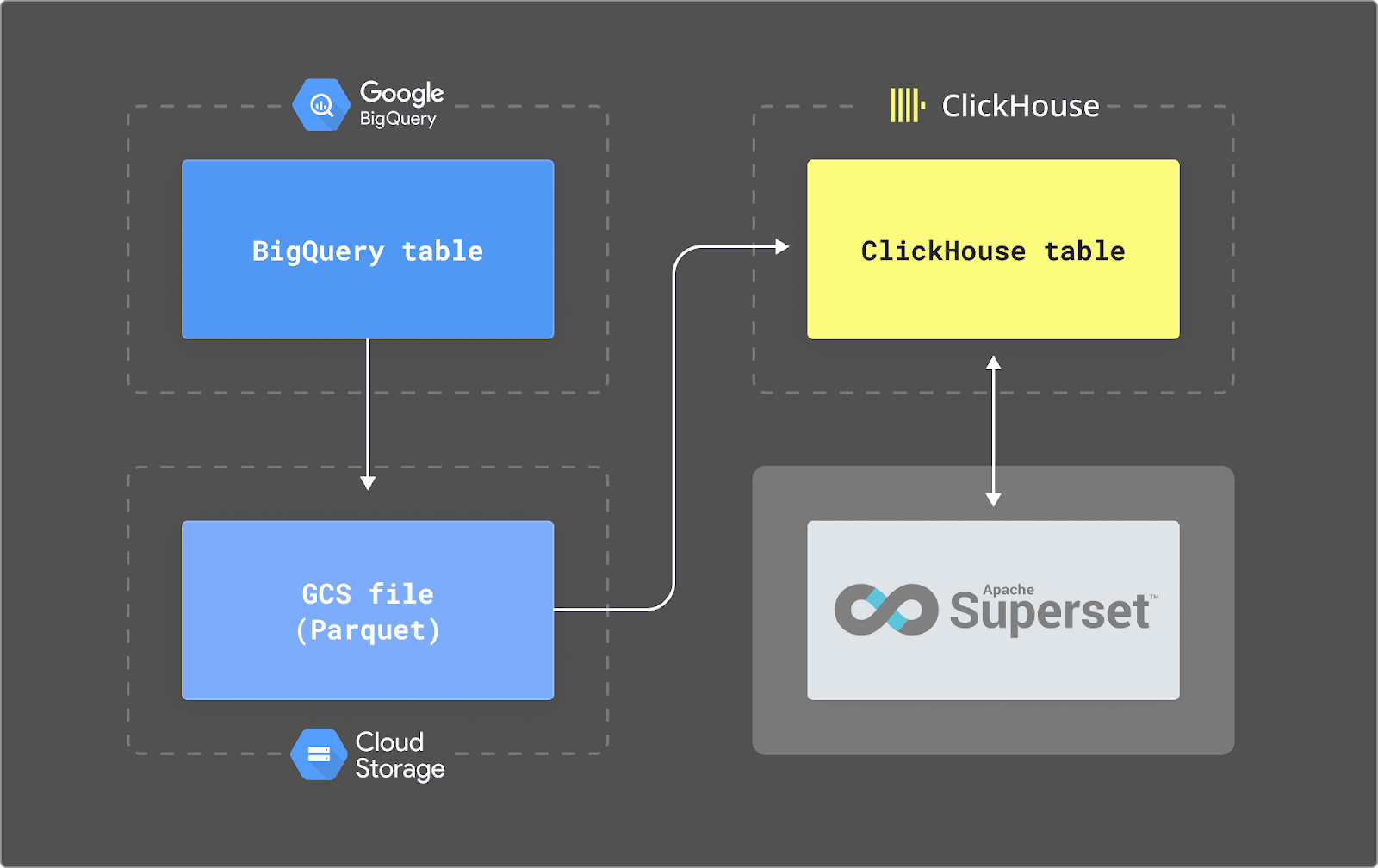
Enhancing Google Analytics Data with ClickHouse | 12 min | Data Analytics | ClickHouse Blog
Fellow data enthusiasts can use the architecture described in this blog post to build their high-performance Google Analytics using ClickHouse and a few lines of SQL. This cost-effective solution can be implemented for less than $20 per month using ClickHouse Cloud.
Personalized AI Search with Vector Embeddings for Semantic Profiles | 12 min | AI | Matthias Broecheler | DataSQRL Blog
This article delves into the complexities of sorting search results using semantic context drawn from user interactions. It showcases how recent advancements in large-language models empower machines to calculate semantic similarities accurately. The step-by-step guide navigates the development of a personalized shopping search using semantic vector embeddings, providing a practical methodology applicable to various search scenarios beyond e-commerce.
NEWS
Introducing Llama Packs | 4 min | LLM | Jerry Liu | LlamaIndex Blog
This paper addresses the challenge of improving demand forecasting in retail by integrating Graph Neural Networks into a DeepAR model. The authors propose a novel approach that builds graphs based on article attribute similarity, developing the modeling of relationships between articles without relying on a pre-defined graph structure.
TOOL
BigFunctions | Data Engineering
BigFunctions is:
- a framework to build a governed catalog of powerful BigQuery functions at YOUR company.
- 100+ open-source functions to supercharge BigQuery that you can call directly (no install) or redeploy in YOUR catalog.
DATA TUBE
Solara: A Pure Python, React-style Framework for Scaling Your Data Apps | 26 min | Data Engineering | Maarten Breddels | EuroSciPy
This presentation explores Solara's design principles, showcases its potential through case studies and live examples, and offers resources for integrating Solara into various projects. Whether you're a researcher creating interactive visualizations or a data scientist developing complex web applications, Solara offers an effective Python-centric solution for scaling projects.
PODCAST
Cracking the Code: Machine Learning Made Understandable | 1 h 28 min | Machine Learning | Alexey Grigorev, Christoph Molnar | DataTalks Club
Listen to talk about:
- Christoph’s background
- Kaggle and other competitions
- How Christoph became interested in interpretable machine learning
- Interpretability vs Accuracy
- Christoph’s current competition engagement
- Explainable AI vs Interpretable AI
- Christoph’s other engagements and how to stay hands-on
- Advice for those who want to be technical writers
CONFS EVENTS AND MEETUPS
Best Practices for Data Engineering and Data Science in Snowflake | Webinar | 13th December
This webinar will give you a brief understanding of the essential challenges to measuring, managing and discussing business problems across the organization layers and the key to overcoming them.
What we will discuss:
- Challenges in independently accessing data analysis by decision-makers
- What is a data model? And why it matters
- Why the generation of SQL is not enough to achieve value from data
- Looker and data model management
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
