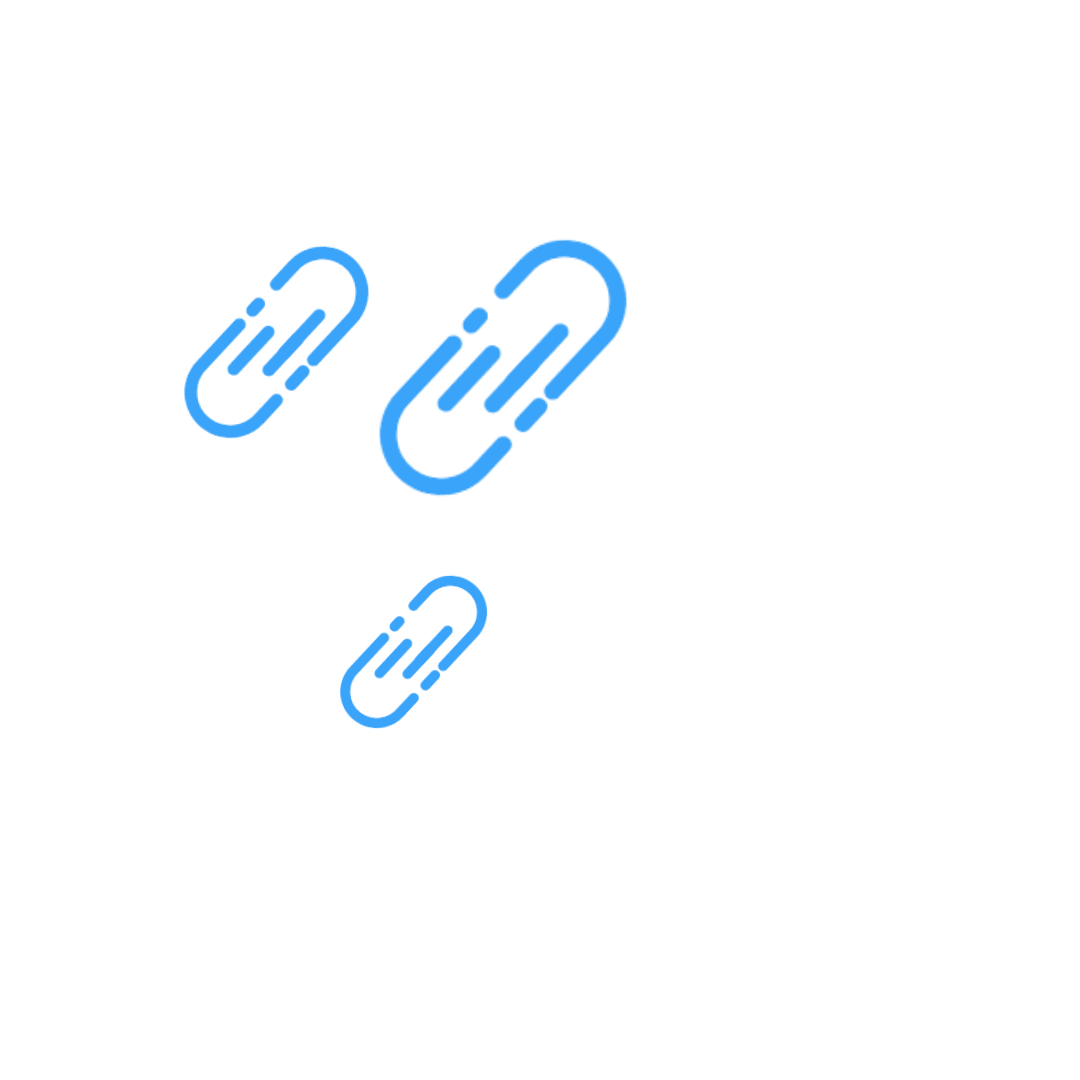ARTICLES
A standardised, scalable way for sharing data in real-time | 5 min read | Data Science | Michael Loh | Virgin Media O2 Blog
While working to centralise all of their data in the cloud, the Virgin Media O2 team had a problem with providing a standardised, streamlined way for stakeholders to access this data in real-time. Now they are working on a data ingestion framework that unifies operational and analytical pipelines while handling the real-time events and batch ingestion method. In this article you will find the architecture of this solution and a description of the analytical pipeline.
Lessons learned after 1 year with dbt. | 7 min read | dbt | Wei Jian | Personal Blog
An interesting read on some of the lessons learned with dbt - especially regarding the conscious management of technical debt. It seems like it's not too hard to make a mess when scaling up...
Challenges and practical lessons from building a deep-learning-based ads CTR prediction model | 10 min read | Deep Learning | Ruoyan Wang, Sirou Zhu, Chengming Jiang | LinkedIn Blog
At LinkedIn, the model for predicting CTR was changed for a model with a deep learning-based system. Here’s how it was done, the architecture behind it and how it brought large relevance lifts (+8.5% CTR). Lessons shared with the LinkedIn team:
- using embedding as features vs end-to-end deep model serving
- ways to achieve an hourly model retraining frequency.
An Analytic Engineer’s Honest Review of Airbyte | 8 min | Data Analytic | Madison Schott | Geek Culture
Madison shares how she set up the first Airbyte connector, ingesting raw data from Mailchimp into Snowflake. A few observations:
- Setting up Airbyte on your localhost using Docker Compose is a pain.
- Figuring out the permissions for tools that connect to Snowflake can be tricky. You need to make sure you give the AIRBYTE_USER the correct role and all the permissions in that role.
- Airbyte has the option of scheduling your data syncs.
- After clicking “sync now”, it can be helpful to read through the logs as the data is uploading to ensure everything is going as expected. This is also a great feature in case something goes wrong. Logs make it easy to pinpoint the exact error.
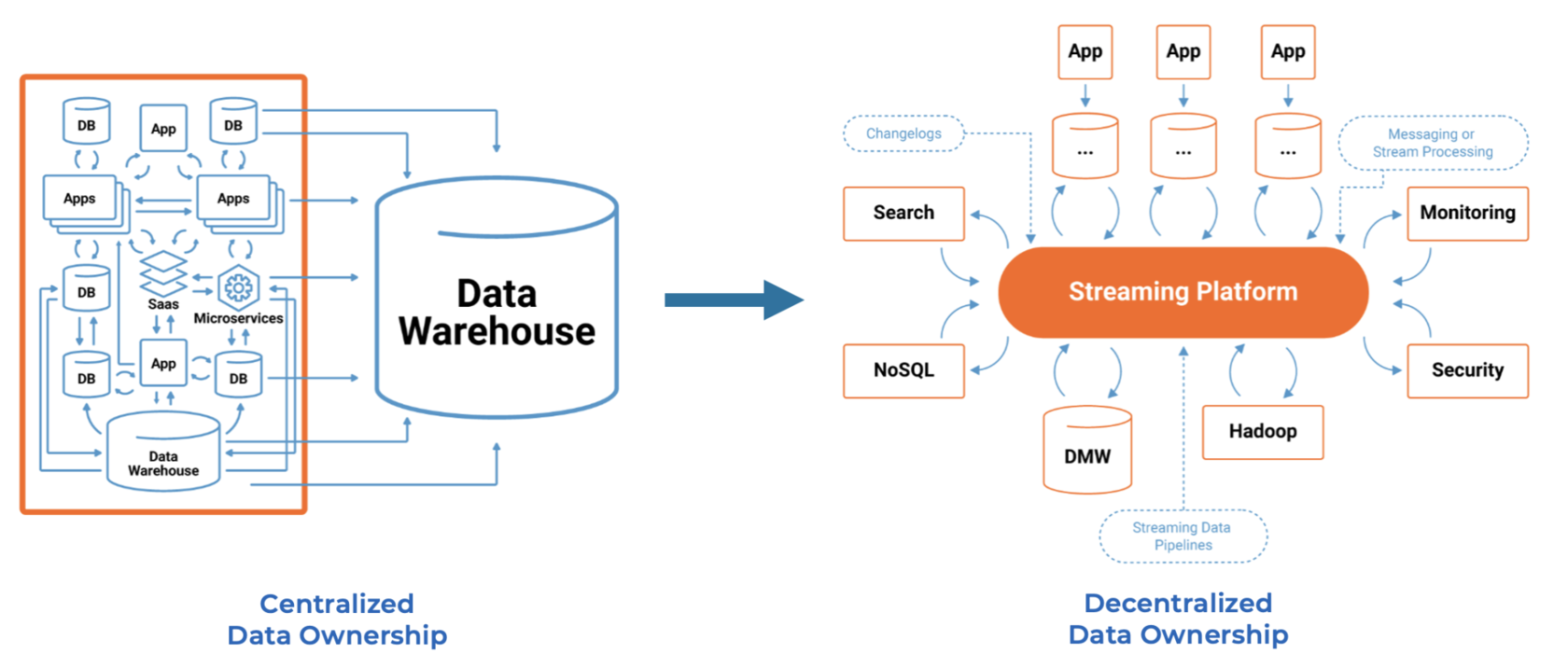
Data Warehouse vs. Data Lake vs. Data Streaming — Friends, Enemies, Frenemies? | 10 min | Data Architecture | Kai Waehner | Personal Blog
A few takeaways:
- A data warehouse is excellent for reporting and business intelligence.
- A data lake is perfect for big data analytics and AI/Machine Learning.
- Data streaming enables real-time use cases.
- A decentralized, flexible enterprise architecture is required to build a modern data stack around microservices and data mesh.
Amazon Launches What-If Analyses for Machine Learning Forecasting Service Amazon Forecast | 2 min read | ML | Daniel Dominguez | infoQ Blog
Amazon is announcing that now its time-series machine learning based forecasting service Amazon Forecast, can run what-if assessments to determine how different business scenarios can affect demand estimates. (...) It can be easily imported into common business and supply chain applications, such as the SAP and Oracle Supply Chain. This makes it easy to integrate more accurate forecasting into the existing business processes with little to no change.
NEWS
Introducing Velox: An open source unified execution engine | 10 min read | Pedro Pedreira, Masha Basmanova, Orri Erling | Meta Blog
Facebook has released Velox: an abstracted, unified, implemented in C++ (FTW!) execution engine that accelerates the query execution of Presto, Spark, PyTorch and possibly other systems. They have just made the general announcement, but the system has been public since Dec 2021.
Announcing General Availability of Delta Sharing | Databricks Blog
So, on 26 August, Databricks announced the General Availability (GA) of Delta Sharing on AWS and Azure.
By announcing this release, Databricks proclaims the highest level of stability, support and enterprise readiness from Databricks for mission-critical workloads on the Databricks Lakehouse Platform.
TOOLS & TECHNOLOGIES
Databricks Feature Store | 2 min read | MLOps | Databricks
When you create a feature table with the Databricks Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs and endpoints that use the feature.
Why Snowflake Data Cloud over Lakehouse architecture | 8 min | Cloud | Umesh Patel | CodeX Blog
Snowflake Data Cloud gives you the option of deploying Lakehouse architecture, along with Data Mesh and other popular architecture. Lakehouse architecture is a subset of the Snowflake Data Cloud.
DATA ODDITY
Personalizing Text-to-Image Generation using Textual Inversion | GitHub | Tel Aviv University, NVIDIA
Have you discovered the hottie of the month yet? With us it's a hit!
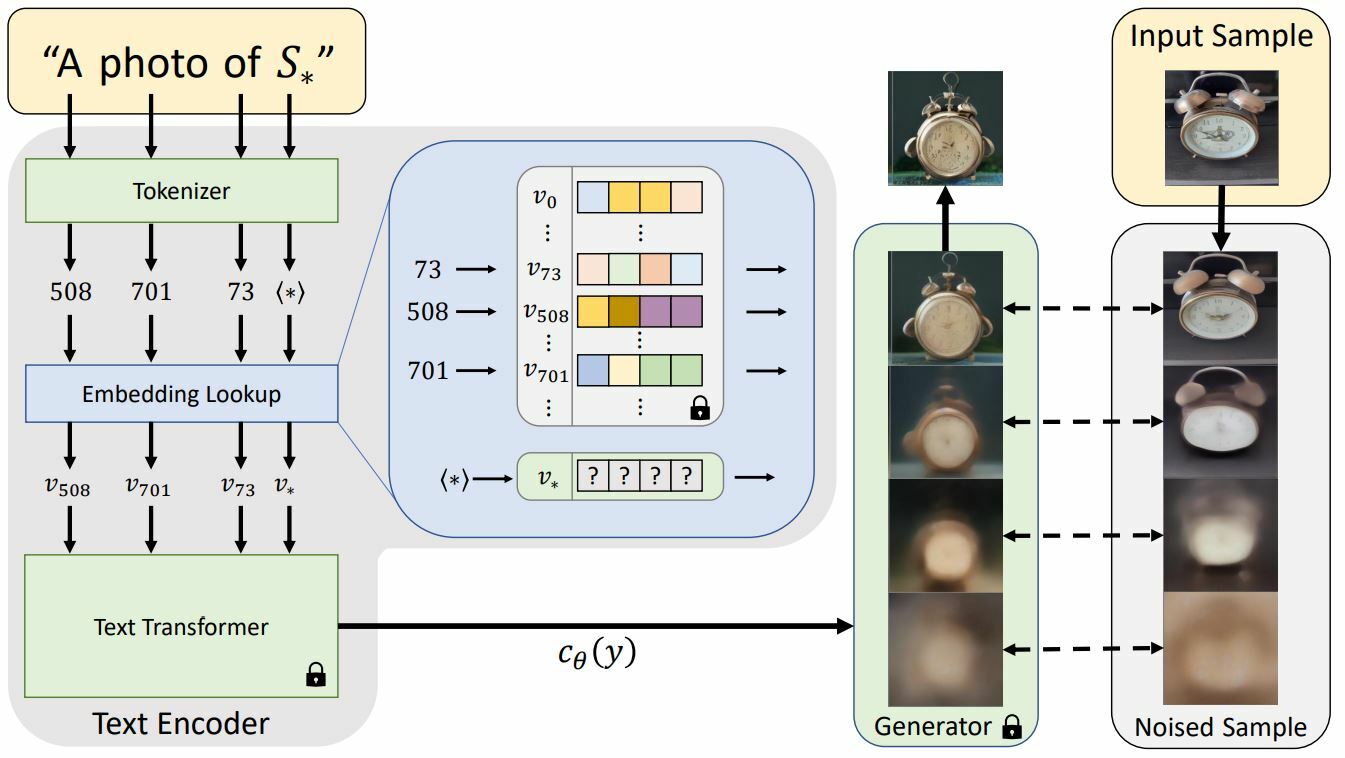
Also this:
Animate Stable Diffusion | Replicate | Andreas Jansson
Animate Stable Diffusion by interpolating between two prompts.
DataTube
Is Google’s New AI As Smart As A Human? | 6 min | AI | Two Minutes Papers
This is a bit off topic, but I think the results are just amazing and worth sharing in the community.
As the video author says: “remember that science is a process. Don’t think about what was achieved in this paper, think about what the results will be a few papers down the line!”
Backstage Developer Portals with Spotify | 1 h | Sai Vennam, Suzanne Daniels, Himanshu Mishra & Bryan Landes | Containers from the Couch
A "backstage peek" at Backstage, an open platform for building developer portals. A great insight.
And something to get you through the day
Alex Dean | Snowplow