
ARTICLES
AWS CEO says the move to cloud computing is only just getting started
| 10 min read | Cloud | Krystal Hur | CNBS
Key points:
- Cloud computing is in its early stages and will only continue to grow, Amazon Web Services CEO Adam Selipsky told CNBC’s Jim Cramer on Tuesday.
- “Essentially, IT is going to move to the cloud. It’s going to take a while. You’ve seen maybe only, call it 10%, of IT move over today. So it’s still day 1. It’s still early. … Most of this is yet to come,” he said.
Why ELT won’t fix your data problems | 7 min read | ELT & ETL | Olivia Iannone | Towards Data Science Blog
A good read on how the issues associated previously with ETL can also be problematic in the ELT approach, unless proper data modeling and governance is introduced.
Modern Data Platform - the what's, why's and how's? Demystifying the buzzword | 7 min read | Data Platform | 👏Jakub Pieprzyk | GetInData Blog
A Modern Data Platform is a common buzzword nowadays. However…
👉What does it take to call a data platform a modern one?
👉What are the key components and characteristics of an MDP?
👉What is completely new about an MDP and what is just an adaptation of the well-known, best practices from this field?
Using Apache Flink for Smart Cities: the case of Warsaw | 8 min read | Apache Flink | Piotr Wawrzyniak & Jarosław Legierski | Ververica Blog
You'll find out how Ververica used Apache Flink as the primary stream processing framework for a Smart City project in the city of Warsaw. (The goal for the VaVeL project was to provide a general purpose framework of mining and managing multiple heterogeneous urban data streams in order for cities to become more efficient).
Additionally, they used Apache Flink to build the two main components of the project, namely our Vehicle Movement Analyser and Vehicle Delay Prediction Systems.
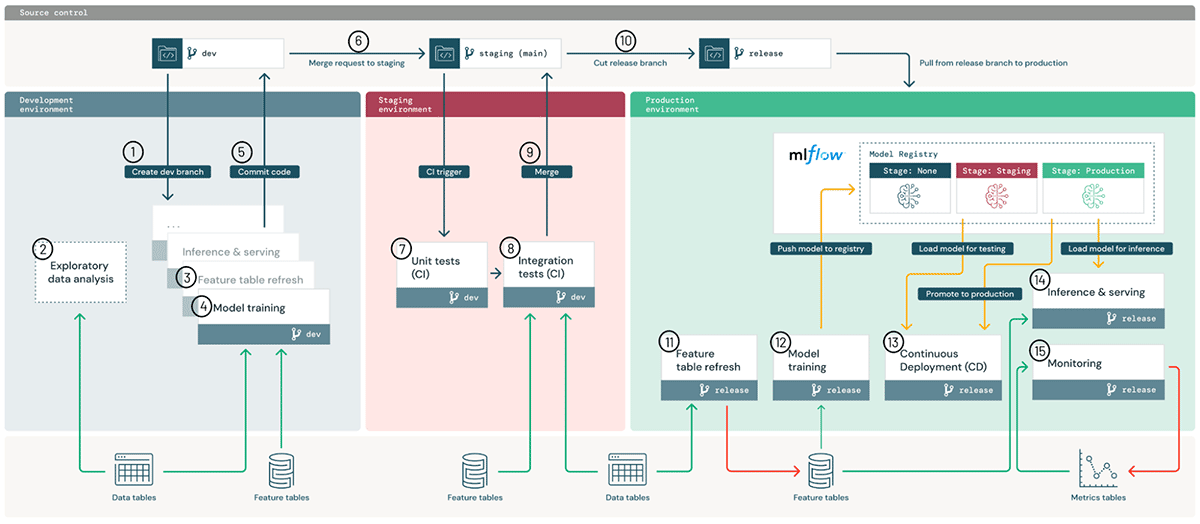
Architecting MLOps on the Lakehouse | 10 min read | MLOps | Databricks Blog
Lakehouses unify the capabilities from data lakes and data warehouses under a single architecture, where this simplification is made possible by using open formats and APIs that power both types of data workloads. Analogously, for MLOps, we offer a simpler architecture as we build MLOps around open data standards.

Do we really need data modeling in the world of the modern data stack?
| 3 min read | Big Data | Nikolay Golov | ManyChat Team
Abstract: data modeling techniques (dimensional modeling, data vault, anchor modeling) were originally created to solve a certain set of problems. Most of these problems are not relevant anymore: they can be resolved out of the box using a modern data stack. However, the issue of analyzing your data, its structure, its quality and its dependencies from an analytical point of view, is still applicable. Data modeling techniques can be very useful here, despite the fact that they were originally created for a slightly different purpose.
Stanford University Open-Sources Controllable Generative Language AI Diffusion-LM | 4 min read | AI, ML | Anthony Alford | infoQ Blog
Researchers at Stanford University have open-sourced Diffusion-LM, a non-autoregressive generative language model that allows for the fine-grained control of a model's output text. When evaluated on controlled text generation tasks, Diffusion-LM outperforms existing methods.
Diffusion-LM is a generative language model that uses a plug-and-play control scheme, where the language model is fixed, and its generation is steered by an external classifier that determines how well the generated text matches the desired parameters. Users can specify several features of the desired output, including required parts of speech, syntax trees, or sentence length.
Graph Machine Learning at Airbnb | 10 min read | ML | Devin Soni | Airbnb Blog
How leveraging graph information allows us to learn more about users, in addition to building more contextual representations of them. This article covers specific graph machine learning methods such as Graph Convolutional Networks, that are being used at Airbnb to improve upon existing machine learning models..
NEWS
Project Lightspeed: Faster and Simpler Stream Processing With Apache Spark | 10 min read | Databricks Blog
#Streaming - Databricks finally takes a serious shot at streaming for Spark!!
Recently, to Structured Streaming was introduced in Apache Spark 2.0. Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. The user can express the logic using SQL or Dataset/DataFrame API.
Databricks launches "new initiative codenamed Project Lightspeed to meet these requirements, which will take Spark Structured Streaming to the next generation". Seems more than intesting!
Delta Lake 2.0.0 | 2 min read | Delta GitHub
For us, the most exciting development is the Change Data Feed.
Announcing gcpdiag - Open Source Troubleshooting Tool for Google Cloud Platform | 7 min read | Google Cloud Platform
Google has introduced gcpdiag, an open source tool to detect configuration issues in Google Cloud projects. gcpdiag is a command-line tool which runs many such automated checks, called rules, and creates a report about all the issues that it detects.
DATA ODDITY
ML in Action: Campaign to Collect and Share Machine Learning Use Cases | 6 min read | ML | Hee Jung & Soonson Kwon
In this article, you will find out who the Winners of "ML in Action" are, e.g.:
Persona Labs' Digital Personas - enable users to interact with life-like Personas in a format similar to a Zoom call : Speaking to them and seeing them respond in real time, just as a human would.
PODCAST
Neural Architecture Search for CTR Prediction | 28 min | AI | Ravi Krishna in Data Skeptic
- What CTR (click-through rate) is about and why it is a vital AI issue today.
- Why using the deep neural network approach stood out as an alternative to other approaches such as collaborative filtering.
- What NAS is, why it is important, how the framework was built and the commensurate result.
How Data Science Drives Value for Finance Teams | 37 min | Brian Richardi on Data Framed
Brian Richardi shares his experience as a data science leader who transitioned to IT from Finance. He provides insights into utilizing collaboration, effective communication to drive value and the future of data science in Finance.
CONFS AND MEETUPS
Streams in space and time - Technology at Citi Investment Strategies | 7 July | Online
Join Corey Prowse from Citigroup discusses how Citi architected a Market Data System (Scala, Java, TypeScript) storing billions of data points, scaling up to over a thousand concurrent connections within an Agile DevOps environment.
