
ARTICLES
ELT is dead, and EtLT will be the end of modern data processing architecture | 11 min | Data Science | DevGenius
Let’s discuss the evolution of data processing architectures, from ETL to ELT and finally to the current EtLT architecture. This text explores the reasons behind these changes, their strengths and weaknesses and why EtLT is emerging as the dominant data processing architecture, along with open-source implementations like Apache SeaTunnel to meet modern data infrastructure demands.
The Top 3 Data Architecture Trends (And How LLMs Will Influence Them) | 5 min | Data Architecture | Hanzala Qureshi | Towards Data Science Blog
This one gives the lowdown on three major trends that are shaping data architecture and spill the beans on how LLMs can be super useful in each of these areas. So, whether it's the coolness of context-driven analytics, the importance of data governance, or the buzz around Co-Pilot, this article spills all the details on what's happening in the world of data architecture.
Microsoft builds the bomb | 7 min | Data Analytics | Benn Stancil | Personal Blog
Last week we mentioned that Microsoft released the Fabric - A Data Platform, combining its data services into one suite. Now it is time to dig into the very interesting comments on it. Highly recommended to read, even if you don’t agree in the end.
Apache Arrow: The Future of Data Engineering | 4 min | Data Engineering | Ravish Kumar | Data Engineer Things
In this one, Ravish provides insights into the benefits and applications of Apache Arrow, shedding light on its potential to revolutionize data engineering practices. Let’s delve into how Apache Arrow's columnar memory format is poised to reshape data processing and analytics, enhancing performance, interoperability, and standardization across various systems and languages.
Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts | 11 min | Data Engineering | Xinli Shang, Kai Jiang, Huicheng Song, Jianchun Xu, Mohammad Islam | Uber Engineering Blog
Dive into the exciting world of Uber's latest innovations. This article discusses the growing trend of building lakehouses on top of storage table formats like Apache Hudi, Apache Iceberg and Delta Lake for various use cases, including incremental ingestion. Explore the implementation of a row-level secondary index and innovative modifications in Apache Parquet to enhance the upsert data process, leading to significantly faster speeds compared to the traditional copy-on-write methods used in Delta Lake and Hudi.
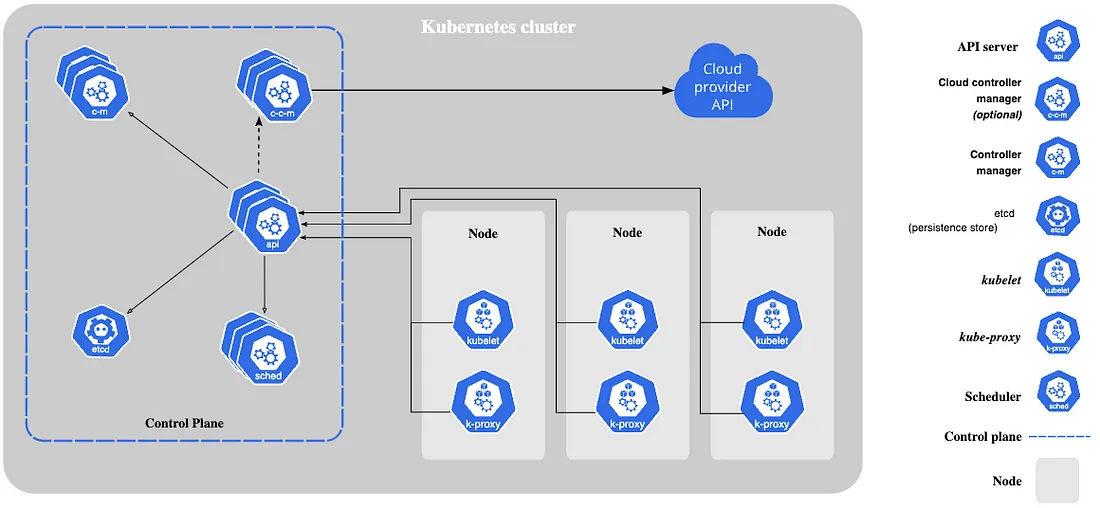
Are Kubernetes days numbered? | 5 min | Cloud | Alistair Grew | CTS Google Cloud Tech Blog
Dig down deep into the 'guts' of Kubernetes to learn more about how it works. Read about Managed Kubernetes, Google’s Container Offerings, compare GKE Standard to Autopilot, Cloud Run and finally decide which you should choose.
TUTORIALS
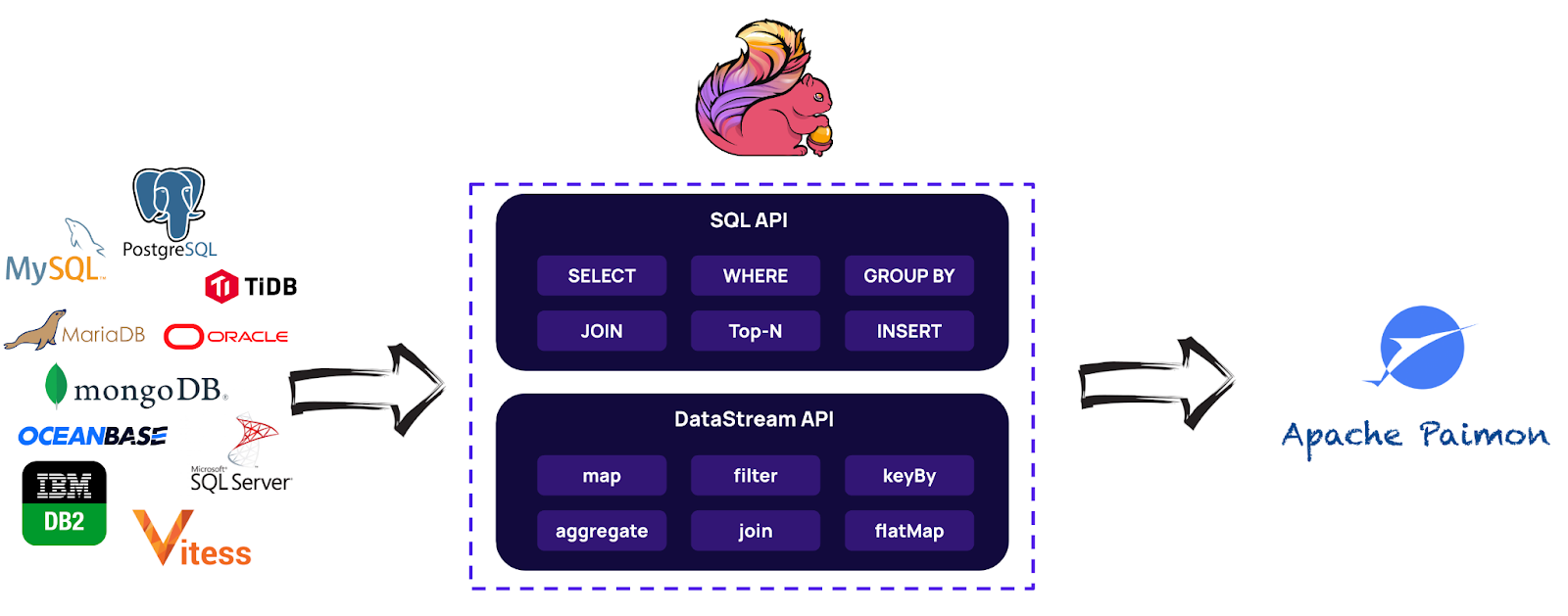
Apache Paimon: the Streaming Lakehouse | 8 min | Data Streaming | Giannis Polyzos | Ververica Blog
Apache Paimon, a streaming storage layer for Apache Flink, supports real-time data ingestion, low-latency queries and efficient data management in the Lakehouse paradigm. It leverages Dynamic Tables, Snapshots and Change Data Capture for high-performance streaming data storage, serving various use cases and gaining traction in large-scale production environments to bolster the Apache Flink ecosystem.
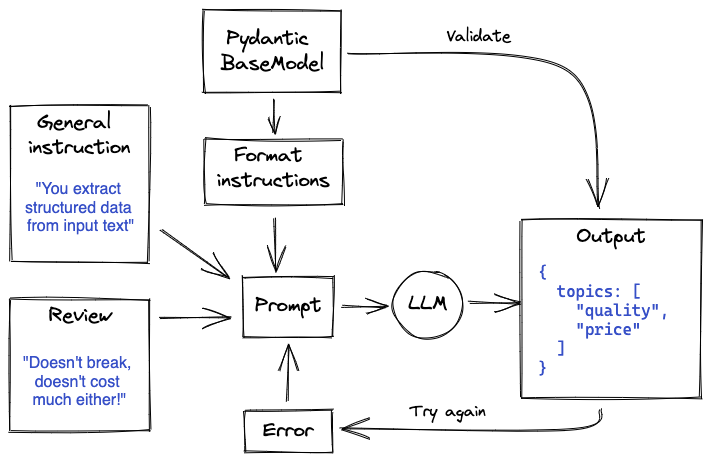
How to Extract Structured Data from Unstructured Text using LLMs | 6 min | LLM | Yke Rusticus | Xebia Tech Blog
This tutorial explores a typical application of Large Language Models (LLMs), which involves extracting structured data from unstructured text. The primary illustration centers on customer feedback analysis, demonstrating how an LLM, when coupled with an effective prompting strategy, enables the transformation of unstructured textual data into organized information. The resulting structured data has the potential to enhance databases and contribute to more informed decision-making processes.
Head-to-head comparison of 3 dbt SQL engines | 8 min | SQL | Niels Claeys | Data Minded Blog
This blog post compares three popular open-source SQL engines (Duckdb, Trino and Spark) for use with dbt in data pipelines. The benchmarking setup uses the TPC-DS benchmark with medium-sized datasets, highlighting that Duckdb performs the fastest in 75% of cases due to its single-node advantage. Trino is the fastest in the remaining 25%. It also touches on the user experience and differences in SQL dialects between these engines, when integrating them with dbt.

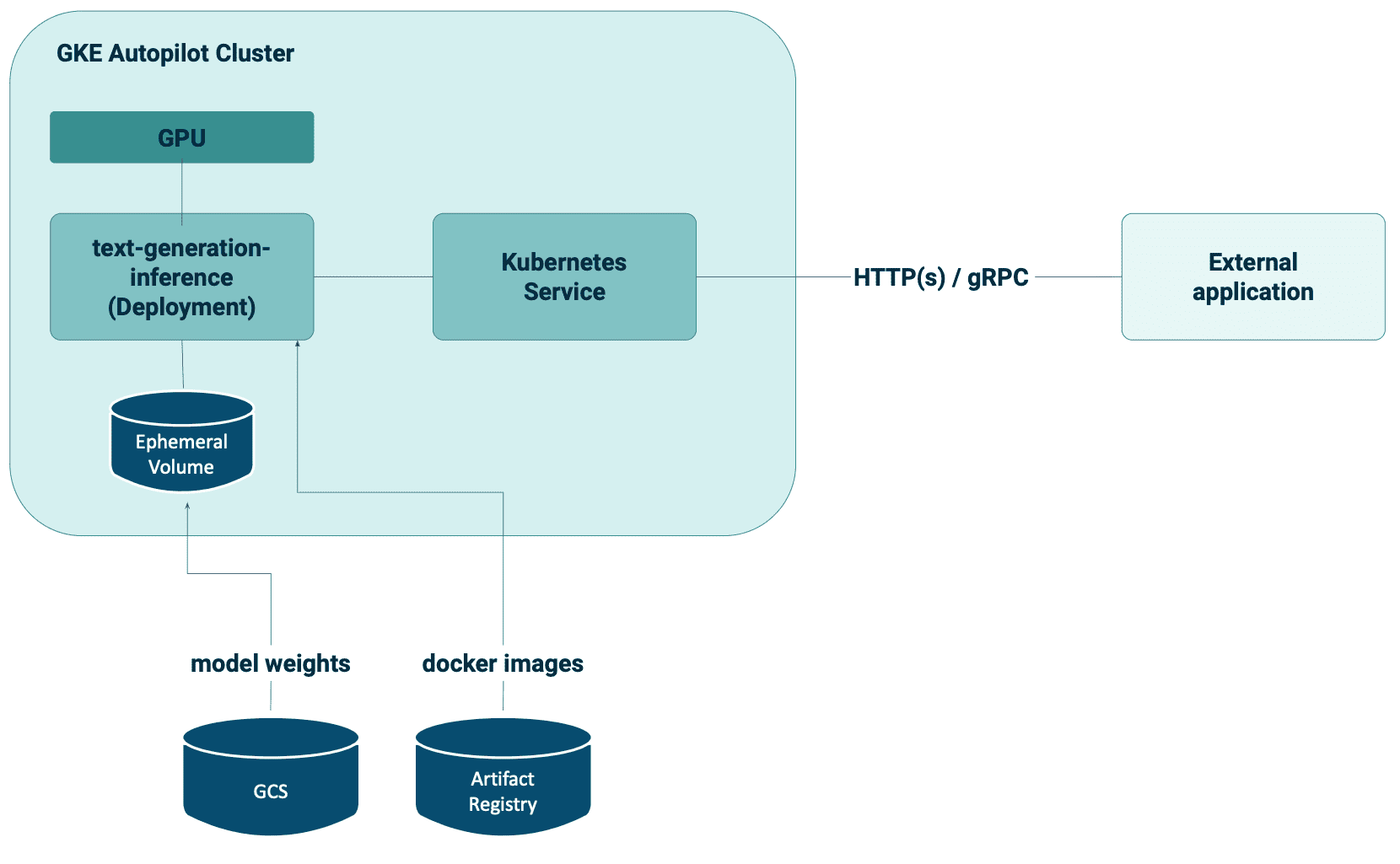
Falcon LLM: Deploy open source LLM in your private cluster with Hugging Face and GKE Autopilot | 12 min | LLM | Marcin Zabłocki | GetInData | Part of Xebia Blog
This tutorial delves into the seamless deployment of an open-source Language Model (LLM) private cluster by leveraging Hugging Face and Google Kubernetes Engine (GKE) Autopilot.
TOOLS
SQLLineage | SQL
This tool simplifies identifying source and target tables in SQL commands, handling all the parser intricacies using libraries like SQLfluff and SQLparse to generate a user-friendly lineage graph.
English SDK | Data Engineering
The English SDK for Apache Spark is an extremely simple yet powerful tool. It takes English instructions and compiles them into PySpark objects like DataFrames. Its goal is to make Spark more user-friendly and accessible, allowing you to focus your efforts on extracting insights from your data.
MyMLOps | MLOps
Experience the convenience of visualizing your MLOps stack directly in your browser with MyMLOps. This project offers a user-friendly tool stack builder, providing brief insights into various tools and their categories. You can also share your customized stack with others.
DATA TUBE
Architecture of Netflix's Data Mesh. Data mesh use cases | 41 min | Data Mesh | Jordan Lewis, Vlad Sydorenko | CockroachDB
Dig into Netflix's Data Mesh architecture, use cases and how it optimizes data insights without database slowdowns. Discover how Netflix's Data Mesh Platform addresses challenges with multiple writes, providing a powerful solution for your data needs.
You will learn all about the following:
- CDC use cases and shortcomings
- How Netflix uses changefeeds today
- What Netflix’s data mesh architecture looks like
- What others can learn from Netflix’s architecture
Kedro + PyTorch. MLOps TUTORIAL | 33 min | MLOps | Marcin Zabłocki | GetInData | Part of Xebia
How to combine Kedro and PyTorch in one machine learning project? Is this a good combination? The answer is: YES! In this tutorial, Marcin Zabłocki shows how to leverage all features from Kedro and PyTorch
- Kedro → abstraction of a pipeline, nodes and parameters; data catalog; environments
- PyTorch → neural networks; distributed computing; data preprocessing; datasets in one ML project without ANY sacrifices or workarounds.
Column-level lineage is coming to the rescue | 34 min | AI | Paweł Leszczyński, Maciej Obuchowski | Berlin Buzzwords 2023
OpenLineage is a standard for metadata and lineage collection that is growing rapidly. Column-level lineage is one of its most anticipated features of the community that has been developed recently.
Listen to the talk where Paweł and Maciej:
- show foundations for column lineage within OpenLineage standard,
- provide real-life demo on how is it automatically extracted from Spark jobs,
- describe and demo column lineage extraction from SQL queries,
- show how the lineage can be consumed on Marquez backend.
They aim to provide demos to focus on practical aspects of the column-level lineage which are interesting to data practitioners all over the world.
PODCAST
The LLM Battle Begins: Google Bard vs ChatGPT | 25 min | LLM | Francesco Gadaleta | Data Science at Home Podcast
Brace yourselves as we uncover the mind-blowing AI model, Google Bard, poised to challenge ChatGPT and other conversational AI systems. Join us as we explore the revolutionary features of Bard, its cutting-edge architecture, and its ability to generate human-like responses. Discover why AI enthusiasts are buzzing with excitement.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
