
ARTICLES
The Lakehouse Is Dead. Long Live the Lakehouse | Data Engineering | 6 min | Thomas F McGeehan V | Personal Blog
A sharp, funny critique of today’s bloated lakehouse stacks that questions whether complexity has become the product. If you’ve ever wrangled Iceberg and wondered “why?”, read this.
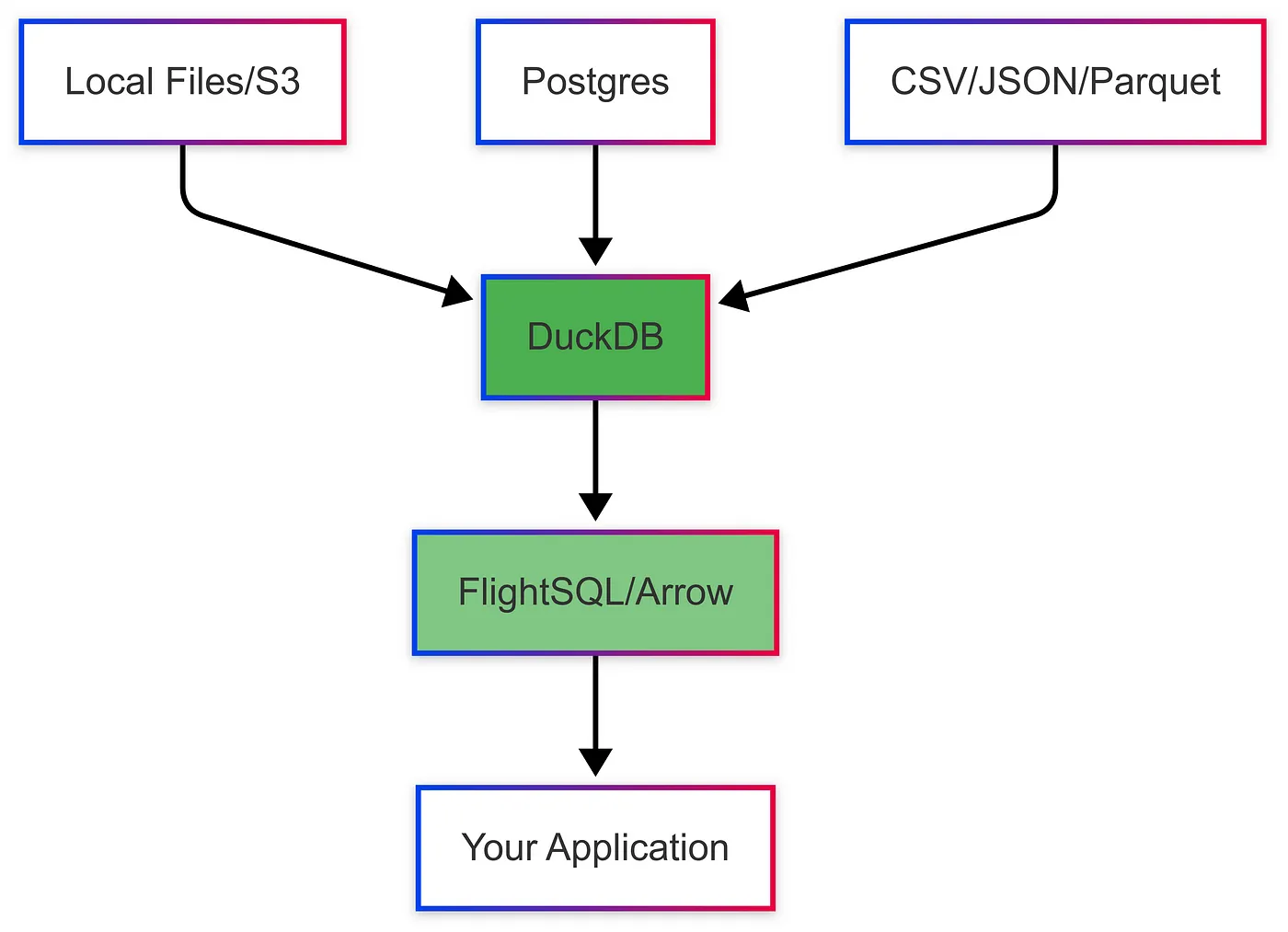
How OpenAI uses Apache Kafka and Flink for GenAI | 5 min | Data Streaming | Kai Waehner | Personal Blog
Get a look at how OpenAI uses Kafka and Flink to power real-time, event-driven GenAI systems. Great architecture snapshot for anyone scaling LLMs.
Why you need diverse third-party data to deliver trusted AI solutions | 4 min | AI | David Gibson, Michael Geden | Stack Overflow Blog
This post argues that diverse, high-quality third-party data is what truly powers responsible AI. It’s a strategic look at model inputs, not just algorithms.
Next-Level Personalization: How 16k+ Lifelong User Actions Supercharge Pinterest’s Recommendations | 7 min | Recommendation System | Xue Xia, Saurabh Vishwas Joshi, Kousik Rajesh, Kangnan Li, Yangyi Lu, Nikil Pancha, Dhruvil Deven Badani, Jiajing Xu, Pong Eksombatchai | Pinterest Engineering Blog
Pinterest trained a new model on 16,000 user actions to improve feed ranking with massive gains in repins and fewer hides. One of the strongest personalization upgrades we’ve seen.
TUTORIALS
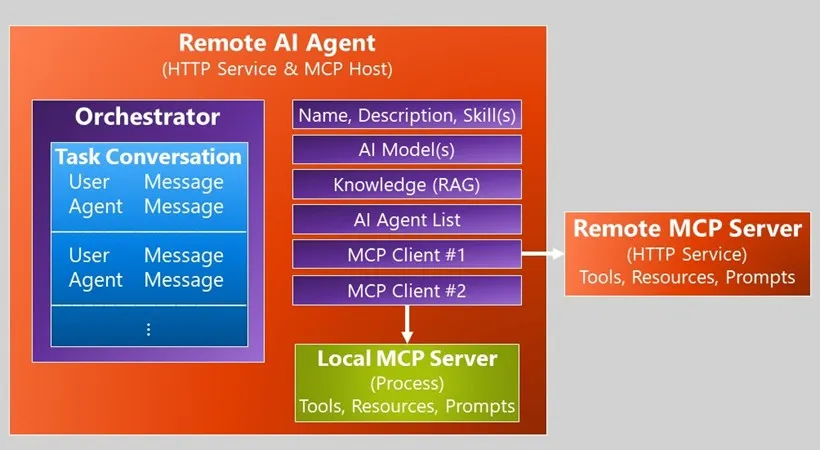
AI Agent Architecture via A2A/MCP| 15 min | AI | Jeffrey Richter | Personal Blog
A hands-on breakdown of how to design autonomous AI agents that plan, act, and learn. If you’re building beyond chat interfaces, this is a practical architectural guide.
NEWS
Introducing Agent Bricks: Auto-Optimized Agents Using Your Data | 6 min | AI | Xiangrui Meng, Kasey Uhlenhuth, Hanlin Tang, Patrick Wendell, Matei Zaharia | Databricks Blog
Agent Bricks is a new framework for building, monitoring, and deploying RAG agents at scale. Integrated with Unity Catalog and MLflow for production-readiness.
PODCAST
Iceberg Table Spec | 30 min | Data Engineering | Apache Iceberg
The deep tech behind Apache Iceberg. This spec defines how its table format handles snapshots, schema changes, and metadata. It's a foundational reference for engineers implementing or extending Iceberg in production systems.
PODCAST
Amazon S3: The Backbone of Modern Data Systems | 1 h 1 min | Data Engineering | Mai-Lan Tomsen Bukovec, Tobias Macey | Data Engineering Podcast
Mai-Lan Tomsen Bukovec from AWS reflects on how S3 shaped the modern data stack. Covers consistency, metadata, and the rise of data lakes.
DATA TUBE
Build Realtime Fraud Detection AI from Scratch - End to End Machine Learning Project - Part 1 | ML | 4 h 51 min | Yusuf Ganiyu | CodeWithYu
A full hands-on project using Kafka, Spark, and ML to detect fraud in real time. Covers architecture, model training, and scaling.
DATA TUBE
Machine Learning Summit 2025: Applied ML Engineering to GenAI and LLMs| Online | 16th July
A focused event on applied ML, GenAI, and LLM systems in production. Use code AS40 for 40% off tickets.
PINNACLE PICKS
Your last week top picks:
Multi-Table Multi-Statement Transaction with Apache Iceberg | Data Engineering | 44 min | Jack Ye | Apache Iceberg
Jack Ye dives into the new Iceberg spec supporting cross-table transactions with SQL isolation. Also: Gravitino integration and future plans for Hudi and Paimon.
Running dbt Projects On Snowflake | 11 min | AI | Snowflake Developers
A hands-on demo of dbt on Snowflake: visualize DAGs, run tests, and deploy pipelines with ease using the new native dbt integration.
Delivering the Most Enterprise-Ready Postgres, Built for the Snowflake AI Data Cloud | 4 min | Data Engineering | Christian Kleinerman, Paul Laurence | Snowflake Blog
With its Crunchy Data acquisition, Snowflake launches managed Postgres built for secure, AI-ready transactional workloads on the Data Cloud.
________________________
Have any interesting content to share in the DATA Pill newsletter?
