
ARTICLES
Streaming SQL in Data Mesh | 7 min | Data Mesh | Guil Pires, Mark Cho, Mingliang Liu, Sujay Jain | Netflix Engineering Blog
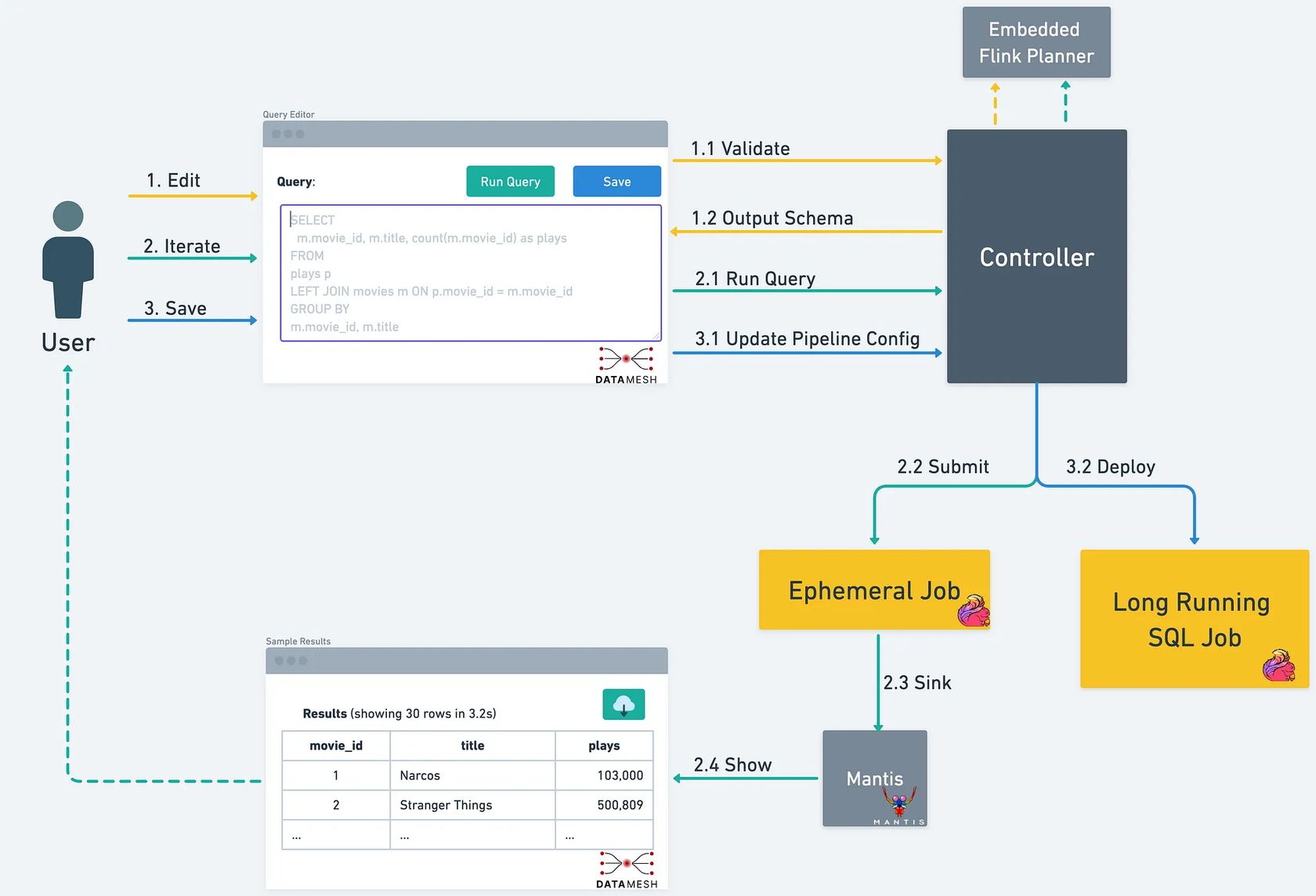
The Netflix team introduces a platform for data processing through interconnected pipelines using Processors and Kafka topics, addressing user challenges in expressing intricate business logic. The launch of the Data Mesh SQL Processor aims to increase the user experience with SQL-based transformations and real-time validation within the platform while considering certain limitations compared to low-level DataStream API implementations.
BigQuery is much cheaper than you think | 13 min | Cloud Analytics | Alexander Ryazanov | Level Up Coding Blog
BigQuery, a top-tier cloud analytical database, was once known for its expensive pricing, particularly for tasks like ELT transformations. However, recent changes in its pricing rules, especially in 2023, have brought more affordable options. Understanding these changes and optimizing your approach is crucial for achieving cost-effective performance. Covered topics:
- The choice of the storage pricing model and how it affects the BigQuery monthly bill.
- Using multiple projects to increase the throughput of recurring pipelines.
- Granular query execution pricing strategies.
Top 5 Orchestration Tools in 2023 | 14 min | Data Engineering | Dario Radečić | Towards Data Engineering
This one will take a high-level look at 5 best orchestration tools in 2023, which are: Airflow, Kestra, Azure Data Factory, Prefect, and AWS Step Functions. Let's discuss what makes each tool unique, who it is best suited for, pros, cons, and pricing.
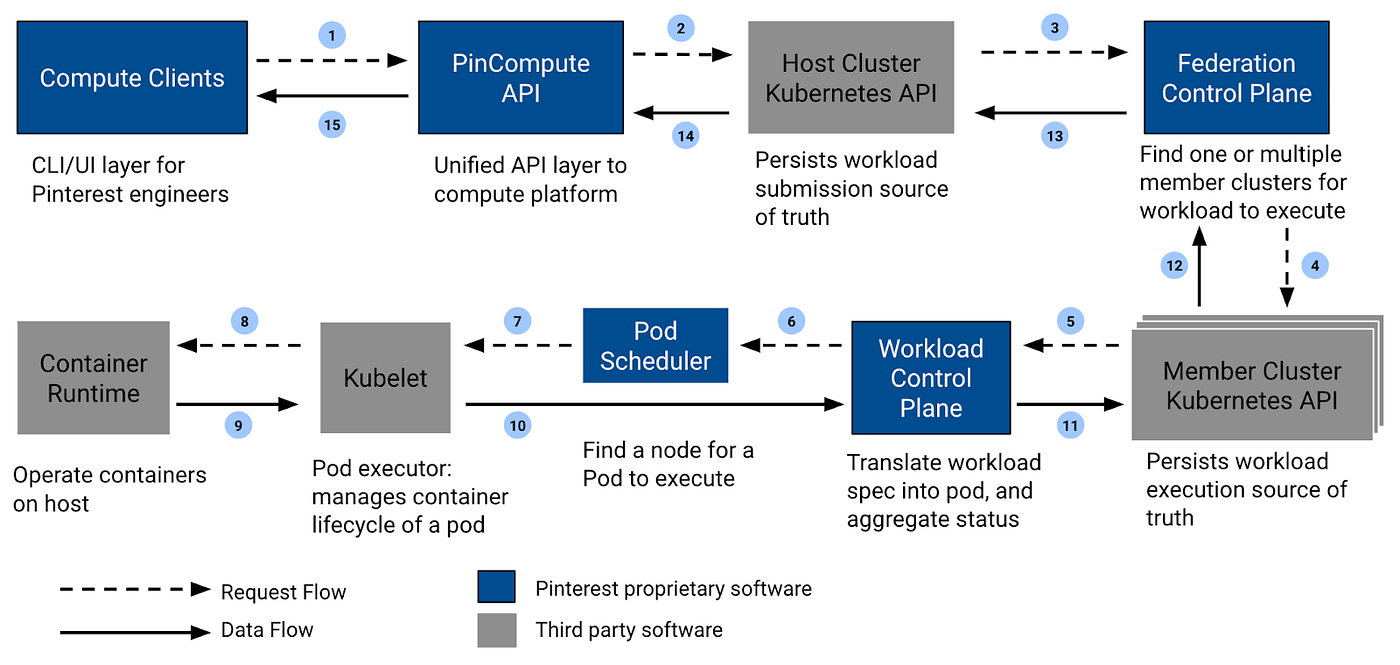
PinCompute: A Kubernetes Backed General Purpose Compute Platform for Pinterest | 18 min | Data Engineering | Harry Zhang, Jiajun Wang, Yi Li, Shunyao Li, Ming Zong, Haniel Martino, Cathy Lu, Quentin Miao, Hao Jiang, James Wen, David Westbrook | Pinterest Engineering Blog
In this article, we discuss the PinCompute primitives, architecture, control plane and data plane capabilities, and showcase the value that PinCompute has delivered for innovation and efficiency at Pinterest.
TUTORIALS
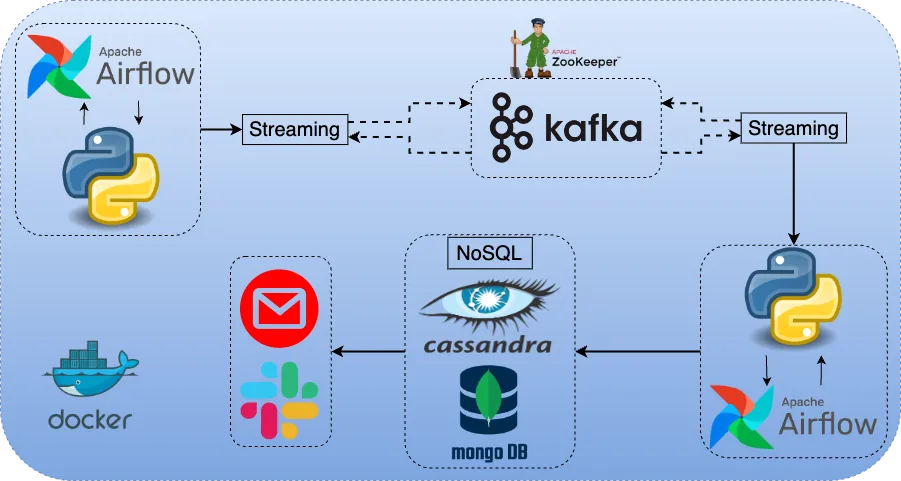
Data Engineering End-to-End Project — Airflow, Kafka, Cassandra, MongoDB, Docker, EmailOperator, SlackWebhookOperator — Part I, Part II | 19 min | Data Engineering | Dogukan Ulu | Apache Airflow Blog
This article series details the creation of a data pipeline orchestrated by Airflow. The process involves setting up a Kafka topic, generating messages containing e-mail and OTP records, checking data in Cassandra and MongoDB, and finally, using Airflow to establish a complete DAG comprising essential tasks for the entire pipeline.
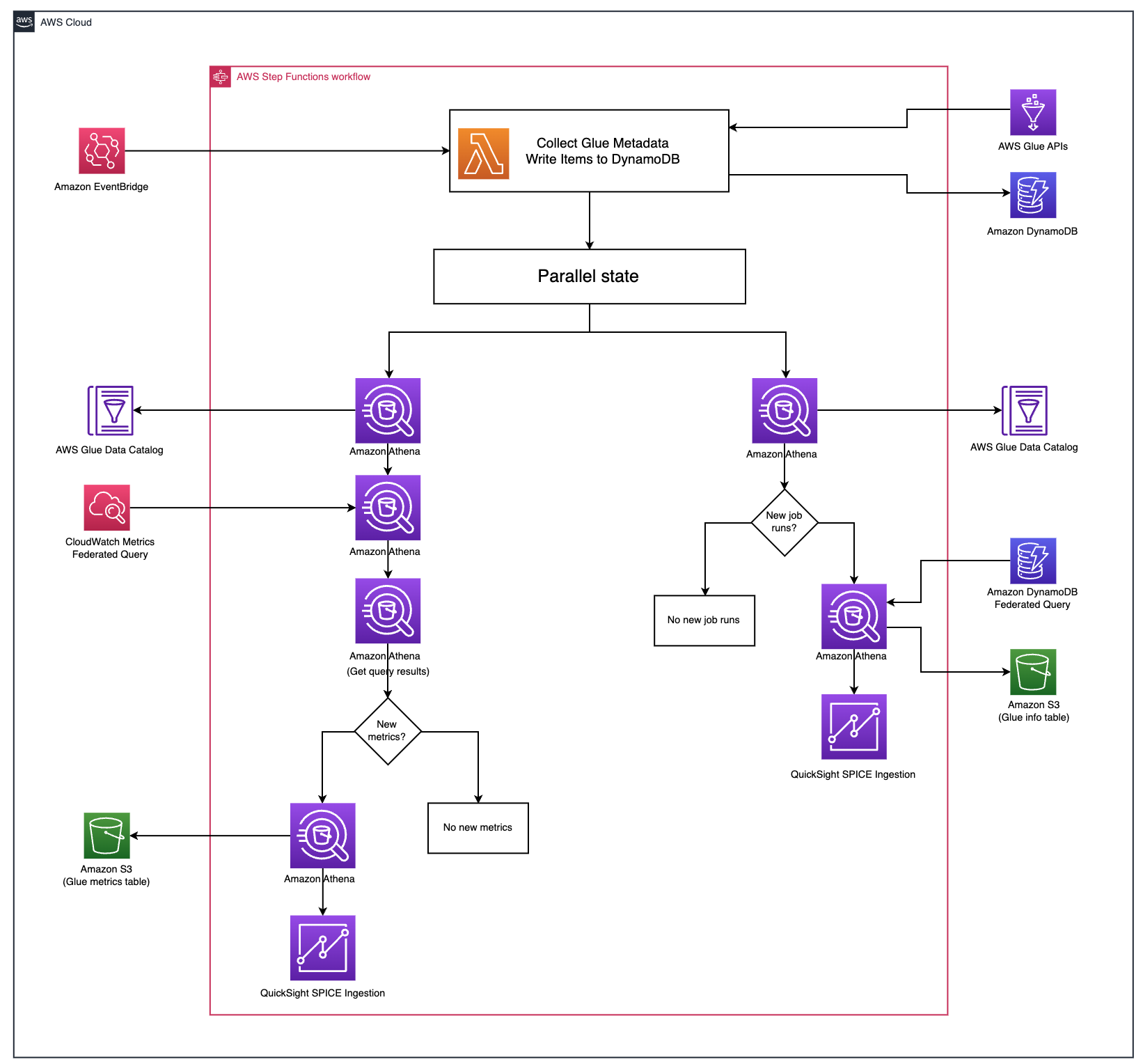
Deploy Amazon QuickSight dashboards to monitor AWS Glue ETL job metrics and set alarms | 5 min | Cloud | Michael Hamilton, Cody Penta, Angus Ferguson | AWS Tech Blog
The tutorial delves into combining AWS Glue usage data and metrics, integrating them with centralized reporting and visualization through QuickSight. This approach offers a broader perspective on usage and provides enhanced tools for detailed exploration of the AWS Glue job run environment. While the AWS Glue console offers metrics per job run, it lacks coverage of all available AWS Glue job metrics and interactive visualization features in the QuickSight dashboard.
Introducing Python User-Defined Table Functions | 5 min | Data Engineering | Allison Wang, Daniel Tenedorio, Takuya Ueshin, Allan Folting | Databricks Blog
This one introduces the latest feature in Apache Spark™ 3.5 and Databricks Runtime 14.0: Python user-defined table functions (UDTFs). It explores the concept, benefits, comparison with other functions, creation steps, usage in Python and SQL, and optimization using Apache Arrow, providing a practical understanding of these powerful functions for data manipulation.
NEWS
Databricks + Arcion: Real-time enterprise data replication to the Lakehouse | 3 min | Real-time | Reynold Xin, Sameer Paranjpye, Awez Syed, Bilal Aslam, Erika Ehrli, Ori Zohar and Cassie Miao | Databricks
Databricks is announcing its acquisition of Arcion, a company specializing in real-time data replication. Arcion's technology will assist Databricks in providing native solutions for data replication from multiple sources, enabling customers to focus on extracting value and AI-driven insights.

TOOLS
XAgent | LLM
XAgent, an open-source experimental Large Language Model (LLM) autonomous agent, autonomously tackles diverse tasks. It's built as a versatile tool for many tasks, albeit in its early developmental phase, and continuous improvements are underway.
DATA TUBE
Scaling Data Engineering in Retail | 57 min | Data Engineering | Richie Cotton, Mo Sabah | Data Framed Podcast
Dig into leveraging AI for pattern identification and preemptive error resolution, utilizing tools like dbt and SODA for data pipeline abstraction, and emphasizing stakeholder participation in ensuring data quality, governance, and engineering foundations. This episode touches on validation layers in the data pipeline, collaborative problem-solving between data analysts and engineers, fostering the reusability of patterns, and instilling an ownership mentality in data engineering practices.
PODCAST
How Klarna Designed a New Data Platform in the Cloud | 40 min | Cloud | Guest: Gunnar Tangring | The Data Engineering Show
Klarna, a significant fintech company valued at $45 billion, has shifted to a cloud-only operational model. Gunnar Tangring, Klarna’s Lead Data Engineer, shares insights on the new modernized infrastructure in a discussion with Boaz.
CONFS EVENTS AND MEETUPS
Learn how to use Generative AI with Snowflake and Microsoft Azure Open AI | Webinar | 15th November
Join this virtual hands on lab where partner engineers from Microsoft and Snowflake will introduce the common business cases for using Generative AI and discuss the common patterns for using Snowflake with Azure Open AI to generate insights from your data in Snowflake.
During the session, participants will learn:
- How and why Generative AI is currently being used in organizations
- 5 most common use case patterns
- How to integrate Snowflake data with Azure Open AI services
- How to use Azure Open AI services to build and deploy your first Generative AI application
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
