
ARTICLES
4 Tips for Data Quality Validations with Pytest and PySpark | 11 min | Data Quality | Taylor Wagner, Likitha Lokesh | Slalom Build Blog
A recent data software project required extensive testing on transformed data using AWS Glue. PySpark was used for data transformation, and the test automation framework incorporated Pytest alongside PySpark. This cohesive approach ensured high data quality standards, which are crucial for accurate data analysis and ingestion by third-party tools. This blog shares four key takeaways from the experience of enhancing data quality testing in similar projects.
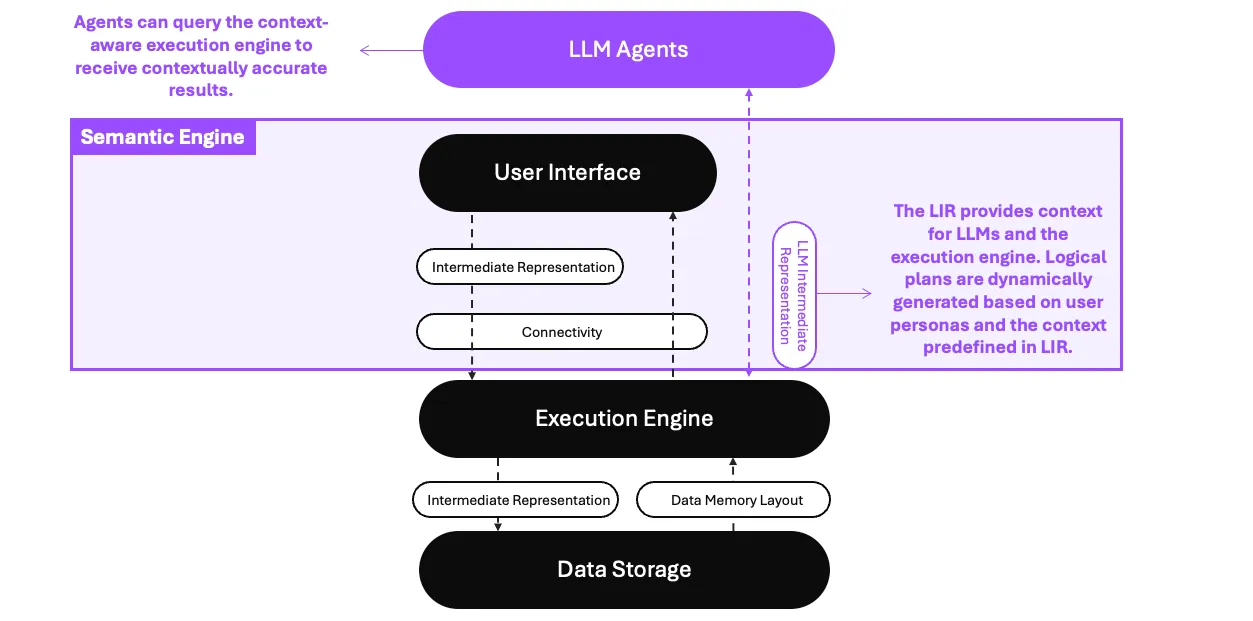
The new wave of Composable Data Systems and the Interface to LLM agents | 11 min | LLM | Howard Chi | WrenAI Blog
Traditional databases use monolithic designs optimized for storage, computing, SQL, and API. There's recently been a shift towards open standards, with vendors like Snowflake and Databricks adopting formats like Apache Iceberg. This blog explores the benefits of composable data systems and integrating large language models into data infrastructure.
Optimizing Flink SQL: Joins, State Management and Efficient Checkpointing | 14 min | Data Processing | Maciej Maciejko | GetInData | Part of Xebia Blog
Maciej shares expert tips on optimizing Apache Flink SQL jobs for better performance and reliability. He covers strategies for efficient joins, state management, and checkpointing, providing practical advice to enhance data processing workflows.
Five Levels Of AI Agents | 7 min | LLM | Cobus Greyling | Personal blog
This blog demystifies agents, distinguishing domain-specific implementations from general AGI. It explores leveraging LLMs and AI agents for practical applications, addresses tools, costs, and latency and discusses their impact on various industries.

How does LinkedIn process 4 Trillion Events every day? | 7 min | Real-time analytics | Vu Trinh | The Deep Hub
Do you remember the article "How Twitter processes 4 billion events in real-time daily" from DATA Pill 107? This time, Vu explores LinkedIn's approach to handling trillions of real-time events daily using Apache Beam. He highlights the transition from a lambda architecture to a more unified model, enhancing efficiency and transparency in the data processing pipeline.

TUTORIALS
Supercharging Airflow & dbt with Astronomer Cosmos on Azure Container Instances | 6 min | Data Engineering | Daniel van der Ende | Xebia Blog
Learn how to turn opaqueness into transparency by using Astronomer Cosmos to automatically render a dbt project into an Airflow DAG while running dbt on Azure Container Instances.

Text-to-SQL Using SingleStore Helios, Groq, and Llama 3 | 9 min | LLM | Akriti Upadhyay | Personal Blog
This tutorial explores how text-to-SQL has revolutionized database interactions and demonstrates its implementation using SingleStore Helios, LlamaIndex, and Groq.
How to Turn a REST API Into a Data Stream with Kafka and Flink | 6 min | Data Streaming | Lucia Cerchie, Dave Troiano | Confluent Blog
Various paradigms exist in the evolving world of real-time data APIs, including S3, Snowflake, and REST APIs. This post explores why REST APIs dominate and demonstrates bridging them with data streaming using the OpenSky network and Apache Kafka®.
PODCAST
Making ETL pipelines a thing of the past| 26 min | AI | Cassandra Shum, Ben Popper | The Stack Overflow Podcast
We chatted with Cassandra Shum, VP of Field Engineering at RelationalAI, about her company’s efforts to create what is called the industry’s first coprocessor for data clouds and language models. The goal is to allow companies to keep all their data where it is today while still tapping into the capabilities of the latest generation of AI tools.
DATA TUBE
Let's reproduce GPT-2 | 4 h | AI | Andrej Karpathy | Personal Channel
This video demonstrates the entire process of reproducing GPT-2 (124M) from scratch. It covers building the GPT-2 network, optimizing its speed training, setting up the training run with GPT-2 and GPT-3 hyperparameters, and reviewing the results the following day. Note that this video builds on knowledge from earlier Zero to Hero Playlist videos. It closely resembles the creation of my nanoGPT repo, which is about 90% similar by the end.
CONFS EVENTS AND MEETUPS
Azure & AI Lowlands '24 | Utrecht | 7-10th October
Azure & AI Lowlands is a single day event with five tracks around the Microsoft Azure Platform. Focussing on cloud engineers, azure developers, AI engineers and AI enthousiasts.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
