
ARTICLES
Introducing Impressions at Netflix | 6 min | Data Engineering | Tulika Bhatt | Netflix Tech Blog
Netflix tracks homepage image interactions (‘impressions’) to optimize personalization and content recommendations. This blog series details how they process billions of impressions daily to refine engagement strategies.
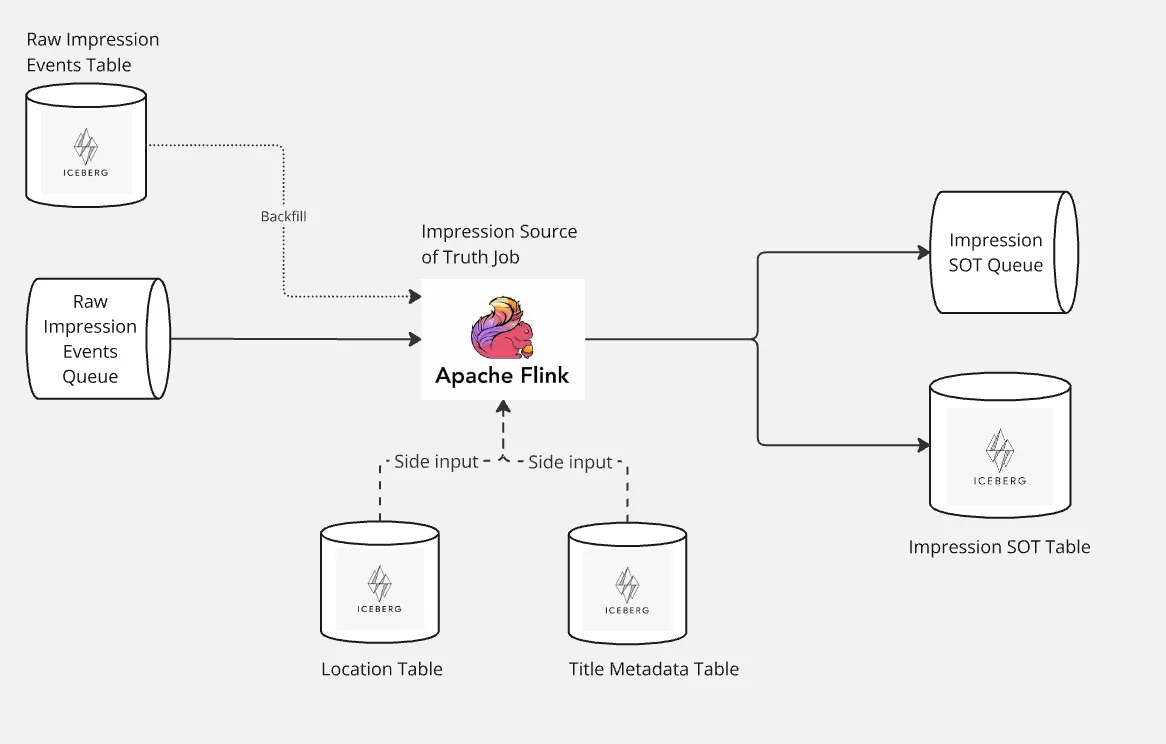
Data vs. Business Strategy | 10 min | Data Strategy | Jens Linden | Personal Blog
A strong data strategy must align with business goals, not exist separately. Learn how to embed data initiatives within broader strategic frameworks to maximize impact.
Top Themes in Data in 2025 | 3 min | Data | Tomasz Tunguz | Personal Blog
Data in 2025 is shaped by consolidation of the modern data stack and AI-driven expansion. Companies are streamlining architectures while leveraging AI-driven SQL execution and cost-efficient models.
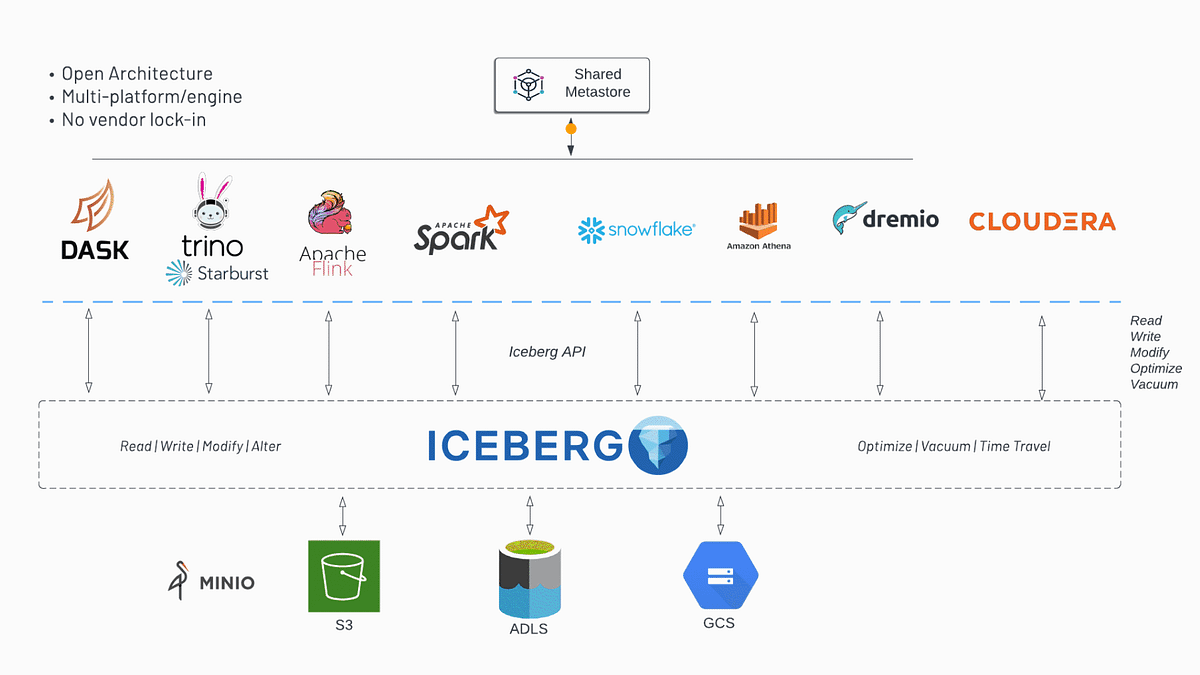
Getting Started with Apache Iceberg: The Next Big Thing in Data Lakehouses | Data Engineering | 5 min | Rui Carvalho | Art of Data Engineering
Art of Data Engineering Apache Iceberg brings ACID transactions, schema evolution, and optimized queries to data lakes. Learn why companies are rapidly adopting it for scalable, cost-effective analytics.
TUTORIALS
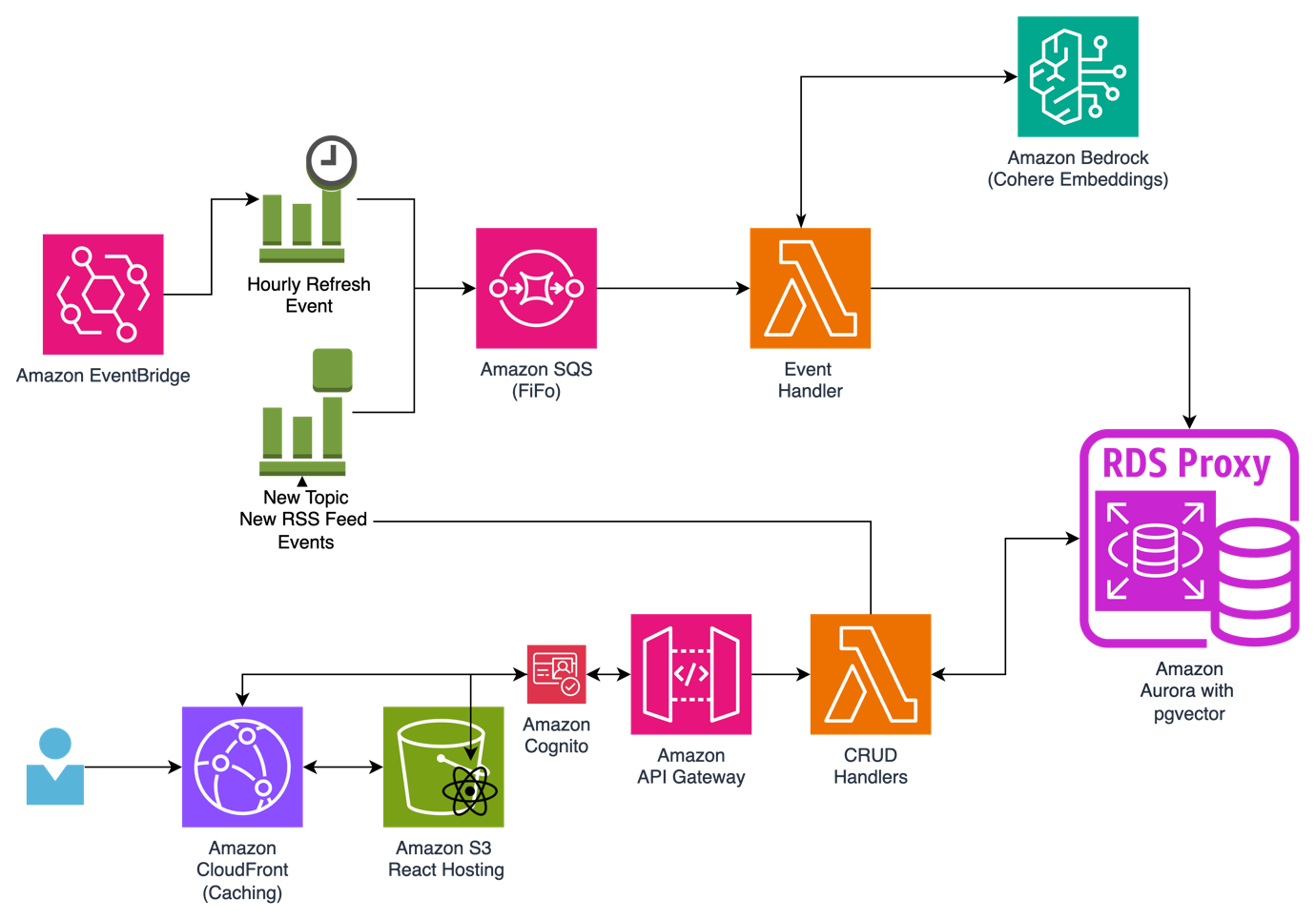
Use language embeddings for zero-shot classification and semantic search with Amazon Bedrock | 7 min | Data Engineering | Tom Rogers | AWS Blog
Discover how embeddings improve classification and search accuracy with Amazon Bedrock. This guide covers using Cohere v3 Embed for scalable, AI-driven recommendations.
Building Better AI Applications with LLM Tracing using Opik | 9 min | LLM | Pondhouse Data
Opik helps developers debug LLM applications with tracing, monitoring, and cost-optimization. Learn how to integrate it for improved AI performance.
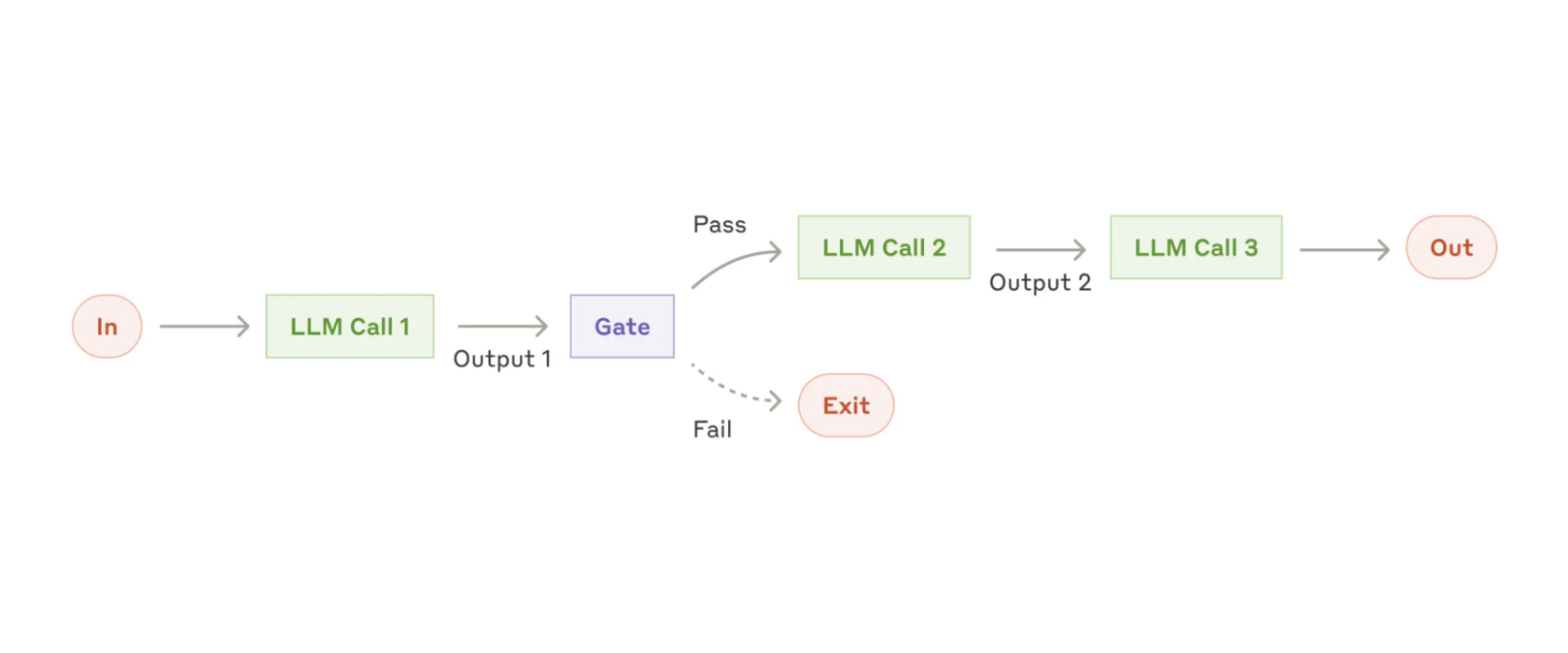
Building effective agents| 6 min | LLM | Anthropic Blog
LLM agents succeed with simple, composable patterns. Explore key techniques for designing transparent, scalable, and efficient AI agents.
NEWS
Apache DataFusion Comet 0.6.0 Release | Data Engineering | 2 min | Apache DataFusion Blog
Apache DataFusion Blog Comet 0.6.0 accelerates Apache Spark by converting plans into DataFusion without code changes. Updates include new array functions and improved execution metrics.
DATA TUBE
A Hands-On Introduction to PyFlink | Stream Processing | 6 min | Decodable
PyFlink enables scalable stream processing with Python. Learn to set up, run basic jobs, and deploy a real-time vector ingestion pipeline.
CONFS, EVENTS AND MEETUPS
Leading with Data: How to Build a Data-Literate Organization | On-demand Webinar | 1 h
Learn strategies from Heineken and Van Oord to improve data literacy, measure impact, and foster a data-driven culture.
PINNACLE PICKS
Your last week top picks:
7 Powerful Questions to Define and Execute Your Data Strategy | 3 min | Data Strategy | Steven Nooijen | Xebia Blog
Define a data strategy that delivers business impact. Seven key questions to align data efforts, balance short-term wins, and engage the right stakeholders.
Bridging the Data Divide: How Confluent and Databricks Are Unlocking Real-Time AI | 3 min | Real-Time AI | Jay Kreps, Ali Ghodsi | Confluent Blog
Confluent and Databricks integrate to enable real-time AI, combining governance and event-driven learning for fraud detection, personalization, and automation.
Run DeepSeek R1 Locally With Ollama | Build a Local Gradio App for RAG| RAG | 41 min | Data Camp
Step-by-step guide to building a local RAG-powered app for querying PDFs securely with LangChain and vector databases.
________________________
Have any interesting content to share in the DATA Pill newsletter?
