
ARTICLES
Data Contracts: The Mesh Glue | 8 min | Data & ML | Luis Velasco | Toward Data Science Blog
Data Mesh + Open source components + data contracts
In this article Luis explains the “Data contract” concept, which ensures that information spread across different data products can be shared and reused along with a couple of technical implementations using open source components for one fundamental process in the data contracts lifecycle: its evaluation.
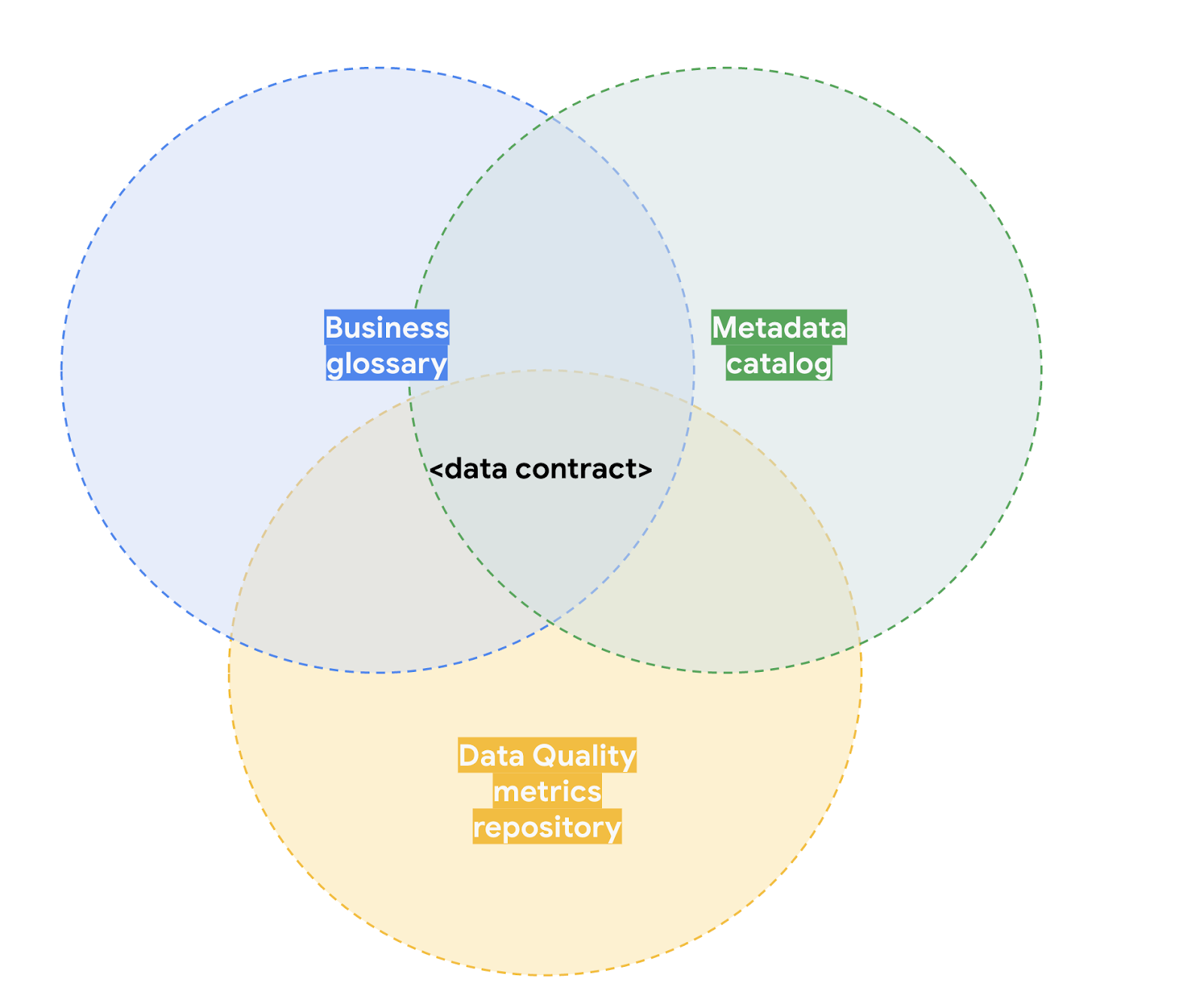
With the ultimate goal of building trust on “someone else's” data products, data contracts are artifacts that sit at the intersection of a (a) business glossary providing rich semantics, (b) a metadata catalog providing information about the structure (c) a data quality repository setting expectations about the content across different dimensions. To ease and promote data sharing.
State of AI Report 2022 | 10 min | AI | Nathan Benaich & Ian Hogarth | State of AI
The State of AI report 2022 has been released. Just wow - so much interesting content and recent developments summarized and analyzed in this report (not that new for someone that follows the AI field). There is also an investor's view on AI which is especially interesting.
- The China-US AI research gap has continued to widen
- Safety is gaining awareness among major AI research entities
- AI-driven scientific research continues to lead to breakthroughs, but major methodological errors like data leakage need to be interrogated further.
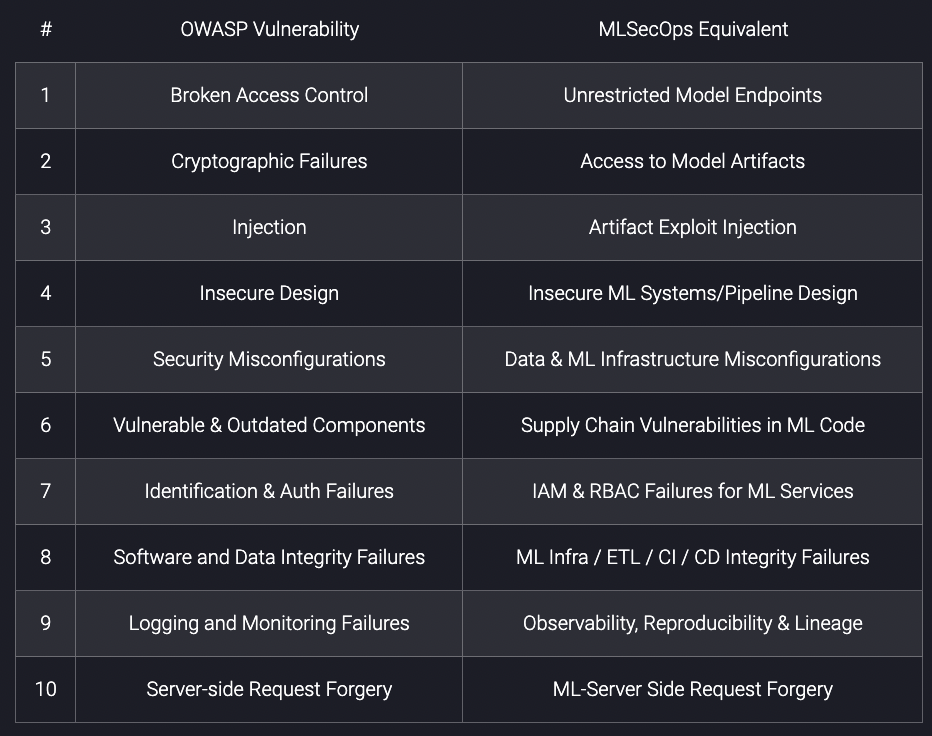
The MLSecOps Top 10 | 11 min | MLOps | The Institute for Ethical AI & Machine Learning
An initiative that aims to further the field of machine learning security by identifying the top 10 most common vulnerabilities in the machine learning life cycle. It also includes a set of practical hands-on examples of each of these vulnerabilities, as well as the best practices to address them - all the content is available open source.
MLOps' source of knowledge has not yet dried up. BTW, there's an interesting senior position in MLOps at Get in Data available! Check it out here
Why we're leaving the cloud | 6 min | Cloud | David Heinemeier Hansson | HEY Blog
Renting computers is (mostly) a bad deal for medium-sized companies with stable growth, like Basecamp. The savings promised in reduced complexity never materialized.
The cloud excels at two ends of the spectrum:
- The first end is when your application is so simple and low traffic that you really do save on complexity by starting with fully managed services.
- The second is when your load is highly irregular. When you have wild swings or towering peaks in usage. When the baseline is just a sliver of your largest needs. Or when you have no idea whether you need ten servers or a hundred.
The Next Generation Of All-In-One Data Stacks | 11 min read | Data Stack | Ben Rogojan | Seattle Data Guy Blog
Is the modern data stack even modern?
Isn’t it just a piecemeal of components from solutions we have known forever like SAP or Informatica?
Isn’t it just an unbundled version of Airflow?
All-In-One Data Stacks rises.
Ben shares examples of all-in-one solutions: Incorta, Keboola, Nexla, Mozart Data, Rivery.
Snowflake acquires stake in OpenAP to set up data clean room for advertisers | 4 min read | Snowflake | Shubham Sharma | VentureBeat Blog
The ad-tech firm partnered with Snowflake and announced the plan to launch a dedicated clean room solution called OpenAP data hub.
TOOLS & TUTORIALS
Cube: API-First Business Intelligence | 5 min | BI
A very nice semantic layer tool that is open source. Top features:
- integration with dbt through: https://cube.dev/blog/dbt-metrics-meet-cube
- sql interface
- caching https://cube.dev/docs/caching
NEWS
Scaling PyTorch models on Cloud TPUs with FSDP | 6 min | ML & MLOps | PyTorch Blog
To support model scaling on TPUs, we implemented the widely-adopted Fully Sharded Data Parallel (FSDP) algorithm for XLA devices as part of the PyTorch/XLA 1.12 release. This FSDP interface allowed us to easily build models with e.g. 10B+ parameters on TPUs and has enabled many research explorations.
Introducing support for Python, dbt’s second language | 5 min | dbt | Cody Peterson | dbt Blog
Python is now officially a second dbt language (v1.3, support for BigQuery, Databricks and Snowflake).
The Python model is something similar to the model expressed in SQL - a series of data transformation methods on dataframe objects returning a single data object to be persisted in the platform. The article also mentions the typical problems that are better solved in Python. It's worth remembering that the set of intended use is narrow compared to the set of possible uses.
PostgreSQL News | 3 min | Big Data | PostgreSQL Blog
The new version of one of the most important databases in the big data ecosystem.
DATA LIBRARY
Data on Kubernetes 2022 | 17 pages | Kubernetes | DoK Community
A report from the DoK Community. Insights from over 500 executives and technology leaders on how data on Kubernetes has a transformative impact on organizations, regardless of size or tech maturity.
Data on Kubernetes has a transformative impact on organizations. Respondents
see a direct link from running DoK and making big gains: the majority of them (83%) attribute over 10% of their revenue to running data on Kubernetes. One-third of organizations saw their productivity increase two-fold.
PODCAST
Project Lightspeed: Next-generation Spark Streaming | 41 min | Streaming | hosts: Ben Lorica; guests: Karthik Ramasamy | The Data Exchange Podcast
41 minutes about faster and simpler tools for new streaming applications.
CONFS EVENTS AND MEETUPS
Art of Scala | 16 November | Scala | Warsaw
A non-commercial conference organized by Scala enthusiasts for Scala engineers.
A Review of the Presentations at the DataMass Gdańsk Summit 2022 | Grzegorz Kołpuć, Maciej Maciejko, Sylwia Kołpuć | GetInData
This conference has passed, but from this review you can get many takeaways. Creme de la creme of DataMass 2022
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
