
ARTICLES
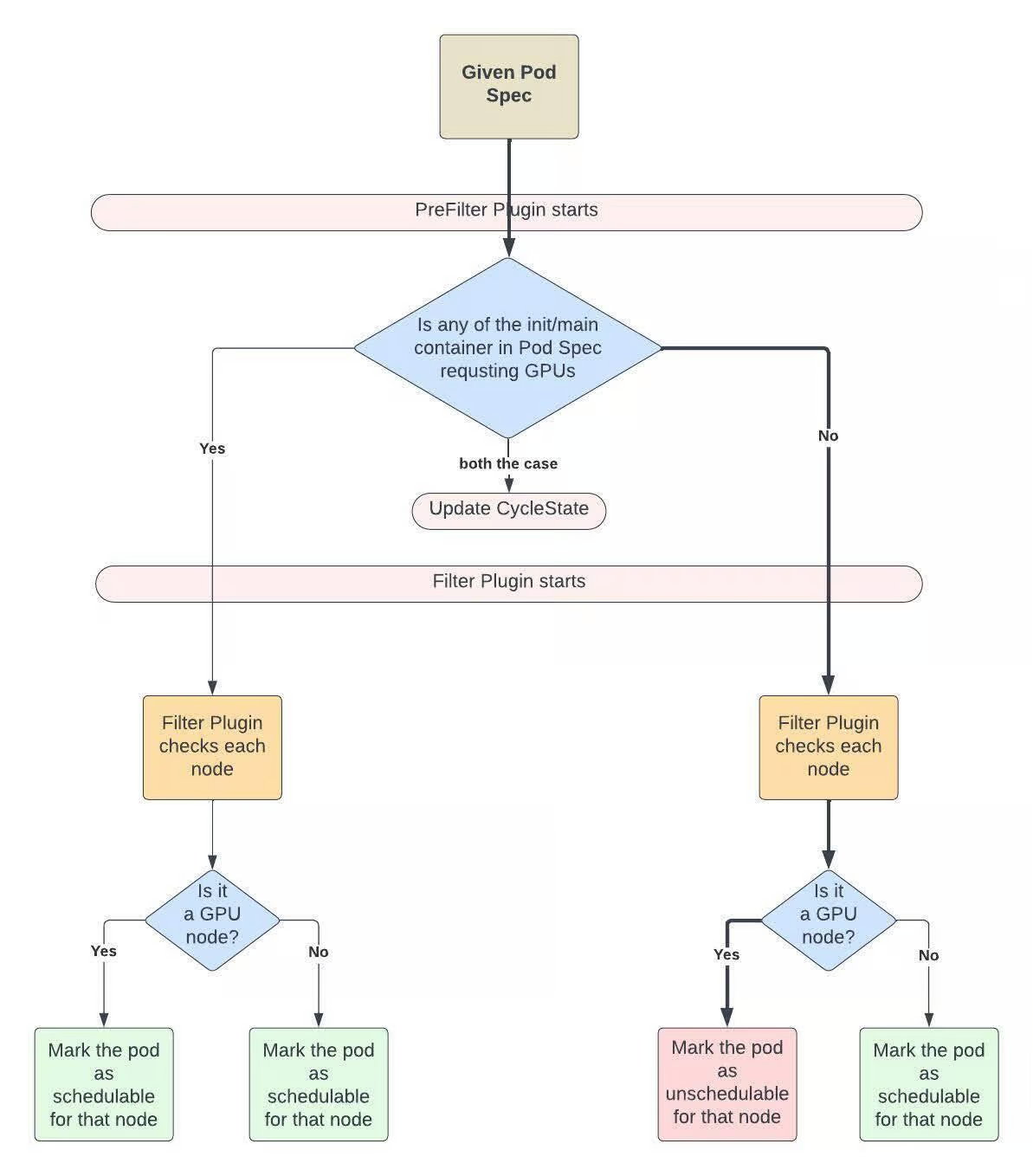
Uber’s Journey to Ray on Kubernetes: Resource Management | 6 min | MLOps | Bharat Joshi, Anant Vyas, Ben Wang, Axansh Sheth, Abhinav Dixit | Uber Engineering Blog
Uber enhanced Kubernetes with custom schedulers and GPU-aware logic to scale multi-tenant Ray workloads for ML efficiently and reliably.
Copilot ask, edit, and agent modes: What they do and when to use them | 6 min | AI | Ashley Willis | Github Engineering
A breakdown of GitHub Copilot’s three modes, showing how to use each for tasks ranging from quick answers to autonomous code changes.
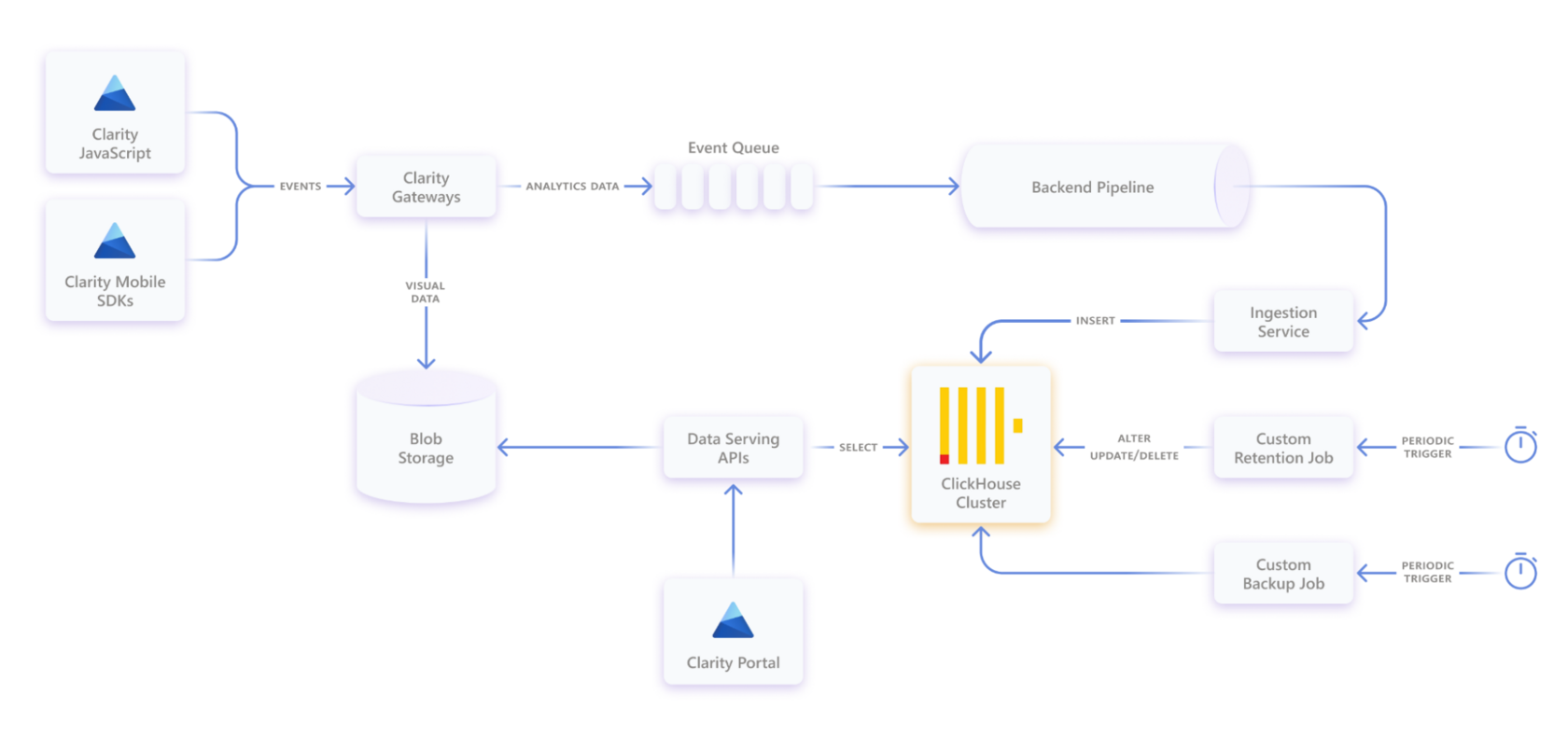
Building a Scalable Analytics Platform: Why Microsoft Clarity Chose ClickHouse | 6 min | Stream Analytics | Omar Bazaraa | Microsoft Clarity Blog
Learn how ClickHouse replaced Spark and ElasticSearch to power real-time analytics at massive scale for Microsoft Clarity.
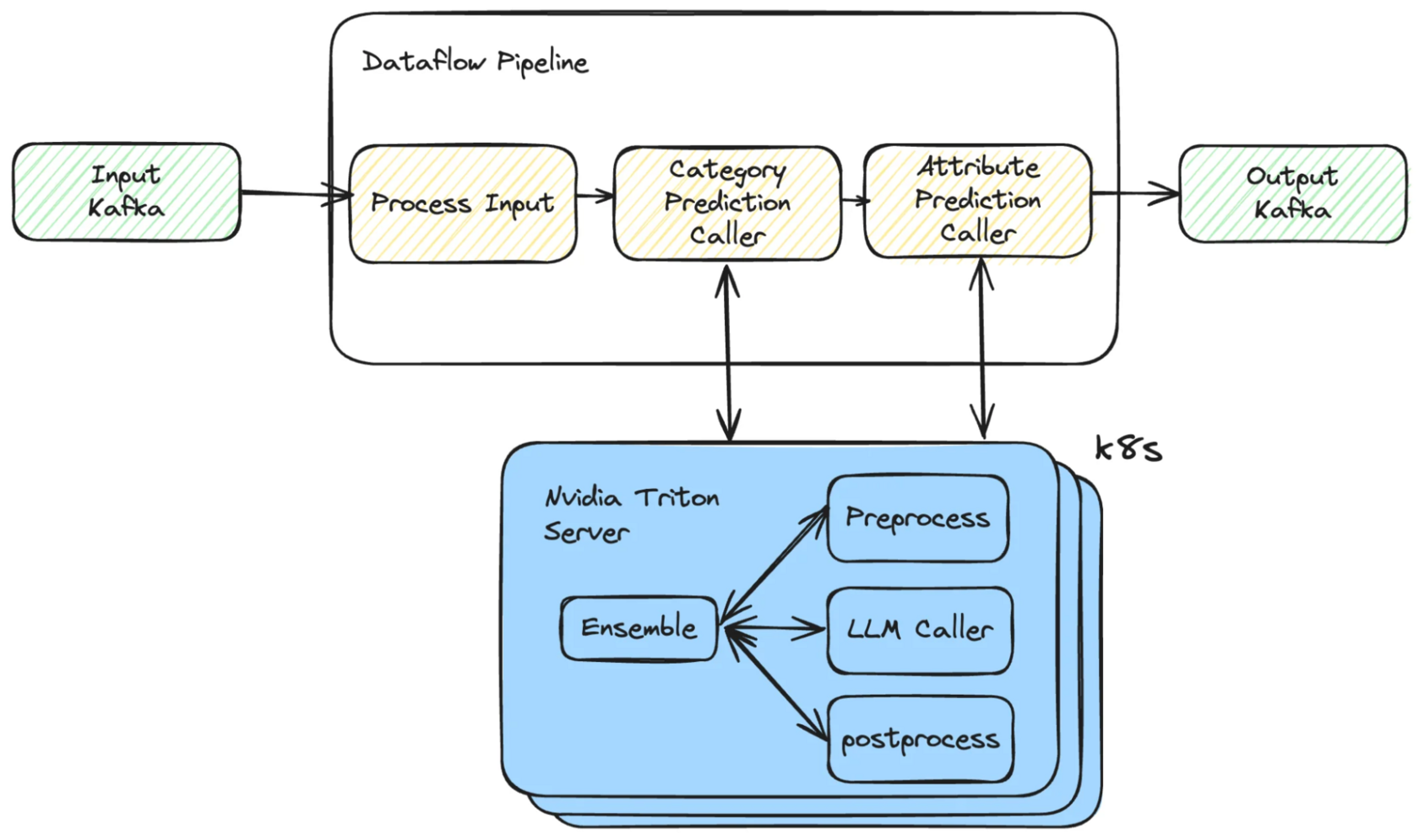
Evolution of Product Classification at Shopify: From Categories to Comprehensive Product Understanding | 5 min | LLM | Shopify Engineering Blog
Shopify details its transition from ML classifiers to a powerful Vision Language Model system for AI-driven product classification at scale.
TUTORIALS
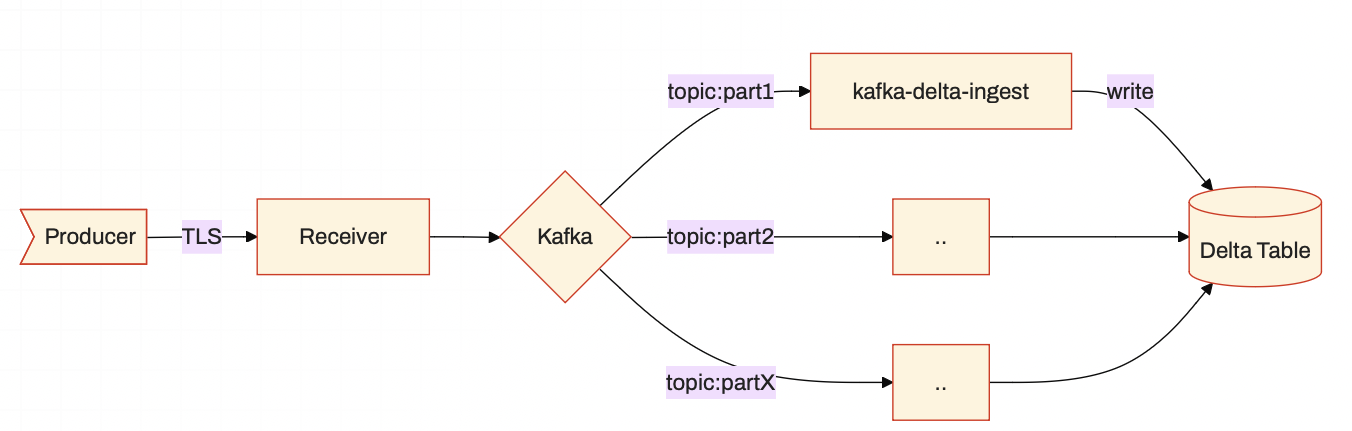
Build more climate-friendly data applications with Rust | 5 min | Data Engineering | R. Tyler Croy | Buoyant Data Blog
A real-world example of replacing Kafka pipelines with Rust, cutting CO₂ emissions and cloud costs by 99%.
TOOLS
GlassFlow for ClickHouse Streaming ETL | Streaming ETL Tool
GlassFlow simplifies building real-time pipelines between Kafka and ClickHouse with built-in support for deduplication and temporal joins.
Kroxylicious | Data Streaming
An open-source Kafka proxy focused on encryption, multi-tenancy, and schema validation—snappy and production-ready.
DATA LIBRARY
LakeVilla: Multi-Table Transactions for Lakehouses | Data Lakehouses | Tobias Götz, Daniel Ritter, Jana Giceva
LakeVilla introduces multi-query transactional guarantees for Iceberg and Delta Lake, with minimal performance impact.
DATA TUBE
The Advent of the Open Data Lake | Data Architecture | 46 min | Julien Le Dem | Apache Iceberg
A talk on how modular open standards like Iceberg and Arrow are reshaping modern, composable data platforms.
CONFS, EVENTS AND MEETUPS
Join us for a deep dive into the data lakehouse storage layer. We'll explore the evolution of file formats like Parquet and Avro, the rise of open table formats such as Delta, Hudi, and Iceberg, and how openness shapes modern data architecture. Learn performance tuning tips like partitioning and Z-ordering, plus key topics like deletion vectors, encryption, and GDPR-compliant lifecycle policies. The session includes a live demo.
Topics include:
- What is Cloud Object Storage?
- Overview of Big Data File Formats
- Columnar vs. Row-Oriented: Parquet and Avro
- Benefits of Delta, Hudi, and Iceberg
- Optimizing Files for Query Performance
PINNACLE PICKS
Your last week top picks:
How I (Barely) Survived Setting Up Polaris As An Iceberg Rest Catalog | 4 min | Data Engineering | Daniel Beach | Personal Blog
A raw, honest take on setting up Polaris as an Iceberg REST catalog in production. Spoiler: it hurt, but it worked.
Starlake: Open Source Data Integration & ETL Platform | 4 min | Data Engineering | Starlake Blog
Starlake lets you define extract, load, transform, and test tasks in YAML, and auto-generates DAGs—like Terraform for your data pipelines.
PyCharm| 3 min | Data Engineering | Valerie Andrianova | jetbrains Blog
PyCharm merges Community and Pro editions into a single product with a free Pro trial and built-in Jupyter support for all.
________________________
Have any interesting content to share in the DATA Pill newsletter?
