
ARTICLES
How Canva saves millions annually in Amazon S3 costs | 6 min | Data Engineering | Josh Smith | Canva Developers
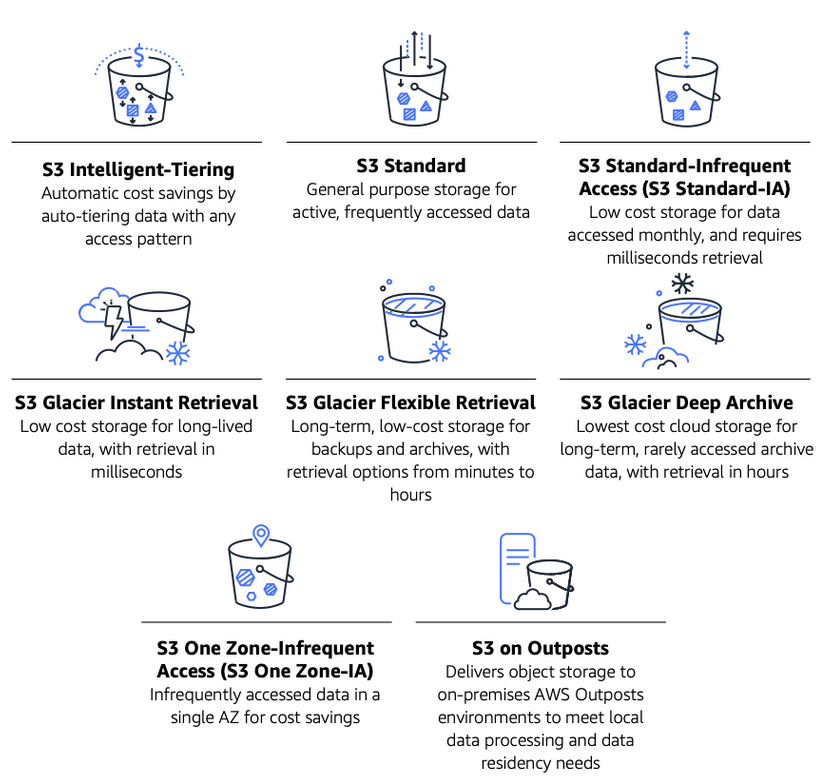
Dive into a detailed explanation of how to analyze S3 usage data, determine the most cost-effective storage class for your objects, and automate the process of moving objects between storage classes. The tips and strategies presented in this post can help you minimize the AWS costs while still providing reliable and scalable storage solutions.
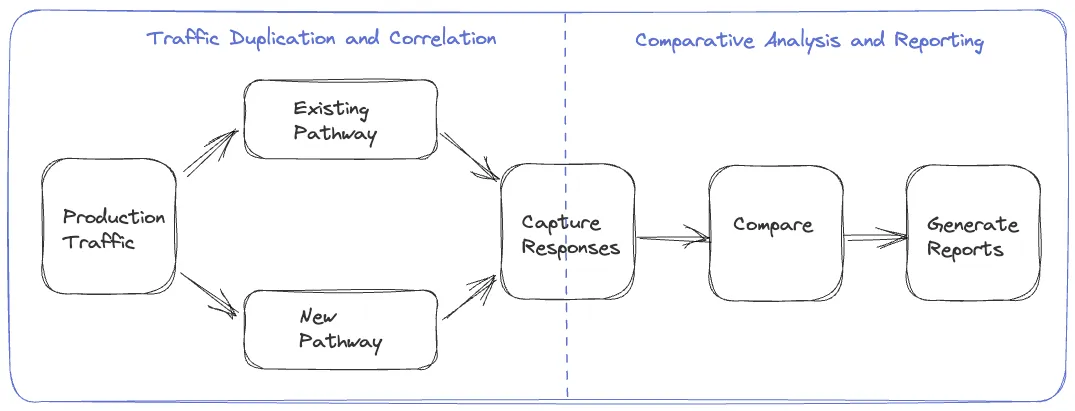
Migrating Critical Traffic At Scale with No Downtime — Part 1 | 10 min | Data Engineering | Shyam Gala, Javier Fernandez-Ivern, Anup Rokkam Pratap, Devang Shah | Netflix TechBlog
This blog post provides a detailed analysis of replay traffic testing, a versatile technique the Netflix team have applied in the preliminary validation phase for multiple migration initiatives.
The Full Story of Large Language Models and RLHF | 17 min | Deep Learning | Marco Ramponi | AssemblyAI Blog
This guide covers the journey of large language models, from foundational ideas to the latest advancements, and how RLHF aligns them with human values.
Observability on Kubernetes - lessons learned | 6 min | Data Engineering | Piotr Mossakowski | GetInData | Part of Xebia Blog
More than half of GetInData active projects are those where they manage observability stacks completely. They design, implement and maintain monitoring, logging and tracing of our application stacks.
Piotr shares lessons learned on running observability stacks on Kubernetes like:
- Storage class with ReadWriteMany access mode (RWX) (highly recommended)
- Configuration changes should be verified and applied automatically
- Choosing reliable, feature reach tools able to support multiple architectures
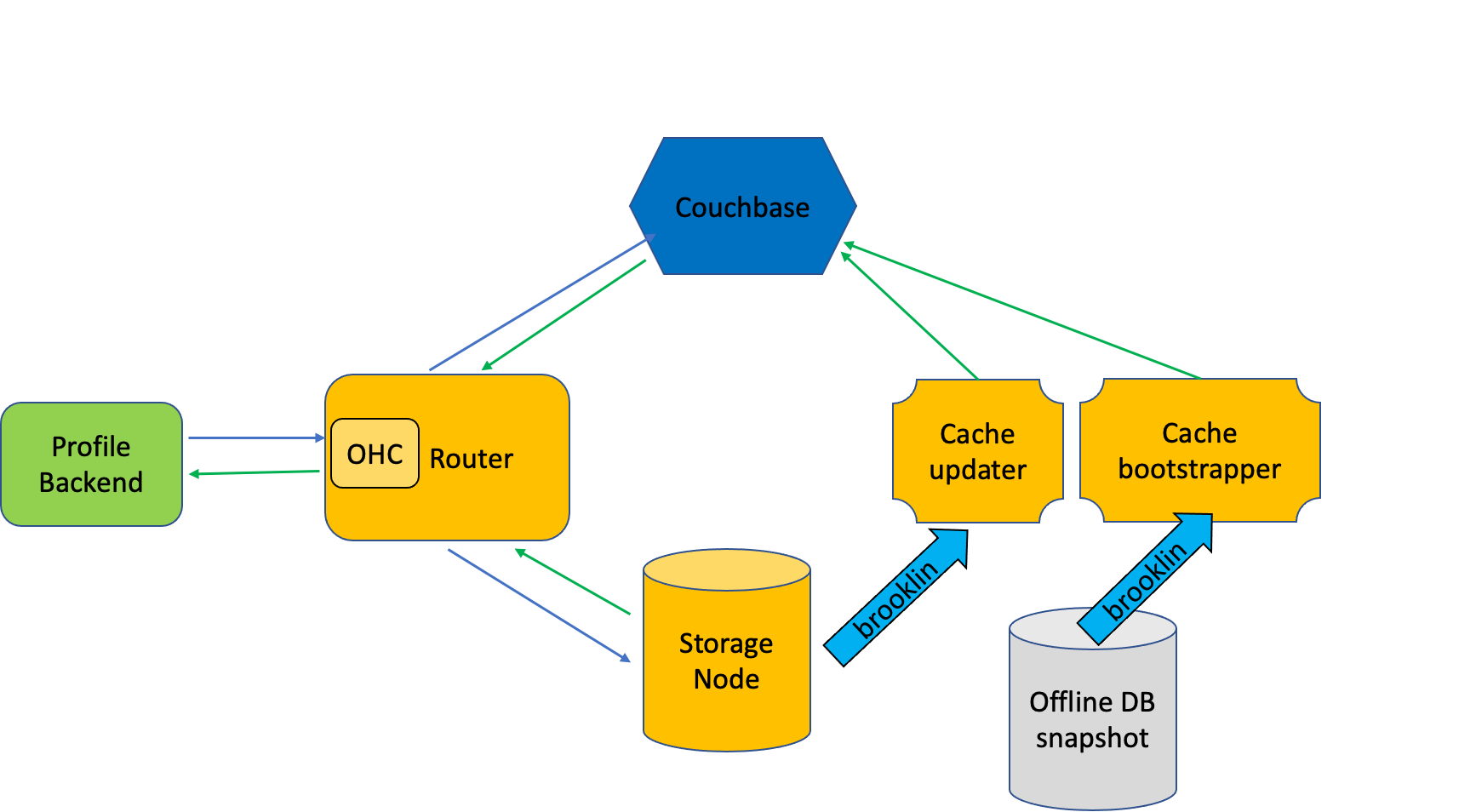
Upscaling LinkedIn's Profile Datastore While Reducing Costs | 7 min | Data Engineering | Estella Pham, Guanlin Lu | Linkedin Engineering Blog
Dive into LinkedIn's efforts to upscale their profile datastore while reducing costs. The company's engineers utilized a combination of hardware improvements and algorithmic optimizations to achieve significant cost reductions. The text also provides insight into the challenges and strategies involved in maintaining a high-performance datastore at scale.
Ultimately, the LinkedIn team’s efforts resulted in improved system reliability and reduced operational costs, demonstrating the importance of continuously improving technology infrastructure.
Google Cloud advances generative AI at I/O: new foundation models, embeddings, and tuning tools in Vertex AI | 8 min | ML and AI | June Yang | Google Tech Blog
More about the launch of several new AI models by Google Cloud, which are designed to help businesses automate key tasks such as automating customer service and analyzing customer feedback. These new models are part of a wider initiative by Google Cloud to make it easier for businesses to leverage the power of AI and machine learning, and they represent a significant step forward in the company's efforts to bring cutting-edge technologies to the enterprise market. Google Cloud has also opened up its Generative AI Studio, which allows developers to experiment with and explore different AI techniques and models.
How Generative AI Will Revolutionize Data Catalogs | 4 min | AI | Chad Barendse | Data Governed Blog
Chad overviews some of the key limitations of traditional data catalogs. Read how you can disrupt the data cataloging industry and how you will have a competitive advantage in managing data.

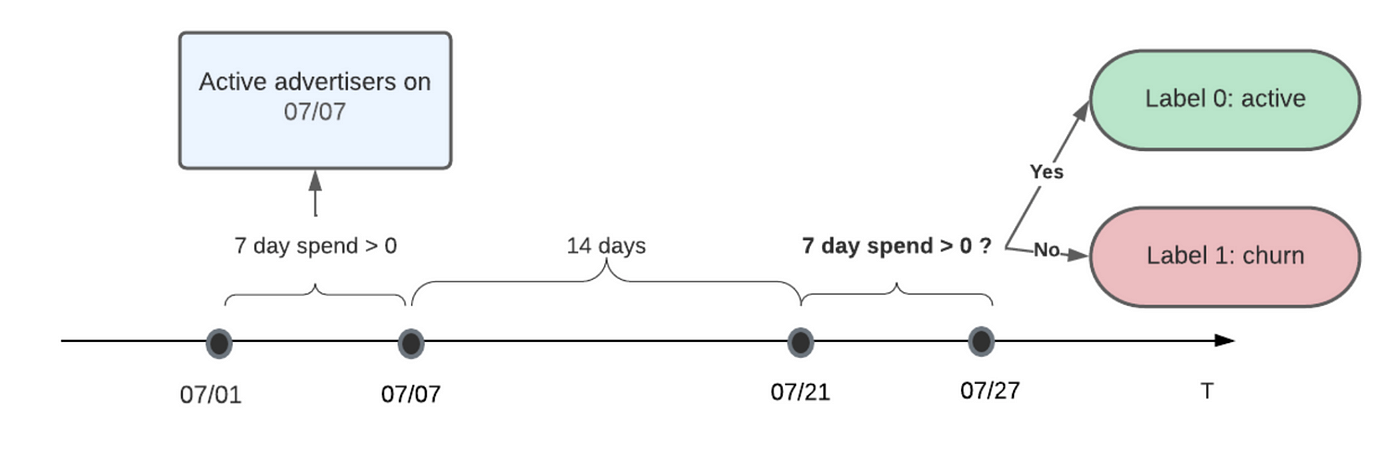
An ML based approach to proactive advertiser churn prevention | 6 min | ML | Erika Sun, Ogheneovo Dibie | Pinterest Engineering Blog
In this blog post, the Pinterest team describes a Machine Learning (ML) powered proactive churn prevention solution that was prototyped with our small & medium business (SMB) advertisers. Results from our initial experiment suggest that we can detect future churn with a high degree of predictive power and consequently empower our sales partners in mitigating churn. ML-powered proactive churn prevention can achieve better results than traditional reactive manual effort.
TUTORIAL
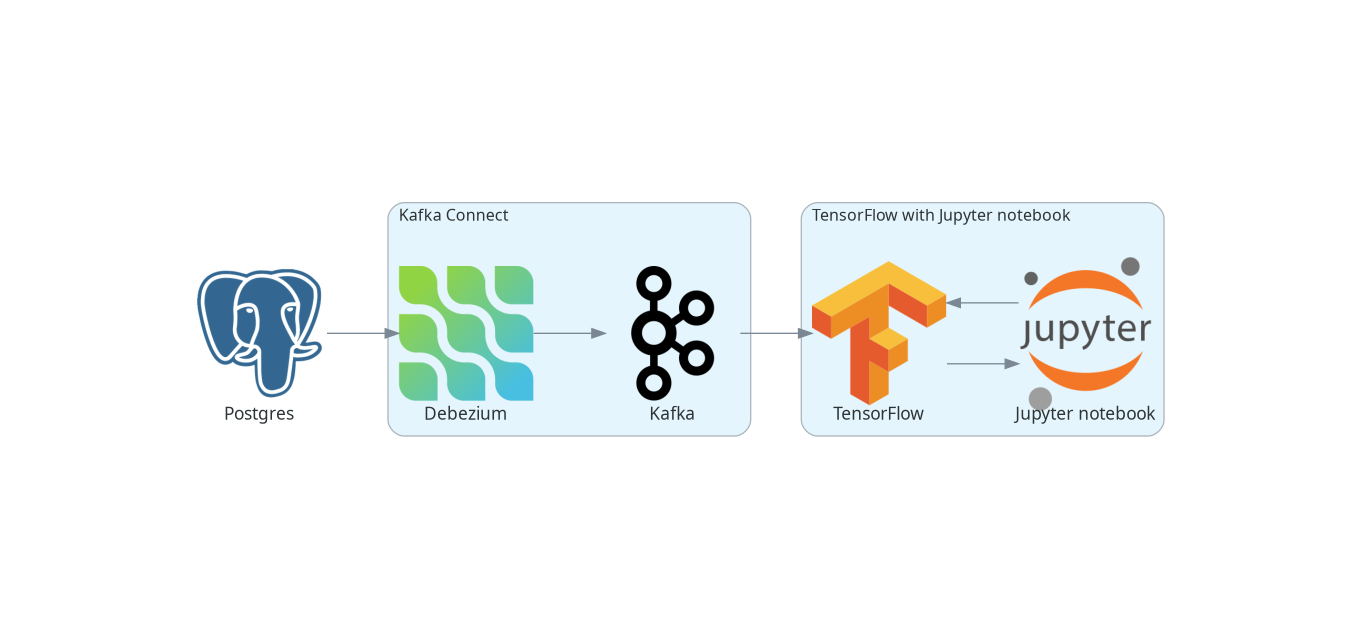
Image classification with Debezium and TensorFlow | 8 min | ML | Vojtěch Juránek | Debezium Blog
In this one, Vojtěch discusses how the recent success of ChatGPT has created a new wave of interest in AI and machine learning. While ML frameworks like TensorFlow and PyTorch have made writing ML models more accessible, data set preparation can still be challenging. The blog explores the use of Debezium, a change data capture tool, in machine learning pipelines, and looks at how to stream data into TensorFlow for recognizing handwritten digits. You will also read about Debezium's support for single message transforms and its ability to deliver records to multiple message brokers.
TOOLS
Bytewax.io | Bytewax
Build streaming data applications easily in Python. Open source framework and distributed stream processing engine. Build streaming data pipelines and real-time apps with everything you need: recovery, scalability, windowing, aggregations, and connectors.
NEWS
Spark Connect Available in Apache Spark 3.4 | 3 min | Data Engineering | Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin and Kris Mo | Databricks Blog
Revolutionize Apache Spark with this new technology now available. The new connector tool is designed to simplify data movement and improve data performance between Apache Spark and Delta Lake. It will enhance the capabilities of Spark and Delta Lake, making it easier and faster to work with large-scale data sets.
PODCASTS
ChatGPT and the OpenAI Developer Ecosystem | 55 min | AI | host: Adel Nehme guest: Logan Kilpatrick | DataFramed
- Discover the power of ChatGPT with OpenAI's Logan Kilpatrick in this AI series episode. Learn about ChatGPT's plugins, image input features, and its integration into our daily lives. Gain valuable tips on how to get better responses and successfully integrate ChatGPT into your organization's product. Join the storm and explore the practical applications of AI in our lives.
Revolutionizing B2B: Unleashing the Power of AI and Data | 43 min | AI | host: Ben Lorica guest: Simon Chan | The Data Exchange
Let’s explore the evolution of AI, cloud computing, and business collaboration tools, revealing how a new generation of generative AI technologies is enabling applications to generate content and drive transformative innovation across various industries.
Interview highlights:
- MLOps and Enterprises: lessons learned at Salesforce.
- Categories that Simon is actively investing in right now.
- Startups that focus on specific verticals.
- AI infrastructure and data engineering opportunities.
CONFS EVENTS AND MEETUPS
DATA + AI SUMMIT 2023 | 26-29th June | Online & San Francisco
Large Language Models (LLM) are taking AI mainstream. Join the premier event for the global data community to understand their potential and shape the future of your industry with data and AI.
Generative AI: Changing How Business Innovates and Operates | 31th May | Webinar
This complementary webinar explores multiple use cases that drive adoption in their early adopter customer base to provide product leaders with insights into the future of generative AI-powered businesses, and the potential generative AI holds for driving innovation and improving business processes.
- Discover the core areas of generative AI-enabled solutions emerging in the market
- Identify user expectations for generative AI
- Find out how your organization can successfully use generative AI-powered solutions
Leveraging Google Cloud's Large Language Models and Generative AI Services | 17th May | Amsterdam
Join this seminar to learn how to leverage the power of Google's LLMs for your business. In a few hours, you can learn how to effectively use LLMs for your organization. During the seminar, we will explore the developments that led to the rise of Generative AI and dive into different types of use cases.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
