
ARTICLES
MIT Says 95% of AI Pilots Fail. McKinsey Explains Why. Agentic Engineering Shows How to Fix It| 8 min | AI Strategy | Yi Zhou | Personal Blog
Most GenAI pilots stall after demos. McKinsey’s rules for survival and Zhou’s Agentic Engineering framework aim to make AI scalable and sustainable
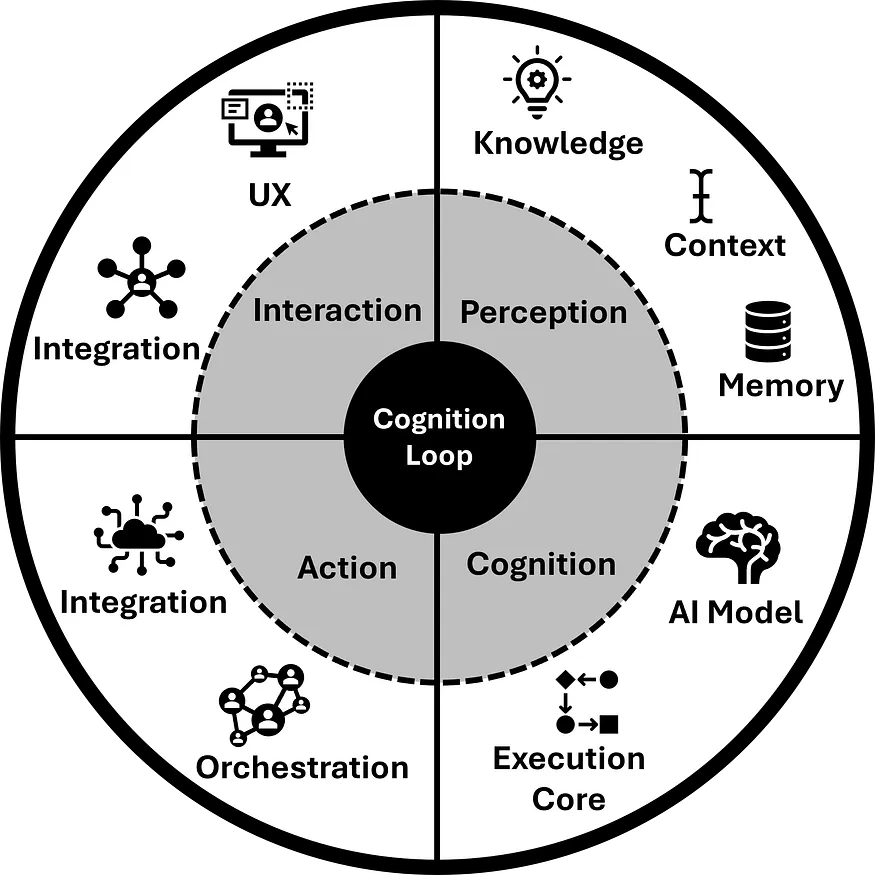
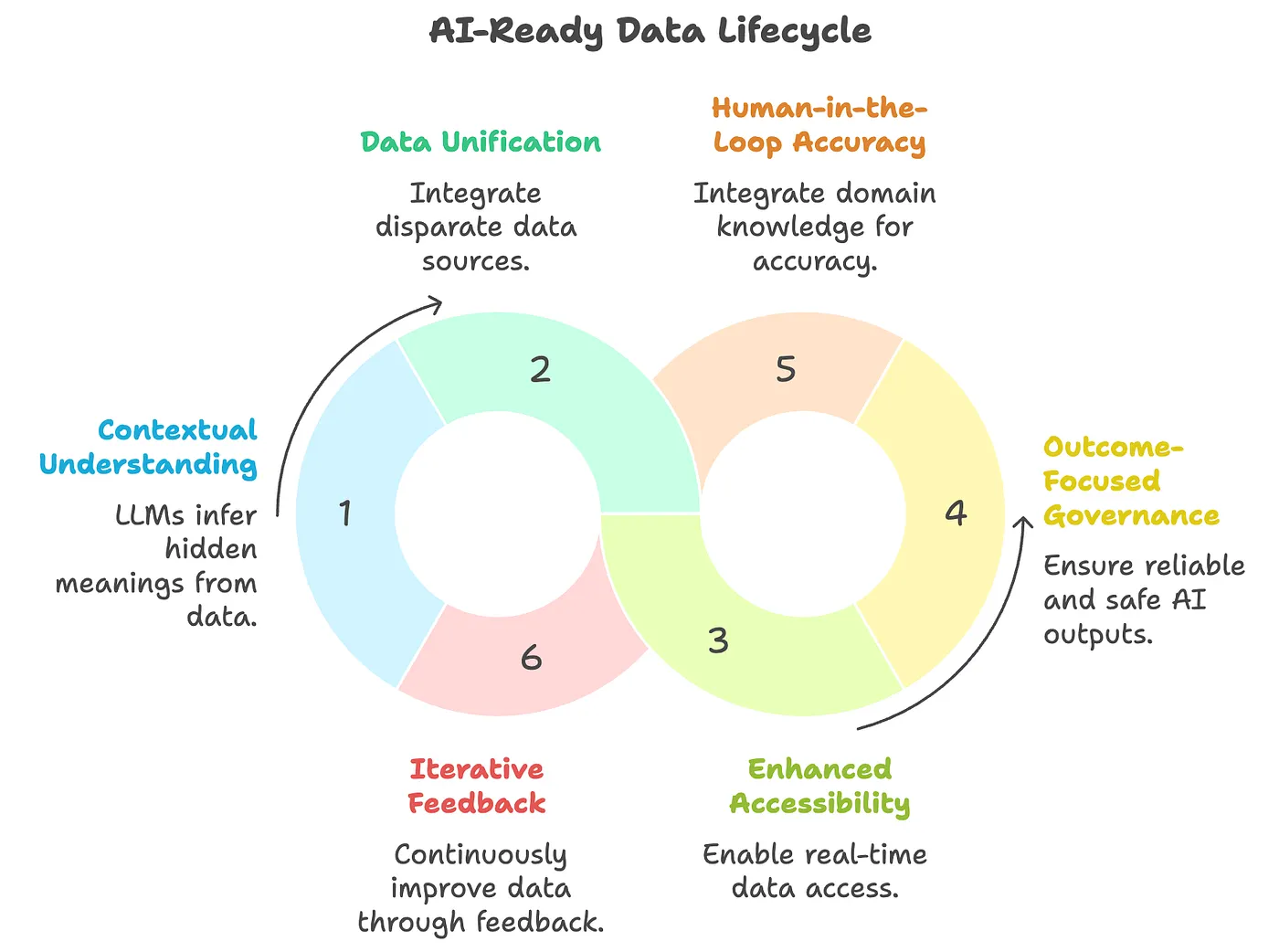
Is Your Data “AI-Ready”? Why Good Data Isn’t Enough Anymore | 5 min | Data Infrastructure | Sanjeev Mohan | Medium
Six pillars of AI-ready data: contextual, unified, accessible, governed, accurate, and iterative. Clean data alone is not enough.
DuckDB Can Be 100x Faster Than Spark | 7 min | Data Engineering | Zach Wilson | DataExpert.io
Benchmarking shows DuckDB crushing Spark on 500M+ row datasets, highlighting when a lightweight in-memory engine outperforms a multi-node cluster.
Kafka Outages at PagerDuty: What Happened and How We’re Improving | 6 min | DevOps | PagerDuty Engineering Blog
A post-mortem of a major Kafka outage with root cause, monitoring gaps, and fixes to strengthen resilience.
TUTORIALS
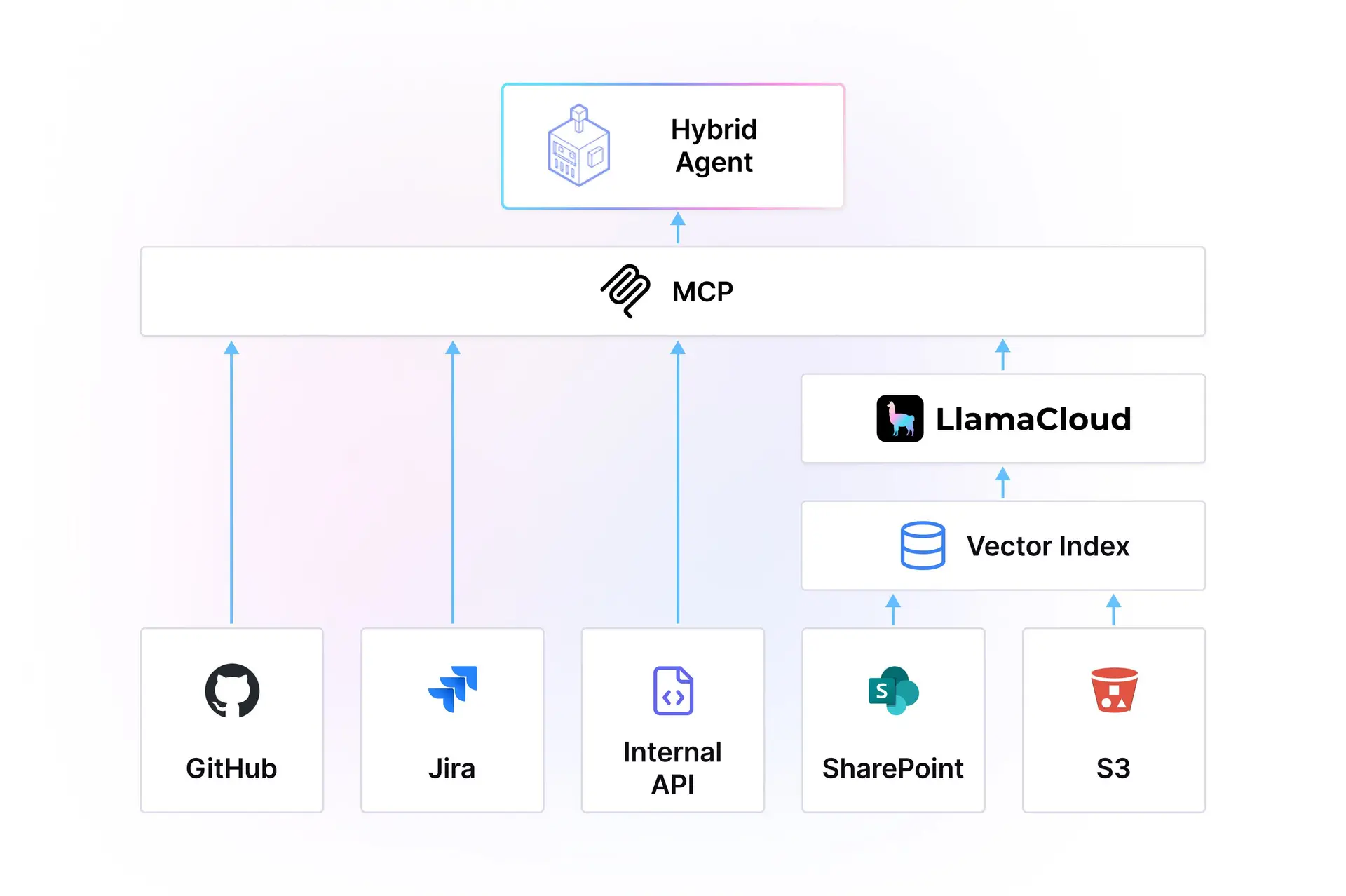
Adding Document Understanding to Claude Code | 7 min | AI Agents | Jerry Liu | LlamaIndex Blog
How Claude Code gains PDF and DOCX understanding with LlamaIndex, unlocking real enterprise workflows.
DATA LIBRARY
Data & AI Monitor Report 2025–2026 | AI & Data Strategy | Xebia
Industry benchmarks on GenAI adoption, MLOps maturity, and modernization trends shaping the next two years.
TOOLS
Vortex| Data Infrastructure
An open, next-gen columnar file format optimized for analytics and AI, with modern compression and extensibility.
JupyterLite | Dev Tool
A full JupyterLab running in the browser via WebAssembly. Ideal for demos, lightweight analysis, and docs.
K8s-native integration of Spark History Server for monitoring jobs and logs within Kubeflow pipelines.
DATA TUBE
Building Reliable Support Agents Using the Effect Typescript Library | 7 min | AI | Michael Fester | AI Engineer
A demo-driven talk on building LLM support agents with Effect, covering architecture, tradeoffs, and reliability.
EVENTS, CONFS, AND MEETUPS
Clash of the Data Catalogs – Market Leaders vs. Challengers | 7th October | Online
Join Marek Wiewiórka and Radosław Szmit as they debate the strengths and trade-offs of vendor vs. open-source data catalogs in real-world data lakehouse.
PINNACLE PICKS
Your last week top picks:
Online Feature Store for AI and ML with Apache Kafka and Flink | 8 min | Streaming & AI | Kai Waehner | Personal Blog
Step-by-step on building low-latency feature pipelines for consistent ML training and serving.
An open-source platform that merges streaming and OLAP for real-time analytics with SQL queries and time travel.
I have built around 300 agents, worked at 5 startups. Here's what I learnt about AI Agent | 8 min | AI Agents | Sai Yashwanth | Personal Blog
Practical takeaways from building agents at five startups, covering prompt design, tool use, memory, and user feedback loops.
________________________
Have any interesting content to share in the DATA Pill newsletter?
