
ARTICLES
Apache Celeborn — Shuffle Service for Spark | 5 min | Data Engineering | Amit Singh Rathore | Dev Genius Blog
Check out the DevGenius blog post that introduces Apache Celeborn Shuffle Service, a fresh addition to Apache Spark. The article dives into the advantages and capabilities of this feature, which focuses on enhancing shuffle performance and minimizing memory usage in Spark applications. By delegating shuffle operations to a dedicated service, Celeborn boosts the scalability and efficiency of Spark clusters, leading to optimized performance for data-intensive workloads.
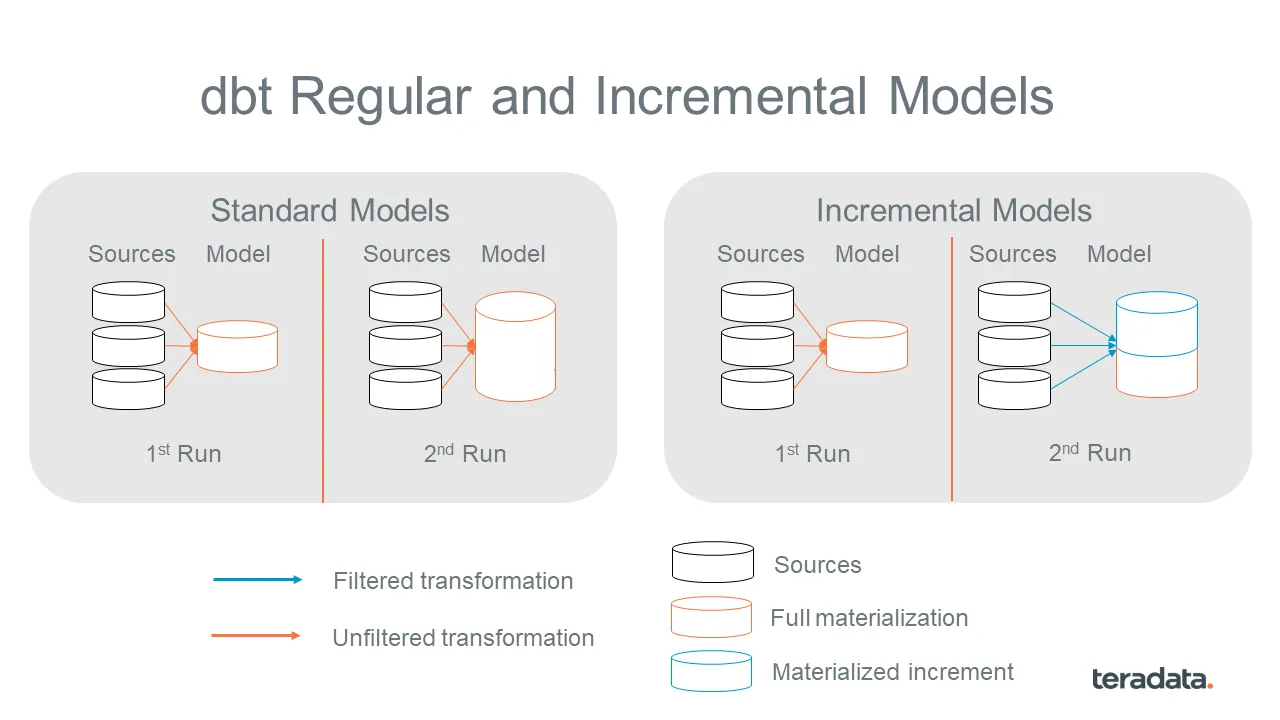
Optimize Your dbt Incremental Models with Teradata Vantage™ Temporal Tables | 10 min | Data Engineering | Daniel Herrera | Teradata Blog
This one explores the implementation of dbt incremental models with Teradata Vantage temporal tables, focusing on the sample ELT process of the fictional store Teddy Retailers. Dive into and learn more about achieved incremental ingestion of newly inserted or updated data into our dbt models.
Data Documentation 101: Why? How? For Whom? | 6 min | Data Management | Marie Lefevre | Towards Data Science Blog
Marie provides a comprehensive overview of data documentation, covering its importance, methods and intended audience. Dig into the significance of data documentation in enabling effective data management, collaboration and reproducibility. It offers insights and practical guidance on creating thorough and accessible data documentation for various stakeholders.
Semi-supervised learning on real-time data streams | 6 min | Streaming | Kosma Grochowski | GetInData | Part of Xebia Blog
Let's dive into semi-supervised learning in the context of real-time data streams. It explores how this approach can be utilized to enhance machine learning models by incorporating unlabeled data alongside labeled data. By leveraging semi-supervised learning techniques, organizations can make the most of their real-time data streams and achieve improved accuracy and efficiency in their machine learning applications.
Exploring 8 Futuristic Databases to Watch in 2023 | 11 min | Software Engineering | Siddhant Varma | Semaphore Blog
This article explores eight futuristic databases to keep an eye on in 2023. It discusses their advanced features and capabilities, highlighting the benefits and challenges of using distributed architectures. The databases mentioned include FaunaDB, PlanetScale, Dolt and Xata, along with others, each offering unique advantages and potential applications for users seeking cutting-edge data management solutions.
TUTORIALS
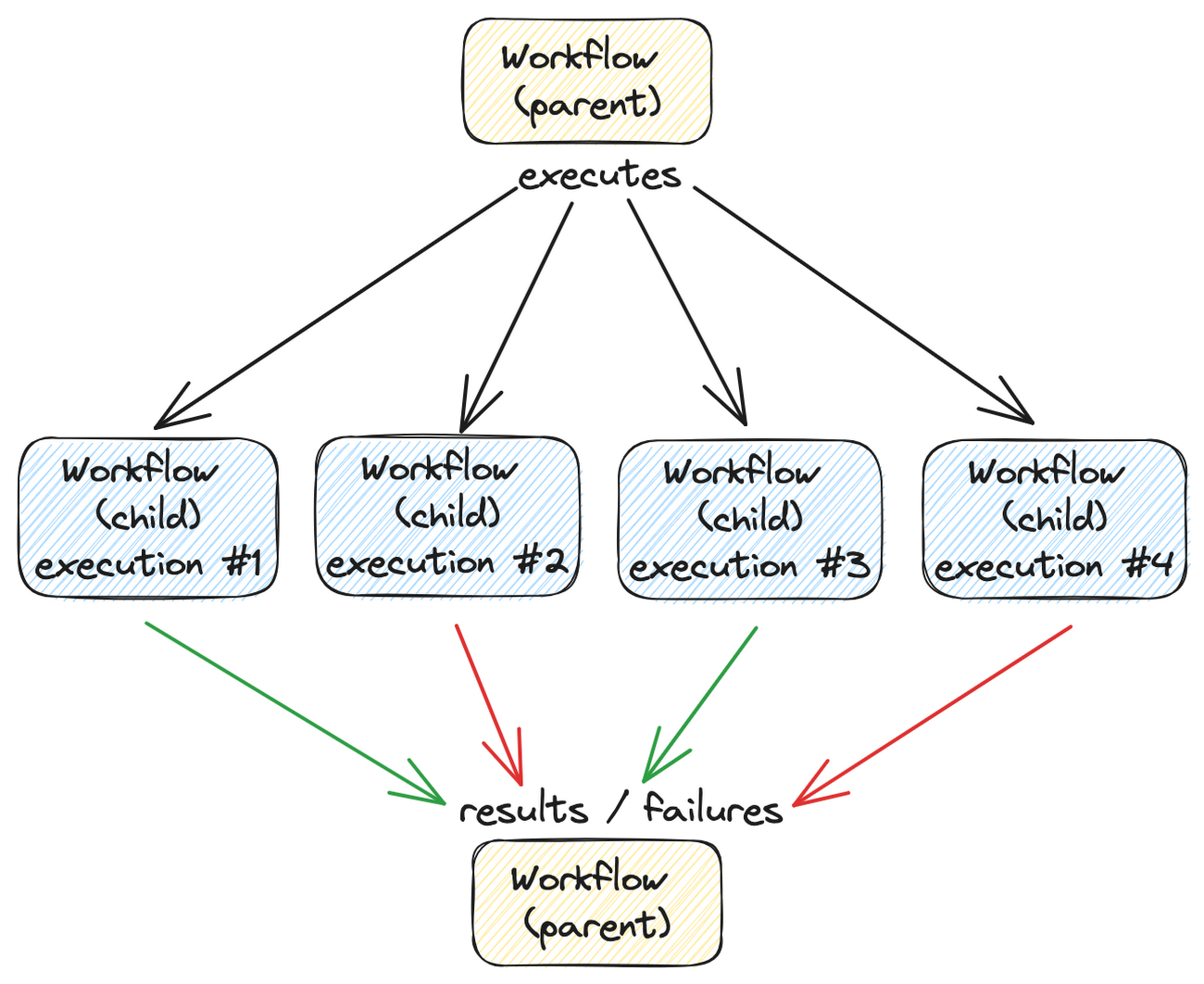
Workflows executing other parallel workflows: A practical guide | 9 min | Data Engineering | Mete Atamel | Google Cloud Blog
Delve into parallel task execution using parent and child workflows. This blog explores how this setup can enhance productivity and streamline processes, providing a practical guide on implementing this approach. By leveraging parent and child workflows, users can optimize task execution and improve overall efficiency in their application development workflows.
How to Build a Credit Data Platform on the Databricks Lakehouse | 14 min | Data Platform | Nuwan Ganganath, Boris Banushev, Ricardo Portilla | Databricks Blog
The databricks team discusses how to build a credit data platform that unifies data processes and people using lakehouse architecture. It highlights the benefits of leveraging the lakehouse model to streamline data operations, enable collaboration and enhance data quality in the credit industry. By adopting this approach, organizations can achieve a unified, scalable and efficient data platform tailored to the unique requirements of credit data management.

TOOLS
MLflow 2.4.2 | 3 min | ML
MLflow 2.4.2 is a patch release containing the following bug fixes and changes. Need some examples? Here they are:
- Add question-answering and summarization examples and docs with LLMs.
- Add compatibility for legacy transformers serialization.
- Add support for listing artifacts in UC model registry artifact repo.
- Include resources for recipes in mlflow-skinny.
and much more!
AirFlow 2.6.3 | 2 min | Data Engineering
Another one release is from AirFlow, an open-source platform for developing, scheduling and monitoring batch-oriented workflows. Some bugs are fixed right now:
- Use linear time regular expressions
- Fix triggers alive check and add a new conf for triggerer heartbeat rate
- Sanitize DagRun.run_id and allow flexibility
- Add the trigger canceled log
- Fix behavior of LazyDictWithCache when import fails
Sweep AI | 3 min | AI
Sweep is an AI junior developer that transforms bug reports & feature requests into code changes.
Describes bugs andsmall features, and refactors as you would to a junior developer and Sweep:
- reads your codebase
- plans the changes
- writes a pull request with code
DATA TUBE
The data professional in the era of GenAI | 26 min | Generative AI | Firat Tekiner, Sören Petersen | Google Cloud Tech
Find out more about the convergence of DataOPS, MLOPS, and LLMs, exploring the growing relevance of data analytics and machine learning applications. Discover how Data and MLOps play a pivotal role in the success of machine learning, relying on a robust data ecosystem. Firat and Sören also showcase real-world examples and highlight the value that generative AI applications can bring to organizations within their data analytics ecosystem.
PODCAST
An Open Source Data Framework for LLMs | 29 min | Generative AI | Ben Lorica, Jerry Liu | The Data Exchange Podcast
Let’s listen to a talk with Jerry, CEO and co-founder of LlamaIndex, a framework that empowers developers to tailor LLMs to their specific needs, improve performance and ensure data compliance, ultimately enhancing the use of AI technologies in various applications.
Interview highlights:
- Prototypical uses cases
- How does LlamaIndex integrate an LLM input prompt and provide context with my private data?
- The emerging stack around embedding-based lookups
- LlamaIndex and next-gen AI applications
- Metadata filters
- Revisiting the Modern Data Stack
and much more.
CONFS EVENTS AND MEETUPS
Staying a Step Ahead Managing Credit Risk Portfolio at ING With Generative AI | Webinar | 10:00 am CEST | 20th July
Join this insightful and engaging event about ING's journey to empower business use cases using Generative AI, such as Large Language Models (LLMs).
Why should you join?
- The webinar will provide a technical introduction to Generative AI and LLMs, exploring their capabilities and limitations in different levels of applications;
- You will become familiar with Google Cloud's Generative AI Studio;
- In addition, you will learn how ING is leveraging the power of LLMs to automate the ingestion of multi-language news articles and generate high-level insights for informed decision-making.
Databricks on Google Cloud Lakehouse Labs | Online Training | 09:00 PT | 20th July
Don't miss out on this live, hands-on workshop. Discover the power of the data lakehouse, an innovative data architecture that combines data warehouses and data lakes. Join Databricks and Google to learn how to effectively implement a comprehensive data analytics, engineering and the science life cycle on the lakehouse using Databricks on Google Cloud.
This live, virtual hands-on lab will teach you how to:
- Access all your data — structured, semi-structured, unstructured — with a lakehouse
- Use Databricks SQL to query and visualize data in your lakehouse
- Train models and create predictions with Databricks on Google Cloud
- Track experiments and tune hyperparameters with MLflow
- Deploy and serve models with MLflow and other Google Cloud services
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
