
ARTICLES
Navigating the Data Mesh: Organizational Challenges and Opportunities | 10 min | Pierre-Alain Genilloud | Data Engineering | ELCA IT
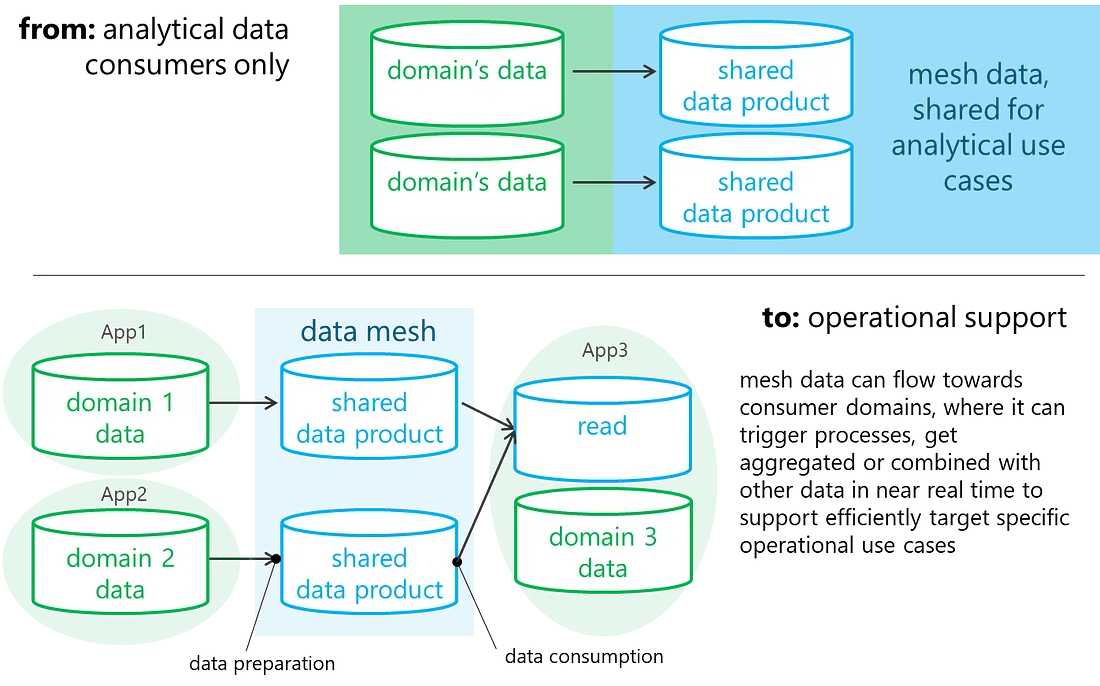
Most of you without doubt have heard of the Data Mesh. Let’s take a deeper look at some implications in terms of organization and agility, challenges and opportunities. Also, let’s discuss the opportunities and open questions brought by the Data Mesh:
Opportunities:
- empowers domains in the provision of their data, and improves recognition of their efforts
- accelerates the introduction of new valuable data
- lets individual domains build their analytics on their own
- facilitates integration with operational use cases
Open questions:
- which technology is required for data preparation?
- which technology is required to support data consumption?
dbt run real-time analytics on Apache Flink. Announcing the dbt-flink-adapter! | 23 min | Grzegorz Liter, Krzysztof Zarzycki, Michał Soszko |Data Analytics | GetInData| Part of Xebia Blog
We would like to announce the dbt-flink-adapter, that allows running pipelines defined in SQL in a dbt project on Apache Flink! Check out the newest blog post and find out:
- what the advantages of dbt and Apache Flink are
- what was the driver for our GetInData Streaming Labs team to create the adapter
- how to build a real-time analytics pipeline.
Also, we deal with the myth that real-time analytics is not worth the cost.
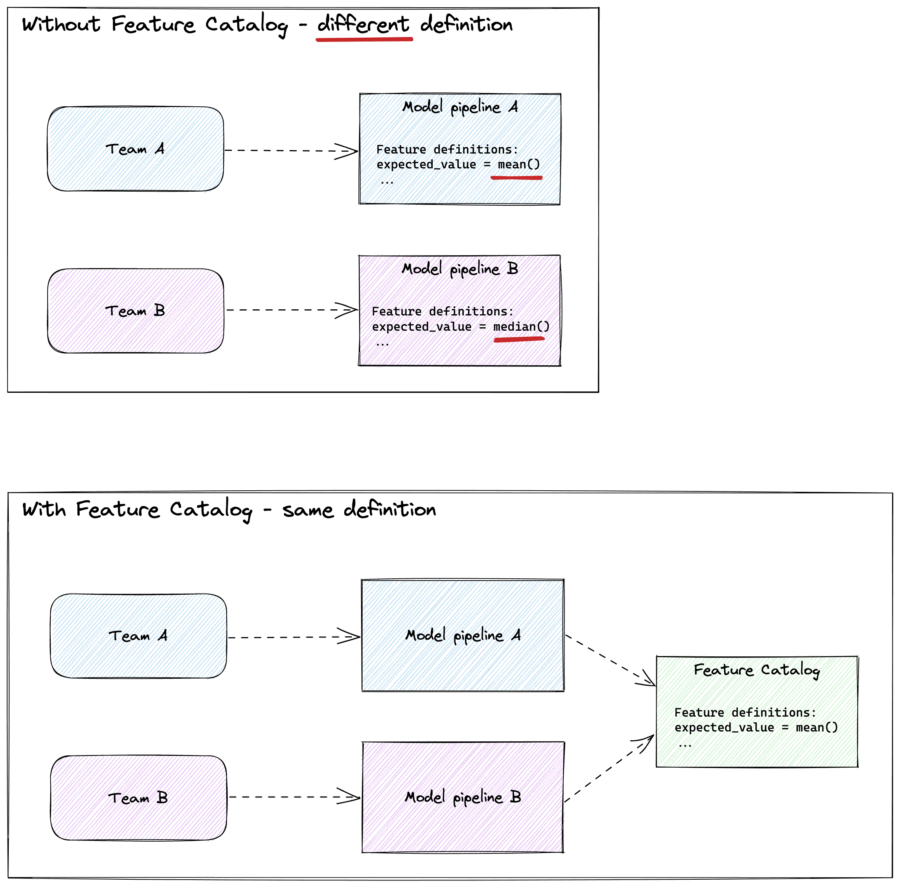
Streamlining Data Science Workflows with a Feature Catalog | 5 min | Roel Bertens | Data Engineering | GoDataDriven | Now Xebia Blog
Dealing with confusion and duplicative work in your data science team can be exhausting. In this post, Roel explores ways to overcome these challenges and improve collaboration, consistency and speed within your data science team. Read about the Feature Catalog that can help data science teams work together better.
Deploying Machine Learning Models Into League Of Legends | 7 min | Ian Schweer | Machine Learning | SeattleDataGuy
Are there any League Of Legends enthusiasts out there? If so, this one should interest you. Ian shares his and his team’s experience with work on deploying ML Models into LoL. In this article, he answers the following questions:
- How they handle in game telemetry
- How they handle models in the service space with feeding detection
- How they handle in game modeling and inferences
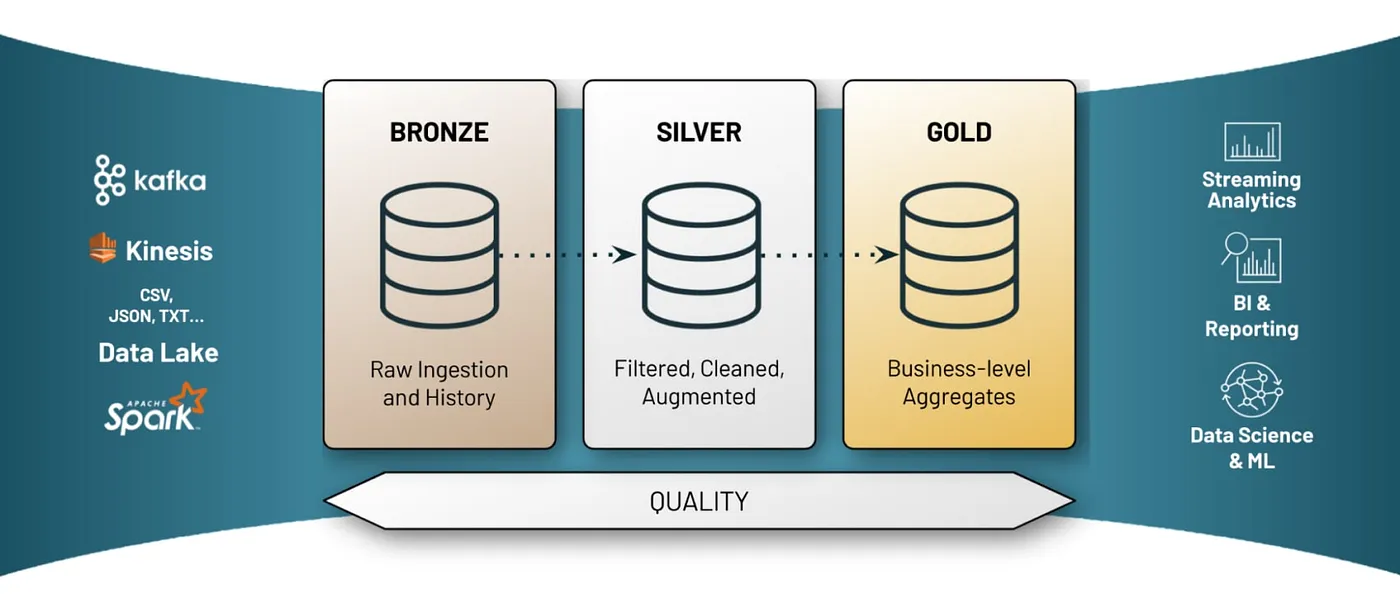
Medallion architecture: best practices for managing Bronze, Silver and Gold | 8 min | Piethein Strengholt | Data Lake | Personal Blog
If you wondered how the layering of your data architecture should be implemented, then your search is over right now. Piethein in his blog post shares his personal opinion on just that. Data platform strategy, landing area, and all layers are well described.
TUTORIAL
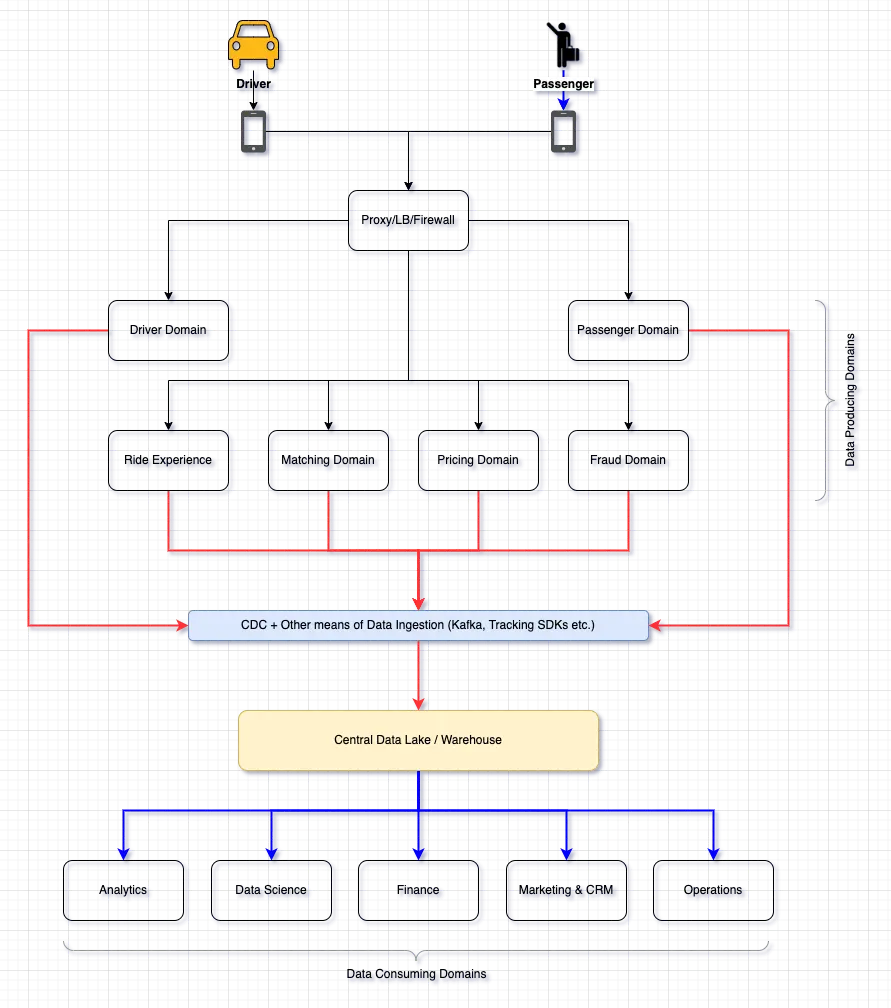
Snowflake Data Mesh: Step-by-Step Setup Guide, with Detailed Notes on Scaling and Maintenance | 25 min | Data Mesh | Atlan Blog
Data Mesh can be hard to implement. It requires an org-wide mindset shift toward decentralization and product thinking. Team Atlan attempted to demonstrate a reference Data Mesh implementation in a growth-stage organization with a complex business domain.
NEWS
Uber Ditches On-Prem and Hooks Future to GCP and Oracle Cloud | 4 min | Cloud | Lisa D Sparks | Data Center Knowledge
Uber joins the cloud! It was a long resisted move by one of the largest Hadoop users. And now they are also converting & over the 7 next years they will migrate all of that over to GCP or Oracle. Data & Data workloads will probably go to GCP. There is a lot of news about it, but this piece seems to put forward an interesting view.
Better Airflow with Metaflow | 12 min | Data Engineering | Outerbounds Blog
Outbounds released support for orchestrating Metaflow workflows using Airflow. The integration is motivated by our human-centric approach to data science. Let’s read how they want data scientists, ML engineers, and data engineers to use Airflow with a better user experience and a stable API, which allows them to develop projects faster and start future-proofing their projects with minimal operational disruption.
VIDEO
Make Your A:B Testing More Effective and Efficient | 50 min | Analytics | Anjali Mehra | DataCamp
One of the toughest parts of any data project is experimentation, not just because you need to choose the right testing method to confirm the project’s effectiveness, but also because you need to make sure you are testing the right hypothesis and measuring the right KPIs to ensure you receive accurate results.
One of the most effective methods for data experimentation is A/B testing, and Anjali Mehra is no stranger to how A/B testing can impact multiple parts of any organization
Since we are talking about analytics, there is an interesting job offer available in that area.
PODCAST
Implementing Patterns And Practices For Infrastructure as Code | 56 min | Hosts: Ned Bellavance, Ethan Banks Guest: Rosemary Wang | Cloud | Day Two Cloud Podcast
A one hour talk with the Developer Advocate at HashiCorp and author of Infrastructure as Code, Patterns and Practices. Listen to more about Infrastructure as Code (IaC)including about the patterns and practices you might want to put in place. So you might want to apply some software development practices to it, particularly for the parts of your team who know what they’re doing with infrastructure but may not be familiar with things like repositories, re-usability, unit tests and so on.
CONFS EVENTS AND MEETUPS
Upgrade your Scaleup from using Spreadsheets to Data Platform | 14th March 2023 | Online
Do you want to know how to increase your data capabilities and become a data-driven company? Join the first webinar in series ‘Building a Data-Driven Company’ and learn what an implemented Modern Data Platform can look like and how it can assist you during your journey into modern analytics.
Webinar online 2023 - Big Data Technology Warsaw Summit | 9th March 2023 | Online
On March 9th you will have the opportunity to listen to presentations given by Mariusz Strzelecki from GetInData | Part of Xebia and Juan Cano from QuantumBlack:
- One does not simply upgrade Airflow. 1.10 -> 2.4 case study
- Analyze your data at the speed of light with Polars and Kedro
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
