
ARTICLES
6 Myths Preventing You from Embracing Real-Time Data | 5 min | Real-Time Data | Eric Sammer | decodable Blog
This text explores the rising importance of real-time data processing in today's businesses, similar to how cloud technology was once met with skepticism. It debunks common myths, showing how real-time data can improve customer experiences and operational efficiency. It highlights tools that make real-time data accessible and cost-effective for all businesses.
Integrating Azure Databricks and Microsoft Fabric | 12 min | Data Management | Piethein Strengholt | Personal Blog
This article explores the integration of Azure Databricks and Microsoft Fabric, two leading services in data engineering and self-service data usage. It examines five current options for combining these tools, discussing the pros and cons of each. Before diving into these options, the article explains why organizations benefit from using Azure Databricks and Microsoft Fabric together.
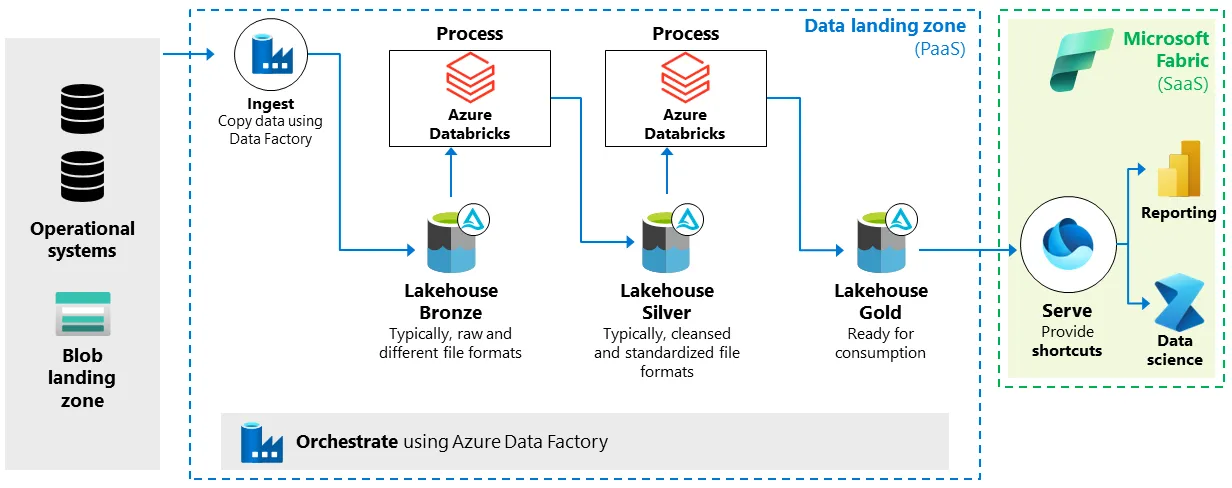
Real-Time Customer-Facing Reporting - Why Showing Users Data Sooner Rather than Later is Better | 7 min | Real-time analytics | Adam Kawa | GetInData | Part of Xebia Blog
Companies use real-time data to boost user engagement, retention, and decision-making. Examples include LinkedIn's content insights, Shopify's Live View, and Google Maps' traffic overlays, which improve customer experience and reduce support costs.
GKE + Gemma + Ollama: The Power Trio for Flexible LLM Deployment | 9 min | LLM | Federico Iezzi | Google Cloud - Community blog
Over the last 10 years, Torsten worked in analytics at various companies, from startups to big tech firms. Each company had unique challenges and data cultures. Key learnings include the importance of data storytelling, business acumen, and pragmatism in analytics.
TOOL
Gravitino | Data Engineering
Gravitino is a high-performance, geo-distributed, and federated metadata lake. It manages the metadata directly in different sources, types, and regions. It also provides users with unified metadata access for data and AI assets.

NEWS
Introducing Databricks LakeFlow: A Unified, Intelligent Solution for Data Engineering | 3 min | Data Engineering | Databricks Blog
Databricks launched Databricks LakeFlow, a unified solution simplifying data engineering tasks from ingestion to orchestration. It features scalable data ingestion, automated real-time data pipelines, and advanced workflow orchestration to address complex data engineering challenges and improve reliability and efficiency.
TUTORIAL
Fine-tune Embedding models for Retrieval Augmented Generation (RAG) | 11 min | RAG | Philipp Schmid | Personal Blog
This blog explains how to fine-tune an embedding model for financial RAG applications using a synthetic dataset from the 2023 NVIDIA SEC Filing. It also explores the use of Matryoshka Representation Learning to improve efficiency. The main topics covered are:
- Create & Prepare embedding dataset
- Create baseline and evaluate pretrained model
- Define loss function with Matryoshka Representation
- Fine-tune embedding model with SentenceTransformersTrainer
- Evaluate fine-tuned model against baseline
Modernize your data observability with Amazon OpenSearch Service zero-ETL integration with Amazon S3 | 8 min | Data Observability| Joshua Bright, Kevin Fallis, Sam Selvan | AWS Blog
Amazon OpenSearch Service now offers zero-ETL integration with Amazon S3, enabling direct queries of operational logs and data lakes without switching tools. This simplifies forensic analysis and reduces data management complexity and costs. Combining the strengths of both services provides efficient and cost-effective data processing.
DATA TUBE
Transforming data with dbt | 47 min | Data Engineering | Piotr Tybulewicz | Tybul on Azure
Databricks notebooks aren't the only way to transform your data. In the latest episode of my free DP-203 course, I discuss dbt - a widely used data transformation solution that offers several advantages over Databricks:
• Simplicity and ease of use
• Data lineage
• Automatically generated and maintained documentation
• Data quality tests
• Jinja templating language
V4 I Hyung Won Chung of OpenAI | 36 min | AI | Hyung Won Chung | Stanford Online
AI is advancing rapidly and is driven by cheaper computing power. Instead of constantly chasing developments, it is more beneficial to study the changes themselves. Examining the early history of Transformer architectures, focusing on how increased compute power influenced their relevance, can provide insights. This approach can help better predict the future direction of AI.
CONFS EVENTS AND MEETUPS
Coalesce | Las Vegas or Online | 7-10th October
Join Coalesce 2024 with a free online ticket to connect with data practitioners worldwide, hear from expert speakers, and gain new skills in analytics engineering. Network with peers in the dbt Community Slack to foster professional relationships. Get energized about the future of data with fresh ideas, new products, and insights from industry leaders.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
