ARTICLES
Anomaly detection using Spark Structured Streaming and Spark ML on Databricks Lakehouse Platform | 9 min | Databricks | Mariusz Domżalski, Jakub Wszolek | Towards Dev Blog
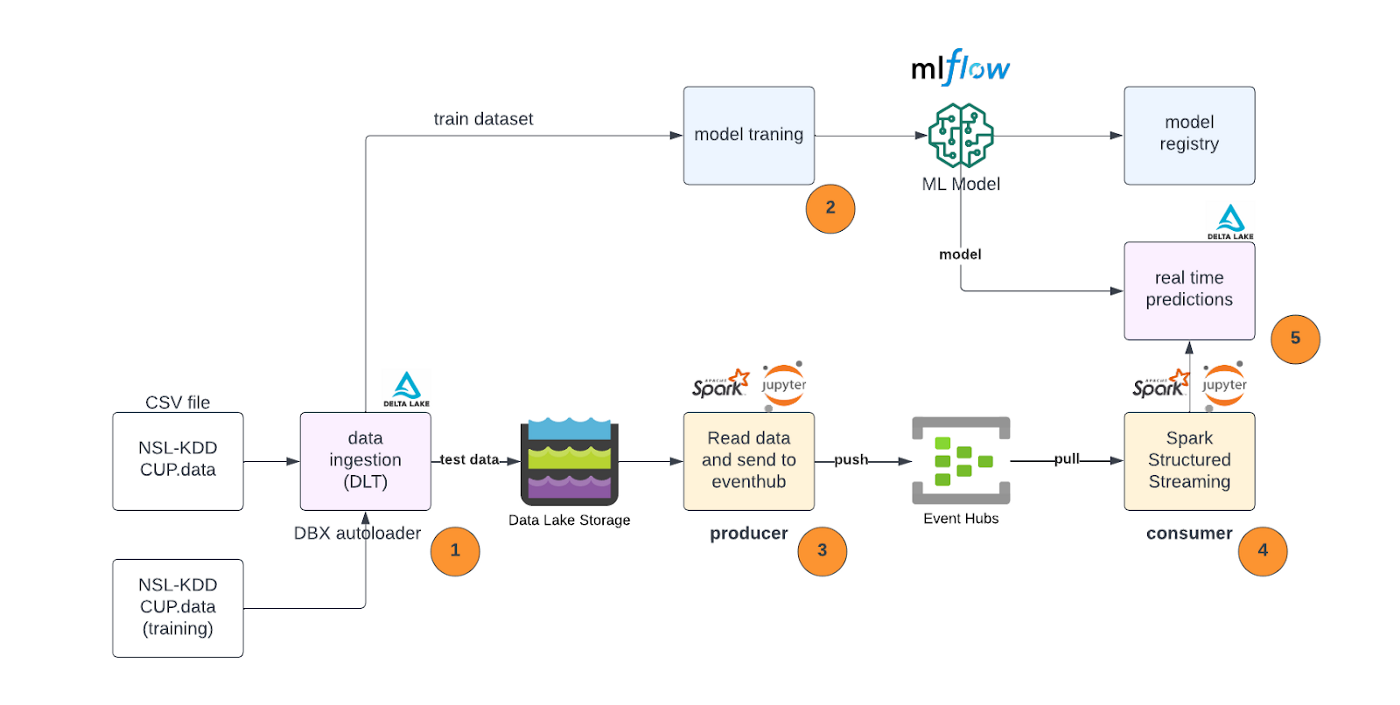
Mariusz and Jakub will introduce you to the concept of a near real-time solution built on Databricks (DLT and ML-Flow), for detecting network intrusion attacks. The solution involves processing data in real-time to identify potential threats. A whole use case is waiting, let’s dive into it.
What exactly is going on in the data world? Over 400 respondents answer questions about what their data infrastructure looks like as well as ask about best practices and other logistical questions. The result? A great, two-part article you should read.
In the first you’ll find more information about:
- Backgrounds On Who Filled Out The Survey
- Vendor Selection (Data Analytics Platforms and Orchestration)
- Best Practices
- Frequently Dealt With Problems
After reading, go to the next one to dive deeper into the types of solutions the respondents rely on. Here is a quick breakdown of the sections.
- Data Catalogs
- Data Observability And Quality
- ETLs/ELTs
- Trending Topics
Apache Kafka (including Kafka Streams) + Apache Flink = Match Made in Heaven | 12 min | Streaming | Kai Waehner | Kai Weahner Blog
What profits can you gain by using Apache Kafka and Apache Flink together? Today you’ll find out why it’s such a powerful combination for stream processing. In this blog post Kai explores the benefits of combining both open-source frameworks, demonstrates the unique differentiators of Flink versus Kafka, and discusses when to use a Kafka-native streaming engine like Kafka Streams instead of Flink.
Deploy your own Databricks Feature Store on Azure using Terraform | 27 min | Feature Store | Szymon Żaczek | Getindata | Part of Xebia
If you want to know what we’ve learned during the process of setting up one of the pieces of the data platform that would truly empower data scientists and machine learning engineers - the Feature Store on Azure Databricks, then we’ve got the newest blog post for you by Szymon Żaczek.
Since we are talking about the Feature Store, option tow:
If you want to know how to design and build a feature store with VertexAI, Snowflake and dbt we recommend this ebook:
Build Feature Stores Faster. An Introduction to Vertex AI, Snowflake and dbt Cloud | ebook | MLOps | Jakub Jurczak | Getindata | Part of Xebia
- MLOps, MLOps platforms and feature stores
- Examples of MLOps workflows
- Designing and building a feature store with VertexAI, Snowflake and dbt
- Using Terraform to set up and maintain the infrastructure

Five Drivers Behind the Rapid Rise of Apache Flink | 5 min | Streaming | Robert Metzger | DataNami
Another one about Apache Flink, this time focusing on the fact that Apache Flink is growing rapidly in popularity. Why is Flink suddenly enjoying so much attention?
1. VC Money Is Attracting Attention
2. Flink’s Proven, Has a Strong Community
3. No Real Alternatives to Flink
…and more, so dive into the article!
Why data engineers should be more like software engineers | 7 min | Data Engineering | Niels Claeys | Personal Blog
Niels considered where and why data engineers can learn from software engineers. What should the data engineering community do to become more mature as an industry? Read some lessons learned from Data Minded and let me know what you think.
TUTORIALS
Replacing a SQL analyst with 26 recursive GPT prompts | 10 min | SQL | Ken Van Haren | Patterns Tech Blog
CrunchBot is a free-form question answering analytics bot on top of the Crunchbase data set of investors, companies and fundraising rounds. Ken built it because of the idea that something like analytics on-call could be entirely replaced by a next-token optimizer like GPT-3. Are you curious how it went?
Simplifying Google Cloud IP Management with Terraform | 4 min | DevOps | Bruno Schaatsbergen | Binx Tech Blog
Say goodbye to the hassle of hardcoded IP addresses and hello to a simplified Google Cloud IP management process. Take a look at the short tutorial on how to do that with Terraform.
NEWS
Introducing 'Managed Airflow' in Azure Data Factory | 4 min | Cloud | Abhishek Narain | Microsoft Blog
Microsoft announces the capability to run Apache Airflow DAGs (Directed Acyclic Graph) within Azure Data Factory, adding a key Open-Source integration that provides extensibility for orchestrating python-based workflows at scale on Azure.
After reading, you'll know the answers to the following questions:
- What is Apache Airflow?
- When should you use Managed Airflow?
- What are the benefits of using Azure Data Factory Managed Airflow?
- and last, but not least - how can I get started?
Amazon EMR Notebooks will be available as Amazon EMR Studio Workspaces in the new console | 4 min | Cloud | Amazon Tech Blog
Important news for people working with Amazon. If you had Amazon EMR notebooks in the old console, they'll become available as EMR Studio Workspaces in the new console by February 8, 2023. Read what you need to do, about the enhanced capabilities in EMR Studio beyond EMR Notebooks, and enabling EMR Studio features for EMR Notebooks users.
PODCAST
MLOps Systems at Scale with Krishna Gade | 53 min | MLOps | guest: Krishna Gade | Software Engineering Daily Podcast
An interview with Krishna Gade who runs FiddlerAI, a startup focused on enterprise model performance management about trusting AI, the technical challenges of ML monitoring and the real world problem statements beyond compliance that explainability can address.
CONFS EVENTS AND MEETUPS
ScyllaDB Summit 2023 | 15-16 Feb | Online event
This edition focuses on how market disruptors are powering the data-intensive applications for this next tech cycle using ScyllaDB — along with the latest hardware advancements, cloud infrastructure, event streaming and other data ecosystem elements.
Discover the latest trends and best practices impacting data-intensive applications. Join the ScyllaDB Summit – free + virtual – for 30+ technical sessions.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig in previous editions DataPill