
ARTICLES
Service-aligned Data Platform Architecture | 6 min read | Data Platform | Justin Ty & Jaskirat Grover | Canva Engineering Blog
A really powerful case study: How Canva scaled data ingestion with Change Data Capture (CDC)
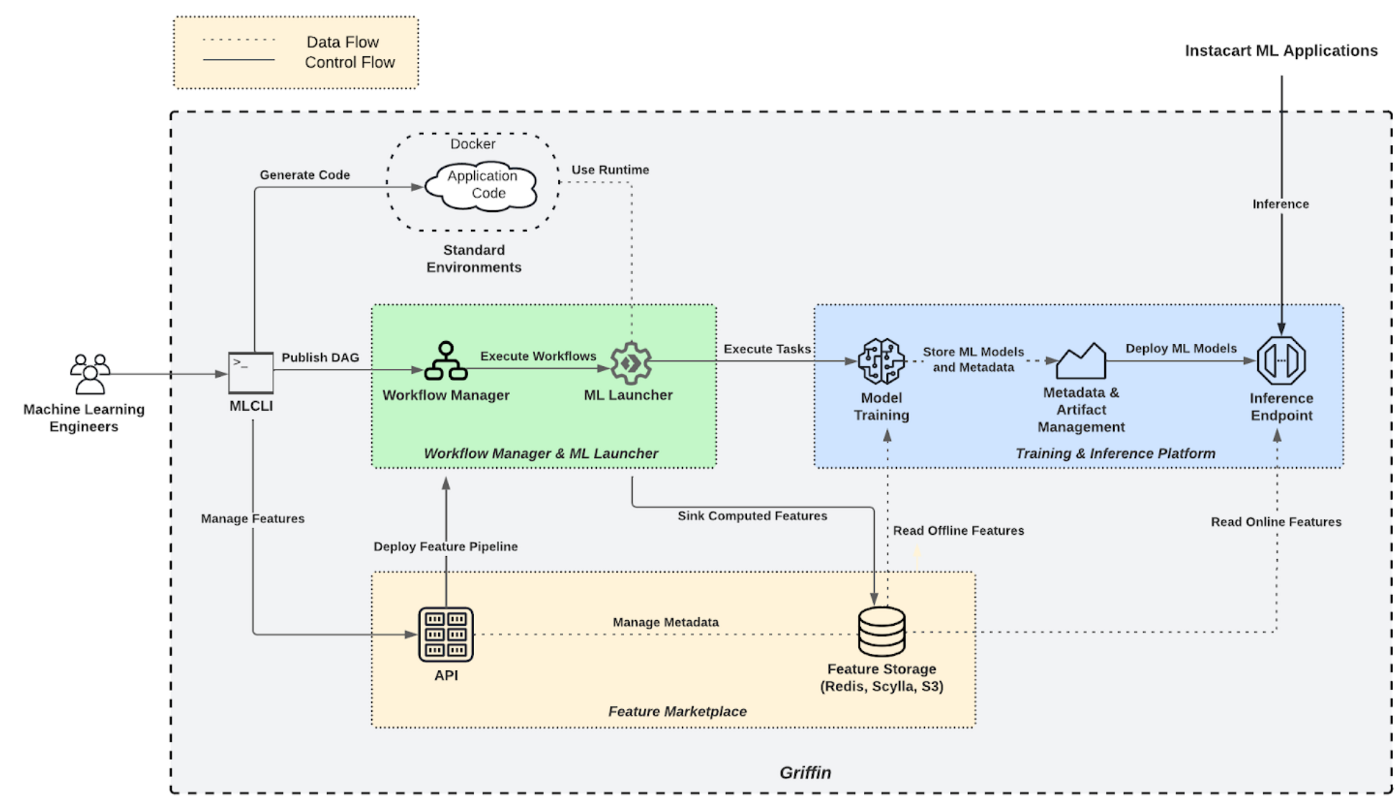
Griffin: How Instacart’s ML Platform Tripled ML Applications in a year | 7 min read | MLOps | Sahil Khanna | tech-at-instacart Blog
How Instacart built their MLOps platform using a hybrid approach of open-source and AWS services (MLflow , airflow, AWS SageMaker and their own framework MLCLI).
Slowly Changing Dimensions (SCDs) In The Age of The Cloud Data Warehouse | 7 min read | 7 min read | Data Modeling | Cedric Chin | Holistics Blog
Simple yet clear advice on how to handle slowly changing dimension (SCD) data in a modern data warehouse/stack. If you understand that “computing is cheap, storage is cheap, engineering time is expensive, ” then the simple idea of snapshotting the dimension table every day sounds like the best one!
Improving Distributed Caching Performance and Efficiency at Pinterest | 11 min read | Storage and Caching | Kevin Lin | Pinterest Blog
Slightly different big data:
“Today, Pinterest’s memcached fleet spans over 5000 EC2 instances across a variety of instance types optimized along compute, memory, and storage dimensions. Collectively, the fleet serves up to ~180 million requests per second and ~220 GB/s of network throughput over a ~460 TB active in-memory and on-disk dataset, partitioned among ~70 distinct clusters.”
Pinterest dives deep into practical optimizations running in the production environment along dimensions of hardware selection strategy, compute efficiency, and networking performance.
Enabling Offline Inferences at Uber Scale | 15 min read | ML & Architecture | Neeraj Dhake & Aravind Ranganathan | Uber Blog
“Initially, we had manual agents review a statistically significant sample from resolved support interactions. They would manually verify and label the resolved support issues and assign root cause attribution to different categories and subcategories of issue types. We wanted to build a proof-of-concept (POC) that automates and scales this manual process by applying ML and NLP algorithms on the semi-structured or unstructured data from all support interactions, on a daily basis.”
In this blog post you will discover what Uber's approach was and the end-to-end design of data processing and ML pipelines.
DATA BIZ & MANAGEMENT
Trust-Driven Development: Accelerate Delivery and Increase Creativity | 7 min read | Culture | Ben Linders & Tomasz Manugiewicz | InfoQ Blog
Dev vs. Ops - “we” vs. “they”. How to change it to “we” & “we?
If people don’t trust each other and don’t feel safe, they invest their energy and time into securing themselves using various corporate approaches that we are all aware of.
How to Introduce Innovation into the DNA of 21st Century Companies | 10 min read | Culture | Ben Linders & Almudena Rodriguez Pardo | InfoQ Blog
Takeaways:
- An innovation mindset is a must for any organization to survive, and the demand for the necessary soft skills has strongly increased over the last few years (in the article you will find a list of 10 most sought-after skills and how they have changed over time)
- Even if your employees have the necessary creativity, you cannot expect them to be innovators without any further support
- No big-bang innovation company program has ever worked; we need to think big, and start small
- In order to nurture innovation culture in your organization, employees need trust, time, space, teams, a second operating system, MVPs, and co-creation
NEWS
Introducing Apache Iceberg in Cloudera Data Platform | 6 min read | Cloudera Blog
Cloudera adopts Apache Iceberg as a main data & table format!
Open sourcing Feathr – LinkedIn’s feature store for productive machine learning | 5 min read | David Stein | LinkedIn Blog
LinkedIn Engineering recently open-sourced its feature store Feathr, which helps engineers to develop machine Learning products by simplifying feature management and usage in production.
Recap of Databricks Machine Learning announcements from Data & AI Summit | 5 min read | Kasey Uhlenhuth & Nicolas Pelaez | Databricks Blog
New capabilities announced:
- MLflow 2.0 Including MLflow Pipelines
- Serverless Model Endpoints
- Model Monitoring
TUTORIALS
Building a Mobility Dashboard with Cloud Run and Firestore | 7 min read | Google Cloud | Hayato Yoshikawa | Google Cloud Blog
Walk through how to build a real-time dashboard with Cloud Run and Firestore.
PODCAST
Data Update with Jakub Pieprzyk (GetInData) - Modern Data Platforms, the what's, why's and how's? | 36 min | AI | Radio DaTa
Changes and trends that resulted in the creation of so-called Modern Data Platforms.
- adoption of best practices from the software development domain (e.g. dbt),
- the shift from ETL (Extract-Transform-Load) to ELT (Extract-Load-Transform) paradigm,
- serverless databases (e.g. Snowflake, BigQuery, Athena), public cloud, and support for SQL everywhere.
CONFS AND MEETUPS
Today we will treat this section a little differently. It's summer and the summer holidays (at least in Poland and calendar-wise) so instead of inviting you to events, we'll share an assessment of one of them.
A Review of the Presentations at the Big Data Technology Warsaw Summit 2022! | 10 min read | 👏 Klaudia Wachnio, Mariusz Strzelecki & Adam Stelmaszczyk | GetInData Blog
Big Data top trends summary and review of two conference tracks:
- Artificial Intelligence and Data Science
- Real-time streaming
