
ARTICLES
2024 Lakehouse Format Rundown: Engines & Gorillas | 14 min | Data Engineering | Jacques | sundeck Blog
This is part 1 of a 3 part series focused on looking at the current state of lakehouse formats. Don’t miss part 2 where we analyze community health and part 3 where we look at key trends.
Four benefits of AI for security, safety and transparency in telecom| 6 min | AI | Rafia Inam, Andrey Shorov, Elif Ustundag Soykan, Jim Reno, Raquel Berlanga | Ericsson Blog
This post explores Ericsson's extensive experience with AI, from optimizing network data and performance to addressing security challenges in telecom. Discover how Ericsson uses AI to predict vulnerabilities, fight fraud, and protect telecom infrastructure and privacy.
Top RAG Pain Points and Solutions | 8 min | LLM | Bijit Ghosh | Personal Blog
This analysis tackles these challenges and offers solutions, using advances in language models and interdisciplinary methods to push forward conversational AI.
Few of them?Want to know 7 more? Dive in!
- Slow Inference Speed
- Difficulty Evaluating Quality
- Poisoning Attacks
- Backdoor Triggers
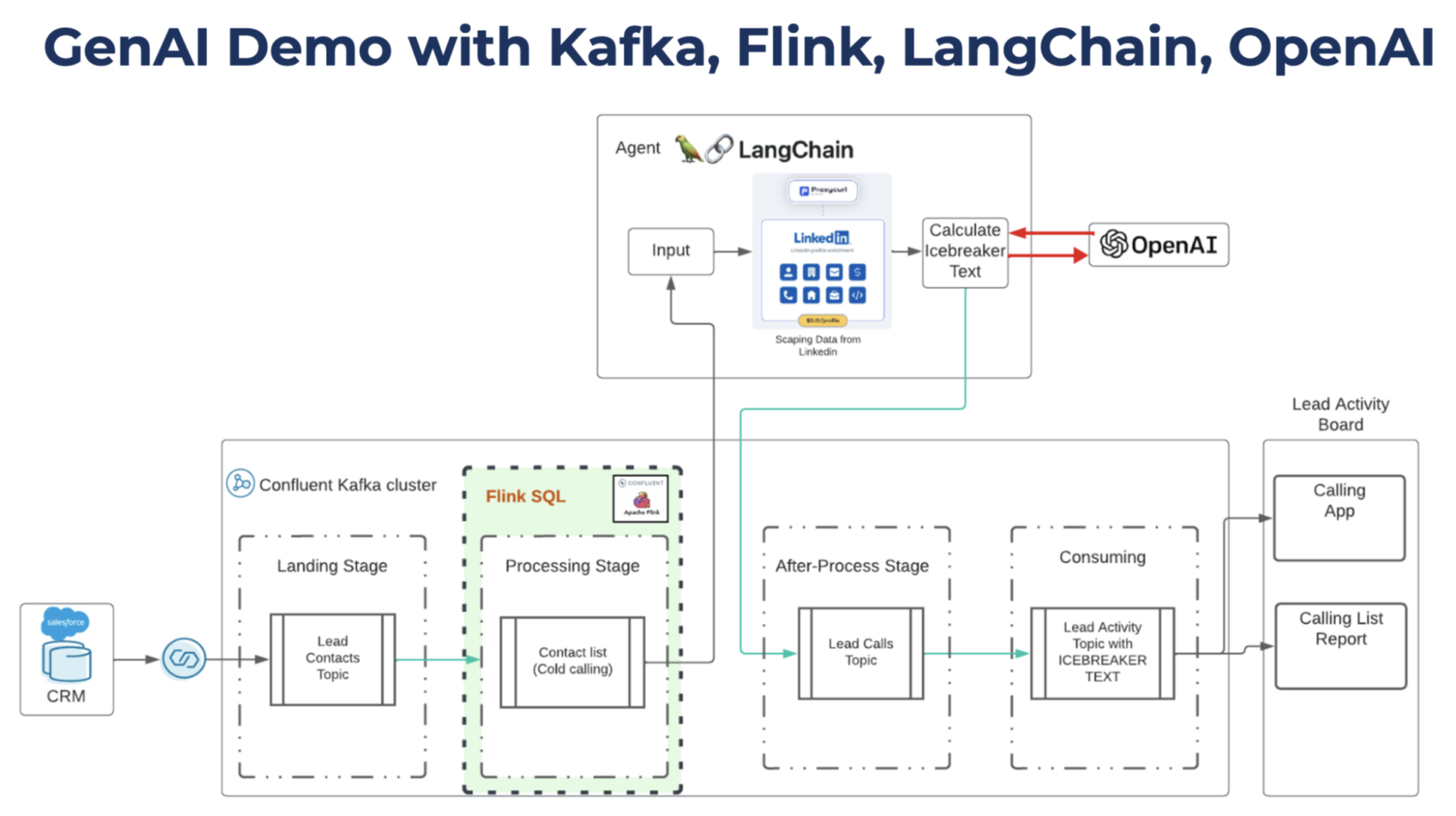
GenAI Demo with Kafka, Flink, LangChain and OpenAI | 13 min | Gen AI | Kai Waehner | Personal Blog
This post explores an efficient architecture combining Python and LangChain with OpenAI's LLM, Apache Kafka for data streaming, and Apache Flink for processing. Discover how it improves Salesforce CRM data by integrating public datasets from Google and LinkedIn and suggest ice-breaker conversations for sales reps.
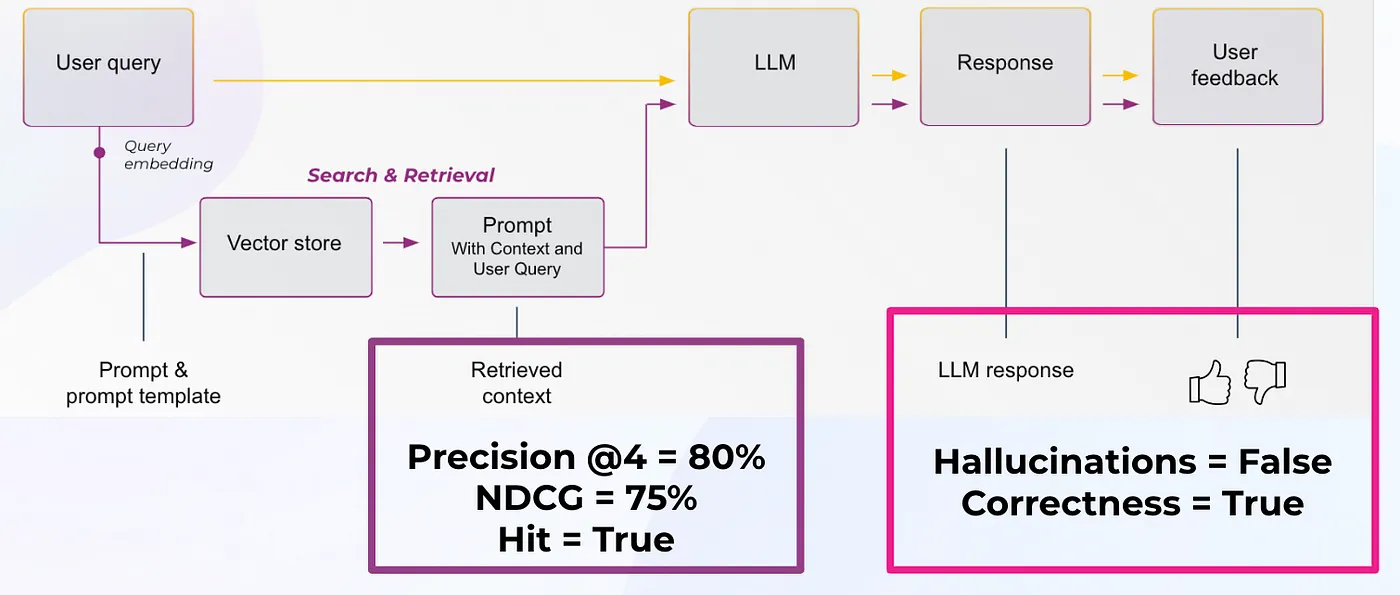
Top Evaluation Metrics for RAG Failures | 8 min | LLM | Amber Roberts | Towards Data Science
This post deeply investigates boosting LLM outputs by weaving in contextually relevant data, aiming for better search and retrieval tasks. It highlights how this approach can elevate Salesforce CRM insights and sharpen AI response accuracy.
TUTORIAL
Customizing Flink. Part 1: Forking | 7 min | Data Engineering | Sap1ens Blog
This tutorial explains how to make your version of Apache Flink to fit your needs. It talks about how to get started, keep your version up to date, and share your changes with others.
Structured Data Analysis using Knowledge Graph + LLM | 7 min | LLM | Md Sharique | Personal Blog
Read about graphs via large language models, comparing their benefits and drawbacks against vector databases. It discusses the application of knowledge graphs in sectors where relationships between entities are crucial for providing solutions to stakeholders.
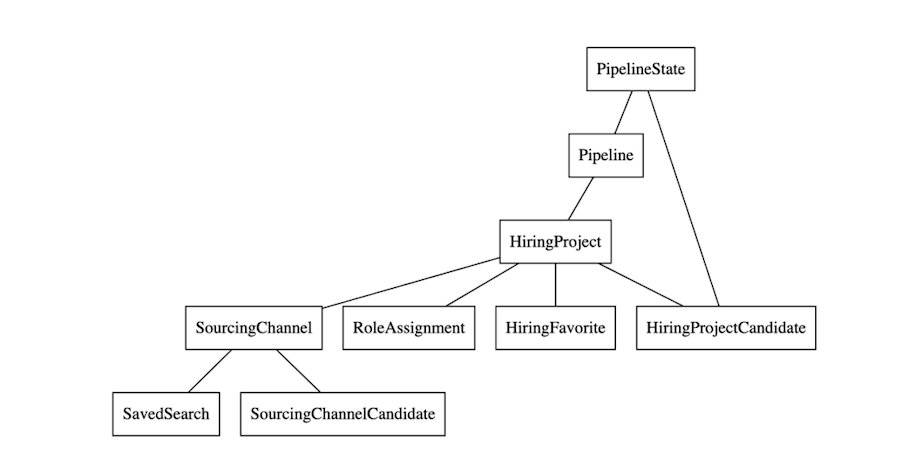
Improving Recruiting Efficiency with a Hybrid Bulk Data Processing Framework | 8 min | Data Engineering | Aditya Hegde, Saumi Bandyopadhyay | Linkedin Engineering Blog
Delve into the hybrid bulk data processing framework, designed for exceptional durability, observability, and scalability. It has effectively managed over 4,000 requests weekly for over five months. The discussion includes its support for over 15 entity types, blending offline and nearline entities for superior performance.
DATA TUBE
Why ML Projects Fail & How to Ensure Success | 50 min | ML | Eric Siegel | DataCamp
In the episode, Adel and Eric discuss why machine learning projects fail to reach production, introducing the BizML Framework to align business stakeholders with ML use cases, addressing the skills gap, exploring organizational use cases for operational improvement, and lessons from past ML hype cycles for generative AI.
PODCAST
Brewing Beer with A.I. | 1 h 36 min | AI | Jon Krohn, Beau Warren | Super Data Science: ML & AI Podcast
In this episode you will learn:
• About Species X
• How to become a certified beer taster
• How Beau checks the quality of his beer
• Beau and Jon’s machine learning project
• About genetic algorithms
• How to get creativity out of LLMs
Building a Data Lake | 53 min | Data Engineering | Sean Falconer, Adam Ferrari | Software Engineering Daily
Adam Ferrari joins the show to talk about Starburst, data engineering, and what it takes to build a data lake.
CONFS EVENTS AND MEETUPS
Infoshare - Call For Speakers | Gdańsk | 22nd-23rd May
Real-life experience and upright knowledge are the basis of all Infoshare speeches. We strive to fill both days of the conference and all five stages with inspiring content and expert data.
Join us and be part of the biggest tech festival in CEE!
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
