
ARTICLES
Data Modeling Today: launching cost-effective analytics for ManyChat | 6 min read | AI, ML / Data | Nikolay Golov | ManyChat Blog
The conclusion from the ManyChat (marketing startup) use case: proper data architecture enables you to forget about the linear growth of spending (proportional to data volumes) and switch to almost constant expenses.
Nikolay presents an approach to creating analytical platforms for a startup that require constantly changing business models.
The Anatomy of a Data Product | 11 min read | Data Engineering | Eric Broda | Towards Data Science
- How are data products designed, and how do they work so that they make data easy to find, consume, share and govern?
- What capabilities, APIs and lifecycles need to be established to make Data Products easy to build, deploy, secure and manage?
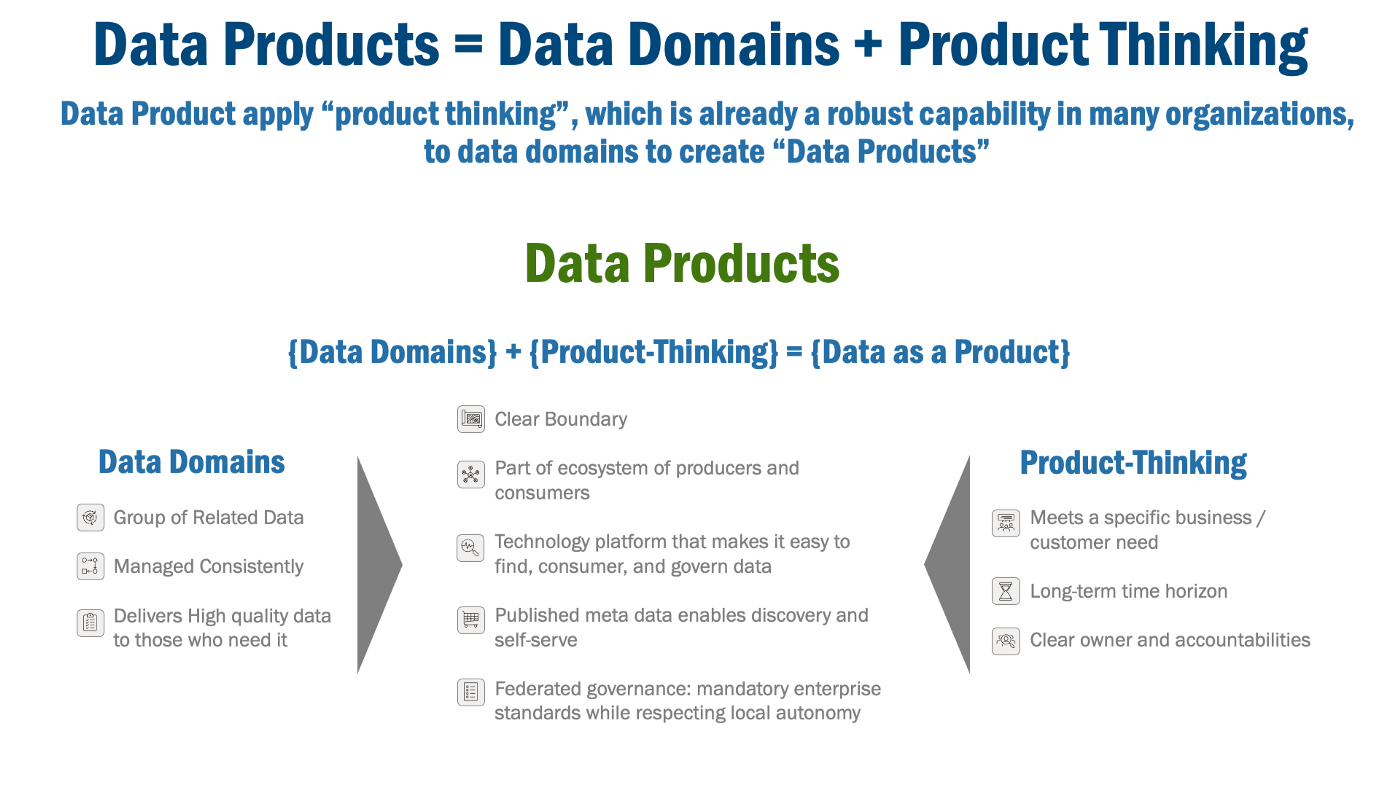
Towards Machine Learning Observability at Etsy | 10 min read | ML | Kyle Gallatin | Etsy Blog
ML Observability is a relatively new field, focusing on monitoring the distribution of input features, predictions and performance metrics. Kyle explains why Etsy decided to implement centralized ML observability.
At Etsy, most models are retrained on a 24-hour basis on a sliding window of data (say the last 3 months). Since each day models are updated with the latest data, there’s little chance of poor performance due to model drift - one of the most frequently discussed subtopics of ML observability.
Through ML observability, we aimed to save on long-term cost by setting up the building blocks that we'd need for future features like intelligent retraining - which would only retrain our large, expensive models as needed.
Lack of observability has also led to more than one production incident with our ML models. These incidents had been caused by things like upstream data quality issues in the past, some of which were identified quite late and only solved through tedious, manual debugging.
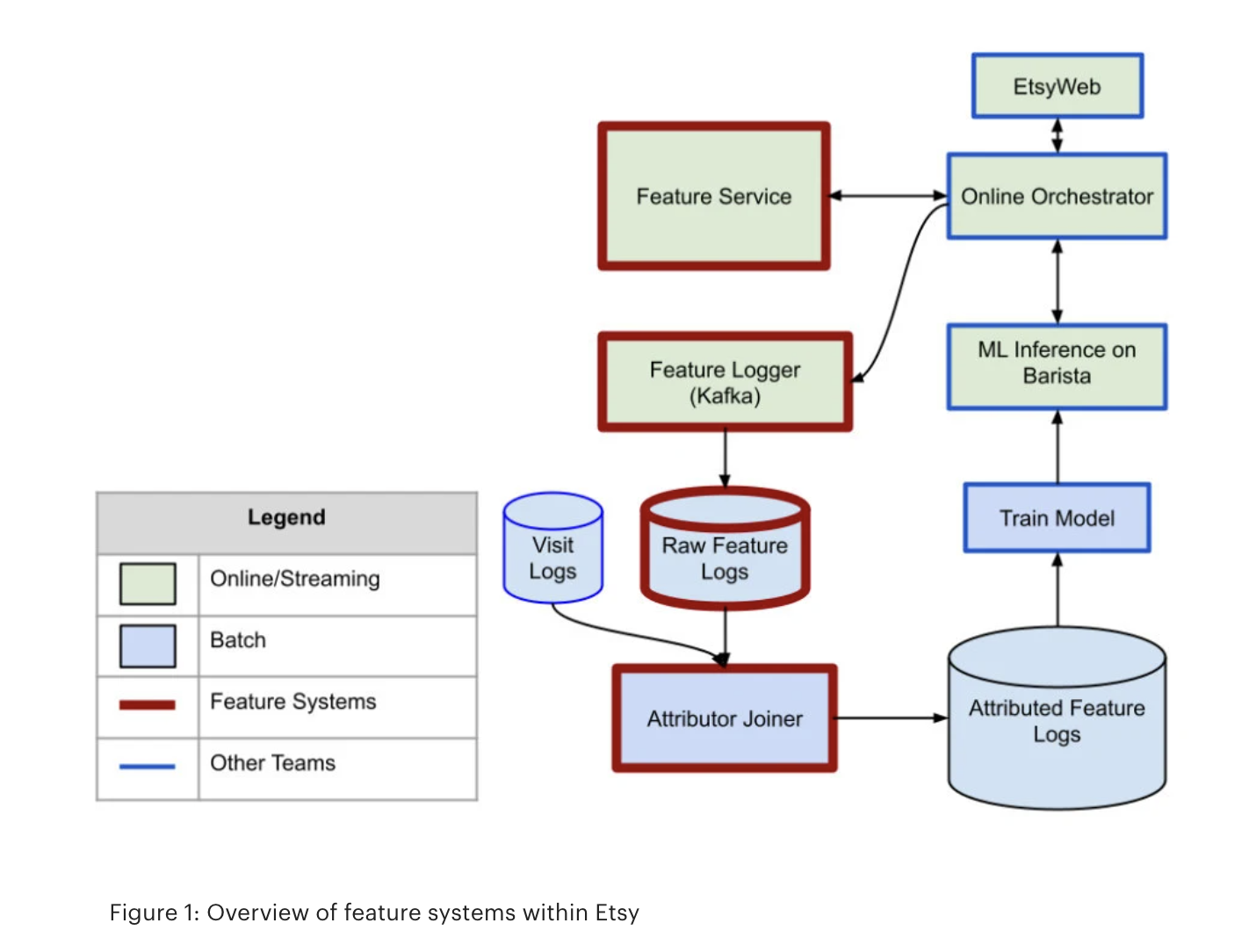
Applying multitask learning to AI models at LinkedIn | 10 min read | ML, AI | Ji Yan, Sen Zhou, Dansong Zhang, Anastasiya Karpovich | LinkedIn Blog
How is multitask learning different from traditional learning? All is explained in this article.
In LinkedIn, the application of multitask learning has shown to improve model performance with significant product impact. Some of the guys from LinkedIn share what the assumptions were and how they solved the challenges that arose.
Kubeflow: Machine Learning on Kubernetes — Part 1 | 10 min read | Kubernetes | Rishit Dagli | KubeSimplify Blog
Rishit explains how to understand Kubeflow architecture and shares some of his experiences and tips such as:
Monitoring for skews, prediction quality, data drift and concept drift after deploying a model is just as important and you should be prepared to iterate based on these real-world interactions.
NEWS
Google Cloud IoT Core goes on the end-of-life list | 3 min read | Google Cloud | Richard Chirgwin | IT News Blog
Users have a year to move from the Google Cloud Platform IoT Core service…
Introducing a Google Cloud architecture diagramming tool | 5 min read | Google Cloud | Priyanka Vergadia | Google Cloud Blog
We prefer generic tools like draw.io, but this one specialized for GCP looks really nice and productive.
Accelerate Analytics for All | Ram Venkatesh | Cloudera Blog
Cloudera is still in the game.
TOOLS
Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch | GitHub | Hugging Face
This looks nice, so I'll just leave it here…
Diffusers offer:
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code.
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference.
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system.
PODCAST
How Real Time Data Accelerates Business Outcomes | 45 min | DataCamp | George Trujillo
George shares the real-world use cases of real-time analytics, why reducing data complexity is key to improving the customer experience, the common problems that slow data-driven decision-making and more.
DataTube
How to run Kedro pipelines on Azure ML Pipelines service? - MLOPS TUTORIAL | 18 min | 💪 Marcin Zabłocki | GetInData
Marcin presents a new Kedro Azure ML plugin that enables running Kedro pipelines on an Azure ML Pipelines service. He discuss and demonstrates:
- what Kedro is and what the benefits of this solution are
- how to track the metrics using MLflow
- how to install this plugin
GIS Pipeline Acceleration with Apache Sedona | 32 min | Data & AI | Fernando Ayuso Palacios & Alihan Zihna | Databricks
Large scale geospatial processing in databricks using Apache Sedona. Fernando Ayuso Palacios & Alihan Zihna share their experience and benefits of using it and present their solutions for setting up Apache Sedona on databricks, the common pitfalls, solving issues and implementing the GIS data pipeline on databricks.
CONFS AND MEETUPS
The conference for open source data in the cloud | 14-15 September | Amsterdam
This conference is focused on open source data tools. Presentations and discussions will cover everything from sharing best practices to building and operating complex systems at scale.
