
ARTICLES
Level up your dbt tests to catch loud and silent data issues at scale | 4 min | Data Engineering | Emil Bring | Validio.io Blog
Integrating Validio with dbt offers advanced data testing capabilities beyond traditional methods, addressing scalability issues and uncovering silent anomalies. By combining dbt tests with Validio's ML-powered detection, teams ensure high-quality data, enabling engineers and consumers to maintain reliability throughout the pipeline.
What’s new with Looker 2024? | 7 min | AI | Hanna Le | Personal Blog
The article serves as a summary of the significant changes, highlighting important information for Looker users. In addition to introducing the integrated Looker experience and Google GenAI, performance enhancements are also planned.
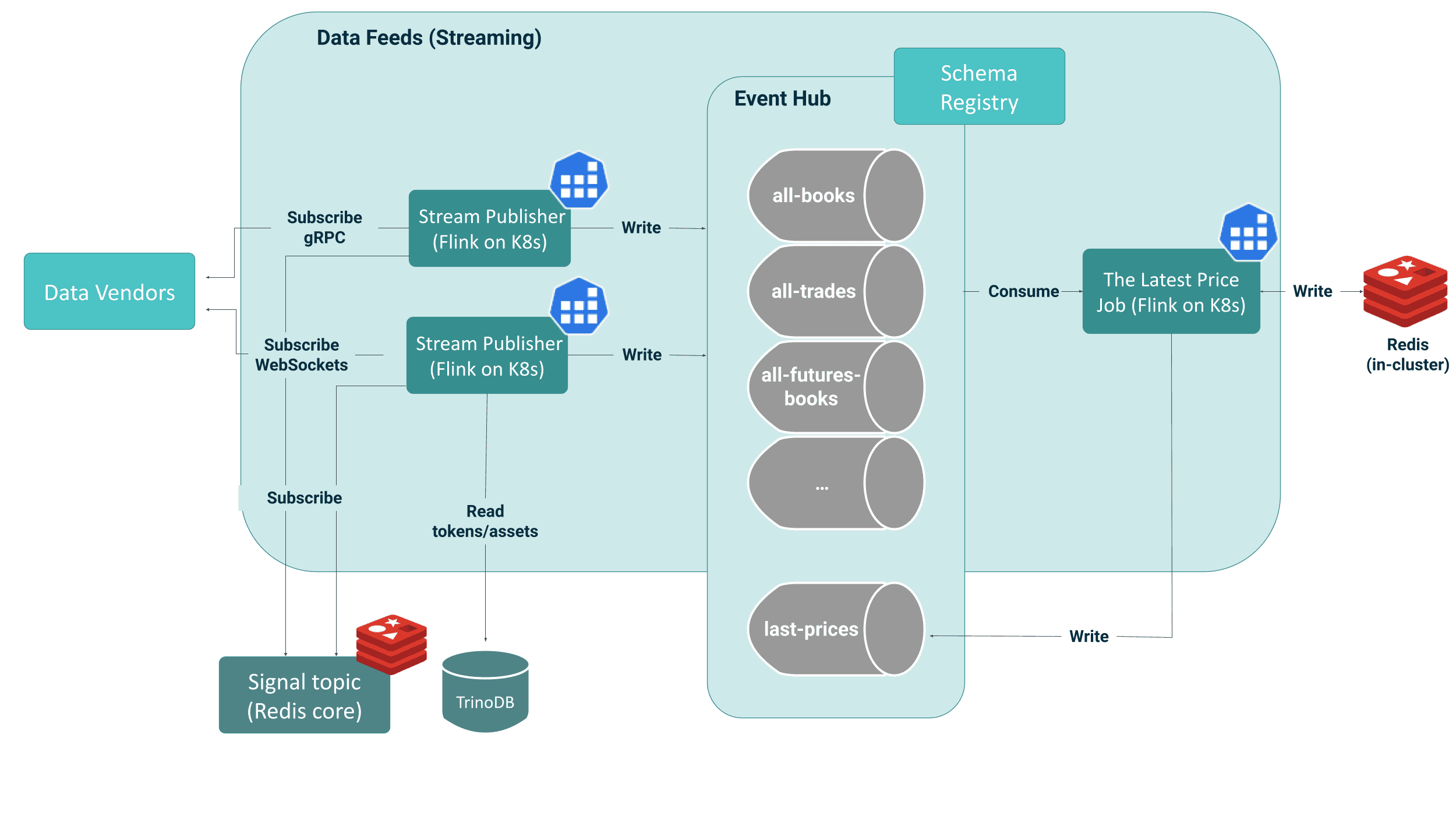
Streaming Analytics for the Digital Asset Risk Management System - Cloudwall Success Story | 9 min | Streaming Analytics | Maciej Maciejko, Klaudia Wachnio | GetInData | Part of Xebia Blog
How can we reduce data processing time to milliseconds for 100 million messages per hour? Ensure data quality and optimize infrastructure costs. The GetInData team chose Apache Flink for streaming analytics architecture. Explore their real-time market data platform for fast issue resolution.
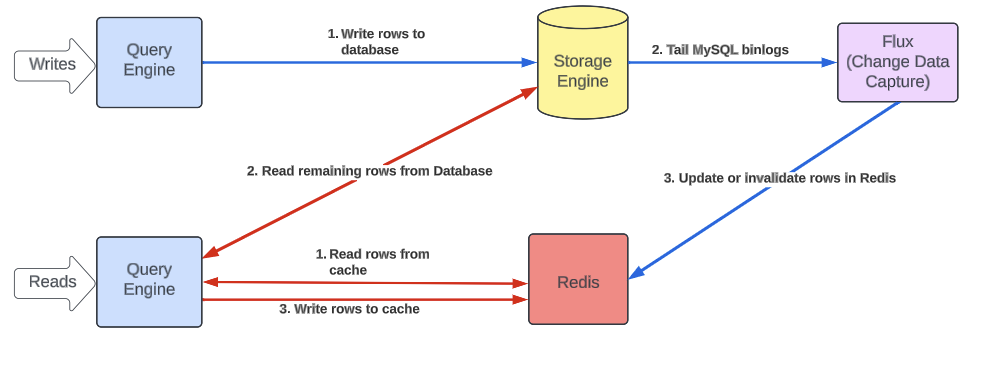
How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache | 12 min | Data Engineering | Preetham Narayanareddy, Eli Pozniansky, Zurab Kutsia, Afshin Salek, Piyush Patel | Uber Engineering Blog
The blog explores Docstore, Uber's distributed database built on MySQL®, handling massive data volumes and serving numerous requests per second. With growing demands for low-latency access and scalability, we introduce CacheFront, an integrated caching solution to improve performance, reduce resource allocation, and strengthen consistency guarantees for Docstore users.
TUTORIAL
How to Adopt Your LLM for Question Answering with Prompt-Tuning using NVIDIA Nemo Weights & Biases | Anish Shah | 12 min | LLM | MLOps Community
A tutorial on prompt-tuning and p-tuning using NeMo alongside W&B, complete with an experiment and executable code.
Data Quality Management With Databricks | 17 min | Data Engineering | Liping Huang, Lara Rachidi | Databricks
A very detailed description of how to do Data Quality in the context of Databricks. It structures the DQ subject nicely and can be applied to many other environments.
TOOL
How Dataherald Makes Natural Language to SQL Easy | 4 min | LLM | Ming | Langchain Blog
Text-to-SQL technology, providing developers strong NL-to-SQL translation through LangChain, addressing challenges of semantic accuracy and dataset-specific fine-tuning. Its two agents enable diverse applications, from conversational interfaces to self-serve data access, with ongoing developments ensuring continued innovation in the field.
NEWS
Gemma: Introducing new state-of-the-art open models | 9 min | LLM | Jeanine Banks, Tris Warkentin | Google Blog
Gemma is developed by Google DeepMind and other Google teams, drawing inspiration from the Gemini models. Gemma has accompanying tools to promote developer innovation, encourage collaboration, and ensure responsible usage.
DATA TUBE
RAGOps: Advanced Retrieval Strategies with LangChain, Langsmith and Supabase | 49 min | RAG | Prince Canuma | Personal Channel
This video will guide you through setting up each pipeline step, along with monitoring, evaluation, and enhancing your prompts and document processing. Also, get an inside look at how Kulissiwa team optimize their RAG pipelines using LangChain, Langsmith, and Supabas.
CONFS EVENTS AND MEETUPS
Apache Airflow Meetup | Warsaw | 21st March
We'll talk about the newest trends and developments in Airflow, the contribution and development process itself, in particular testing provider packages. The agenda is still open - don't hesitate to contact us if you'd like to present!
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
