
ARTICLES
Ready-to-go sample data pipelines with Dataflow | 13 min | Data Pipelines | Jasmine Omeke, Obi-Ike Nwoke & Olek Gorajek | Netflix Blog
It’s all about bootstrapping, standardization and automation of batch data pipelines at Netflix. What dataflow is and its feature: sample workflows.
Deploying Grafana to Azure App Service with Terraform (and Active Directory integration) | 6 min | Cloud, DevOps | Valerii Matveev | Xebia Blog
Grafana is a free and open source platform which allows you to query, visualize, alert on and understand your metrics.
As your system grows bigger and has more moving parts, it becomes vital to be able to tell wheter it’s healthy and operational at a glance.
Near-real-time IoT Robust Anomaly Detection Framework | 15 min | IoT | Jakub Augustin & Dr. Piotr Majer | Databricks Blog
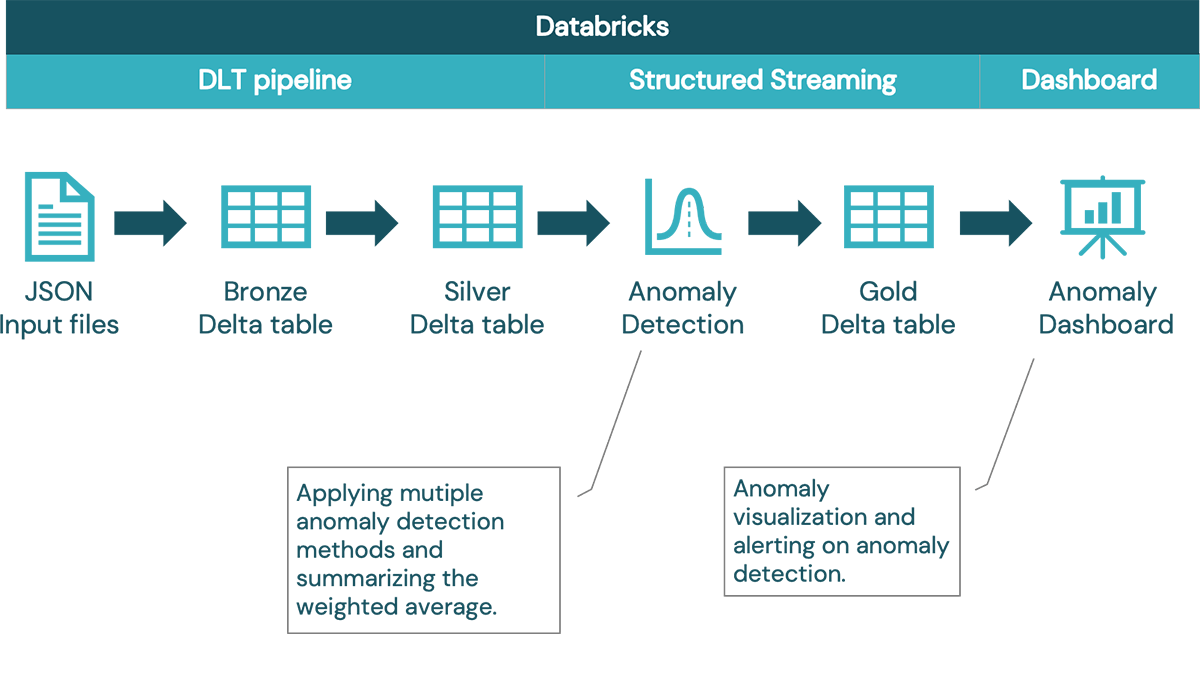
This article demonstrates a robust, real-world anomaly detection framework for streaming time series data. The autonomous system is built on Databricks using DLT for the streaming ETL, parallelised with Spark and can be adapted to multiple different IoT scenarios. The new data points are evaluated by multiple techniques and the outliers are identified based on the majority rule, which should decrease the number of false positives. This framework can be easily extended by simply adding more models to the evaluation step, further improving the overall performance or customizing for a particular problem at hand. The result of this workload is displayed in an easy-to-use dashboard, which serves as a control panel for the stakeholders.
Enabling static analysis of SQL queries at Meta | 10 min | Infrastructure | Daniel Ohayon | Meta Engineering Blog
UPM is Metas internal standalone library to perform static analysis of SQL code and enhance SQL authoring. It takes SQL code as input and represents it as a data structure called a semantic tree.
Infrastructure teams at Meta leverage UPM to build SQL linters, catch user mistakes in SQL code and perform data lineage analysis at scale.
Executing SQL queries against a data warehouse is important to the workflows of many engineers and data scientists at Meta for analytics and monitoring use cases, either as part of recurring data pipelines or for ad-hoc data exploration.
What are the challenges? How does UPM work?
From Zero to 50 Million Uploads per Day: Scaling Media at Canva | 8 min | Engineering | Robert Sharpn & Jacky Chen | Canva Engineering Blog
The evolution of media persistence during hypergrowth at Canva -
Lessons learned in the migration process:
- Be lazy. Understand your access patterns and migrate commonly accessed data first if you can.
- Do it live. Gather as much information upfront as possible by migrating live, identifying bugs early and learning to use and run the technology.
- Test in production. The data in production is always more interesting than in test environments, so introduce checks in production wherever you can.
Using Server Sent Events to Simplify Real-time Streaming at Scale | 5 min | Data Science & Engineering | Bao Nguyen | Shopify Blog
How Shopify implemented an SSE server to simplify BFCM Live Map architecture and improve data latency. How to choose the right communication model for your use case, the benefits of SSE and code examples for how to implement a scalable SSE server that’s load-balanced with Nginx in Golang.
NEWS
Run Jupyter From Your Servers With New Anaconda Notebooks Integration | 5 min | Data Science | Anna Ng | Anaconda Blog
On-premises implementation of Anaconda Notebooks is a tightly integrated JupyterHub instance, giving IT the ownership and governance of company assets that they need and data scientists the tools that they love.
BIZ & MANAGEMENT
How to work with customers? Scrum Framework in Dema project | 16 min | Agile | Rafał Zalewski | GetInData Blog
What goals have Scrum helped achieve?
- brought value to the end users within 2 months
- long-time vision of the project
- minimised the cost and time when requirements need changing
- started the project with a small, well-designed team with the necessary skills
PODCAST
Data Journey with Henrik Feldt (Causiq) - Using data & real-time ML to maximise ROI of marketing activities, lessons learned about building an advanced tech product | 37 min | ML | host: Adam Kawa; guest: Henrik Feldt | Radio DaTa
- How data & ML are used at Causiq
- The importance of real-time ML in analyzing the efficiency of their marketing channels
- Tech stack used by Causiq (the mix of GCP and open-source such as Kafka, Flink, Hudi, dbt)
- Entrepreneurial advice for data engineers/architects who would like to launch their own product or company
The blockchain tech to build in a crypto winter | 1 h | blockchain | host: Ben Popper; guest: Andrew McFarlane | The Stack Overflow Podcast
McFarlane explains where popular languages like Rust and Go can be found in the Web3 world and why he thinks a crypto winter is the best time to be building fundamental tech.
DATA TUBE
Automated Data Lineage with Unity Catalog | 4 min | Data | Databricks
Watch this short video that shows a Data Lineage demo. Data lineage is captured down to the table and column level and displayed in real time with just a few clicks. Unity Catalog also captures lineage for other data assets such as notebooks, workflows and dashboards. Lineage can be retrieved via REST API to support integrations with other data catalogs and governance tools.
CONFS EVENTS AND MEETUPS
Paper Talks | 15 December | Online Zoom Meeting
Are you passionate about Data Science and Machine Learning? GetInData has launched a new knowledge sharing initiative called Paper Talks - an open zoom meeting with our Advanced Analytics team to discuss a particular scientific paper and exchange experience with each other. In this edition of the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" will be discussed.
DATA + AI SUMMIT 2023 | Call for Presentation | 26-29 June | Online & San Francisco
The premier event for the global data, analytics and AI community has now opened the call for presentation.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
