
ARTICLES
The end of Big Data | 10 min read | Databricks, Snowflake | Benn Stancil | Benn.Substact Blog
Ok, the title is clickbait, no need to change the job, but it still has some valid points.
Like:
Data for the middle class - if Big Data is commonly adopted, the tools must be simpler and focus on basic problems. If everyone wanted to use Big Data for complex stuff, there wouldn't be enough qualified people who would like to do such a job.
A Step-by-Step Guide to Training a Machine Learning Model using BigQuery ML (BQML) | 15 min read | BigQuery ML| 🎉 Michał Bryś | GetInData Blog
The process of training, validating and deploying a machine learning model using BigQuery ML (BQML) explained. The example model predicts the probability of adding an item to the shopping cart on an e-commerce website. GetInData used the Google Analytics 4 export to BigQuery to train a logistic regression classifier and then predicted the probability of a sample event (addedToCart) on the new sessions.
Dynamic Kubernetes Cluster Scaling at Airbnb | 10 min read | Kubernetes | Airbnb Blog
Over the past few years, Airbnb has shifted almost all online services from manually orchestrated EC2 instances to Kubernetes. Today, it runs thousands of nodes across nearly a hundred clusters to accommodate these workloads. In the blog post there are three stages of setting up a Kubernetes cluster.
Stage 1: Homogenous Clusters, Manual Scaling
Stage 2: Multiple Cluster Types, Independently Autoscaled
Stage 3: Heterogeneous Clusters, Autoscaled
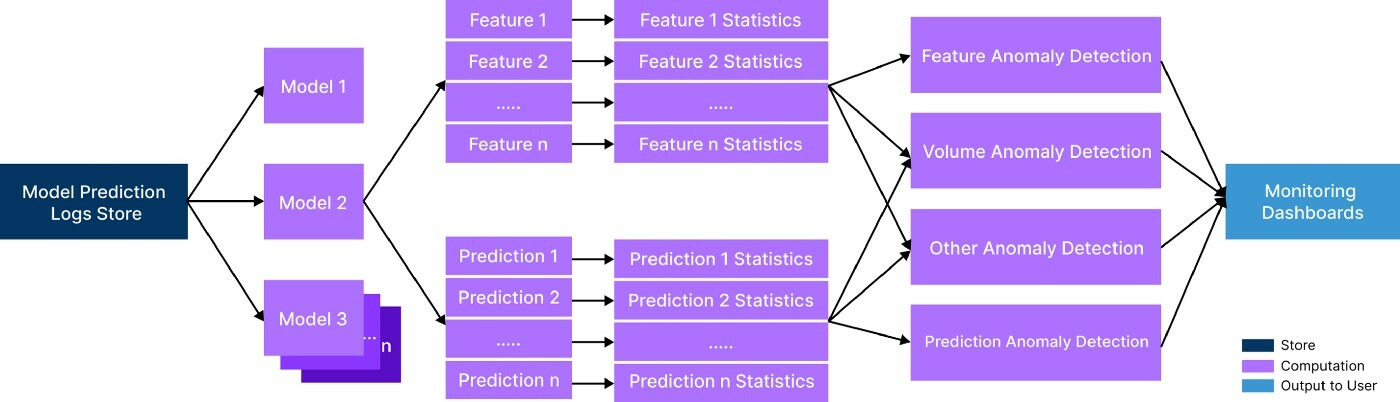
Full-Spectrum ML Model Monitoring at Lyft | 11 min read | ML | Mihir Mathur | Lyft Blog
Discover how Lyft built a robust system for identifying and preventing model degradation and the variety of model monitoring approaches they developed. Plus conclusions:
- Automate as much as possible. An even better solution to provide a seamless onboarding experience is to remove it entirely.
- Monitoring will reduce shipping velocity slightly. By enforcing monitoring for all models, there is an additional prerequisite in the productionzation of models.
Monitoring Large-Scale Apache Flink Applications, Part 2: Metrics for Troubleshooting | 12 min read | Apache Flink | Nico Kruber | Ververica Blog
This post focuses on the metrics that are concentrated on expanding on these metrics and provides more insights into identifying resource bottlenecks and sources of errors.
You will also find some details about the Grafana dashboard.
NEWS
Amazon EMR Serverless Now Generally Available – Run Big Data Applications without Managing Servers | 6 min | Cloud Nativ | Anthony Alford | AWS News Blog
Another option to run Spark serverless (and many more Big Data tools).
PODCAST
Scaling Real-time Machine Learning at Chime | 24 min | MLOps.community
Peeyush Agarwal explains 2 key pieces of the ML infrastructure at Chime. He goes into detail about the current feature store design and feature monitoring process along with the ML monitoring setup.
A Multipurpose Database For Transactions And Analytics To Simplify Your Data Architecture With Singlestore | 41 min | Data Engineering Podcast
SVP of engineering Shireesh Thota describes the impact on overall system architecture that Singlestore can have and the benefits of using a cloud-native database engine.
CONFS AND MEETUPS
Berlin Buzzwords | 12-14 June | Berlin
What’s gonna happen?
- Keynote by Fiona Coath, who will talk about opposition to surveillance capitalism and our responsibilities as technologists.
- Nick Burch, who will explore what Wordle can teach us about Information Retrieval, Search and AI/ML.
- Anshum Gupta will tell us what's new in Apache Solr 9.0
Open Data Science Conference | 15-16 June | London
Conferences focus areas:
- Machine Learning & Deep Learning
- Machine Learning for finance
- NLP
- Data Engineering & MLOps
Data Science Summit: Machine Learning | 21-22 June | Online and ONSITE
Reach agenda of Machine Learning, Data Mining & Exploration
