
ARTICLES
Scaling up the Prime Video audio/video monitoring service and reducing costs by 90% | 10 min | Streaming | Marcin Kolny | Prime Video Tech Blog
Microservices and serverless components are tools that do work at high scale, but the decision as to whether to use them over monolith or not has to be made on a case-by-case basis.
In the case of Amazon Prime, moving the service to a monolith reduced their infrastructure cost by over 90%. It also increased scaling capabilities.
Building a Flink Self-Serve Platform on Kubernetes at Scale | 7 min | Streaming | Sylvia Lin | tech-at-instacart Blog
Instacart’s used Flink to meet a range of needs like:
- Real-time decision making, such as fraud/spam detection
- Real-time data augmentation, like Catalog data pipelines
- Machine Learning real-time feature generation
- OLAP events ingestion for our experimentation platform
They accomplished all of this by running Flink on AWS’ EMR, so why have they decided to build a new platform on top of Kubernetes? And what are the lessons learned?
The entire Flink service onboarding and operations should be streamlined without K8S details. Most of our platform users don’t have knowledge of Kubernetes, so we should abstract K8S details as much as possible.
The 7 Most Popular Feature Stores In 2023 | 5 min | MLOps | Jakub Jurczak | GetInData | Part of Xebia Blog
In recent years, Feature Stores have become an integral part of many ML projects, and their popularity is continuing to grow. This article will look at the most popular solutions available this year.
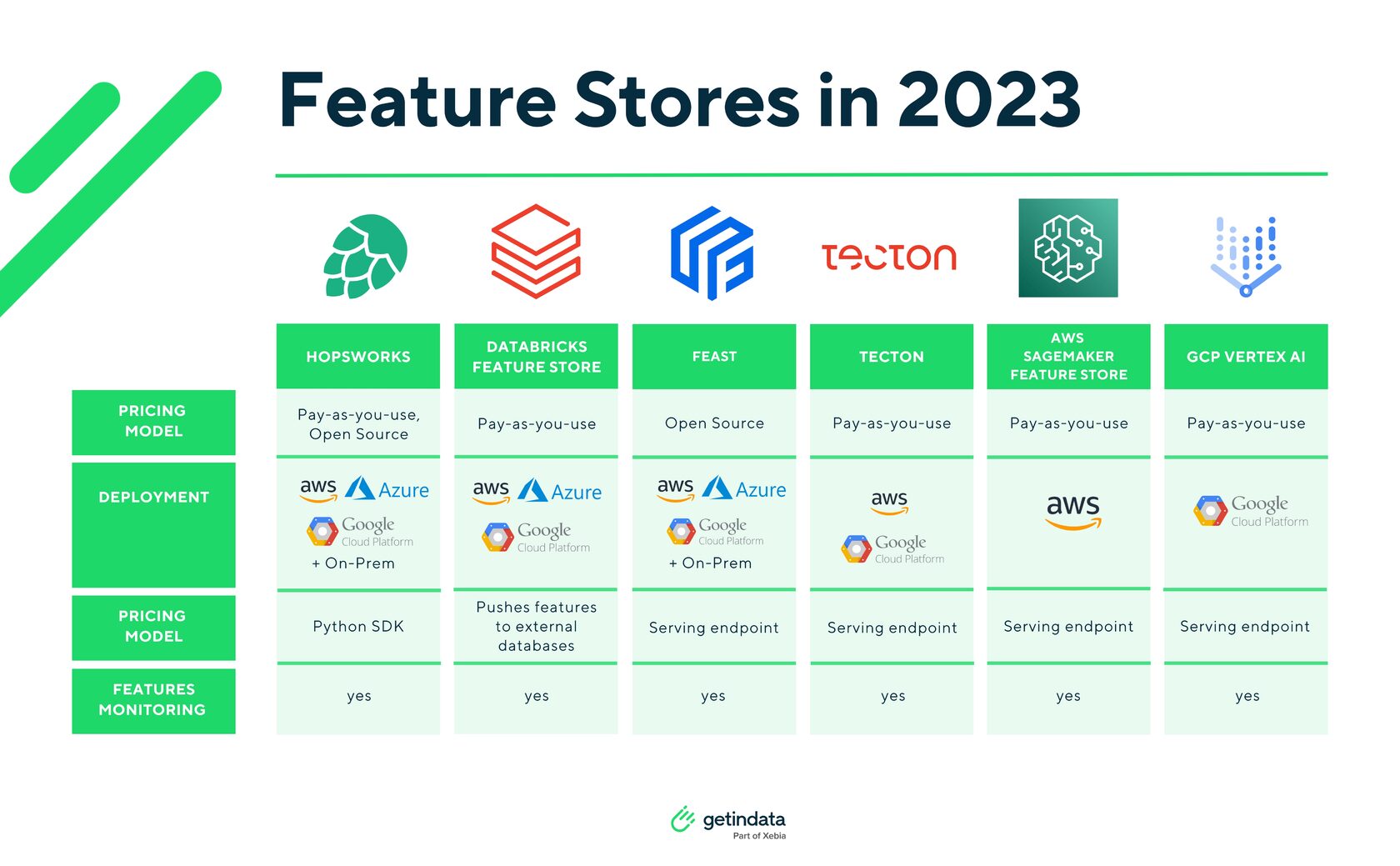
…While we're on the subject of Feature Store, in this ebook, you'll find a step-by-step guide on how to design and build a Feature Store and also how it can solve critical machine learning problems: Build Feature Store Faster. An Introduction to Vertex AI, Snowflake and dbt Cloud
How We Integrated ChatGPT into Our Slack: Enhancing Privacy, Flexibility, and Collaboration | 4 min | Data Science and AI | Rens Dimmendaal | Xebia Blog
ChatGPT has become increasingly popular. Despite its popularity, Xebia spotted some areas for improvement, like privacy, flexibility and collaboration, to make it even better.
To address these issues, they developed an internal tool called SlackGPT.
SlackGPT not only tackles these limitations but also gives our colleagues a unique experience when working with and building modern LLM applications.
Track and improve the performance of streaming data pipelines with Datadog Data Streams Monitoring | 8 min | Data Streaming | Nicholas Thomson, Jane Wang, Jonathan Morin | Datadog Blog
Datadog can now monitor streaming data pipelines with Kafka as a bus.
dbt Squared: Leveraging dbt Core and dbt Cloud together at scale | 12 min | Streaming | João Antunes, Sean McIntyre, Yannick Misteli | dbt Blog
In less than one year, they managed to migrate siloed data pipelines from tools like Informatica, Spark, Talend and Oracle into dbt, powering close to 50 dashboards today.
Trust no one, not even your training data! Machine learning from noisy data | 15 min | ML | Łukasz Rączkowski, Aleksandra Osowska-Kurczab, Jacek Szczerbiński Klaudia Nazarko & Kalina Kobus | Allegro Tech Blog
The problem of label noise is unavoidable in machine learning practice. Fortunately, numerous methods exist that diminish the impact of label noise on prediction performance by increasing the robustness of machine learning models. In experiments The Summit is aimed at people who use the cloud in their daily work to solve Data Engineering, Big Data, Data Science, Machine Learning and AI problems. The main idea of the conference is to promote knowledge and experience in designing and implementing tools for solving difficult and interesting challenges.carried out by Allegro, they implemented 7 of those methods and showed that they increase prediction accuracy in the presence of 20% synthetic noise when compared to the baseline (Cross-Entropy loss), most of them by a significant margin. The simple Clipped Cross-Entropy proved to be the best, with an accuracy score of 89.51% (an increase of 4.2 p.p. vs the baseline trained with noisy labels). This result is very close to the baseline trained with clean labels (90.26%). Thus, we showed that in the case of 20% synthetic label noise, it is possible to increase robustness so that the impact of label noise is negligible.
Building a large scale unsupervised model anomaly detection system: Part 1, Part 2 | 8 min | ML | Rajeev Prabhakar, Han Wang, Anindya Saha | Lyft Engineering Blog
Part 1: the challenges we faced for model monitoring and our strategy for addressing some of these problems. We briefly mentioned using z-scores to identify anomalies
Part 2: a deeper dive into anomaly detection and building a culture of observability.
TOOLS
Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models.
ONEPAGER
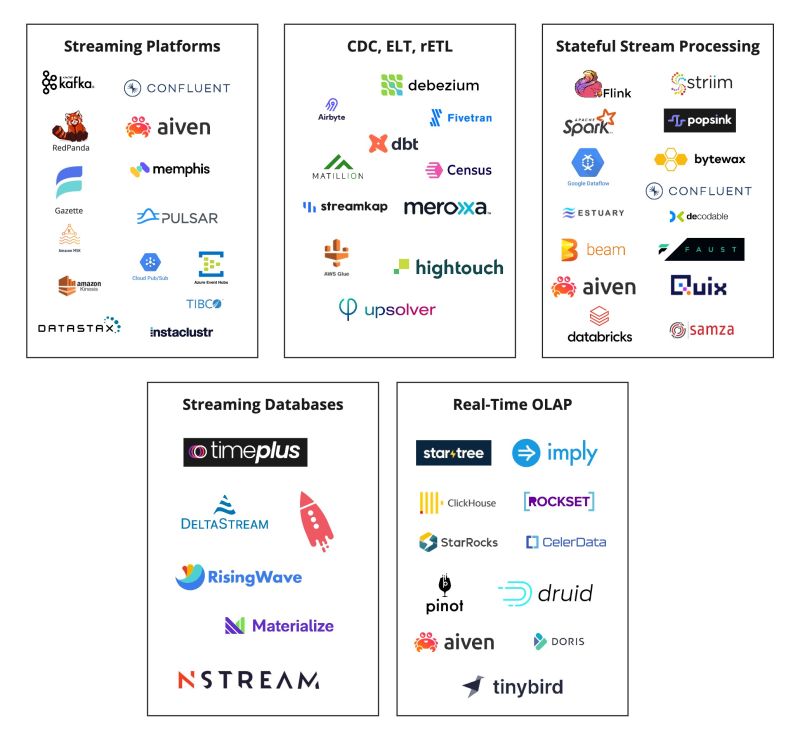
Ecosystem around streaming and realtime including open source solutions with their vendor providers | Hubert Dulay
NEWS
Create Power BI reports in Jupyter Notebooks | 5 min | Power BI | Noam Raveh | Microsoft Blog
Microsoft announces the latest update to the Power BI and Jupyter Notebook library, which empowers users to create powerful reports based on their data directly in their notebooks, without leaving their workflow. With this new update, users can gain insights instantly without the hassle of switching between tools or dealing with cumbersome data exports.
Mark Zuckerberg says Meta wants to ‘introduce AI agents to billions of people’ | 3 MIN | AI | Alex Heath | The Verge Blog
Mark Zuckerberg, CEO of Meta, has stated that generative AI will eventually be integrated into all of the company's products due to its potential impact on billions of users.
DATA ODDITY
The name says it all. Need something to be done by AI? Check out the list of tools, which is getting longer and longer every minute.
PODCASTS
Data Journey with Varun Bhatnagar (Swedbank) - MLOps in the Cloud at Swedbank - Enterprise Analytics Platform | 55 min | MLOps | host: Adam Kawa guest: Varun Bhatnagar | Radio DaTa Podcast
- An overview of the solution: Enterprise Analytics Platform (EAP)
- Evolution of MLOps at Swedbank - How it all started and how the solution has evolved over time.
- Iterative development for ML models - How can one improve the iterative development process for ML models?
- The secret of success - What has led to this successful migration?
- Key take-away points and the lessons learned from our ML cloud transformation journey and how can one start or improve in this area?
DATA Tube
Open Assistant takes on ChatGPT | 1H | host: Tim Scarfe guest: Yannic Kilcher: | Machine Learning Street Talk
Let’s hear about Open Assistant - an ambitious project aiming to create a truly open-source AI language model. Yannic reveals the behind-the-scenes process of developing this revolutionary technology, addressing the critical role of community involvement and the importance of a diverse dataset.
CONFS EVENTS AND MEETUPS
Goodbye, Data Warehouse. Hello, Lakehouse | 18 May | Online webinar
Learn from Databricks, Fivetran and dbt Labs experts about how to:
- Automate data movement and transform raw data into analytics-ready tables using your favorite tools like Fivetran and dbt
- Unify and govern business-critical data at scale to build a curated data lake for data warehousing, SQL and BI
- Reduce costs and get started in seconds with on-demand, elastic SQL serverless compute
- Use automated and real-time lineage to monitor end-to-end data flow
Data Strategy In The World Of Multiple AI Innovations 'almost' Every Week | 9 May | Online webinar
- What is a data strategy, and why do you need one?
- How to build a proper data strategy?
- How to use the latest tools to 10x productivity of your employees?
Data Mass | Call for Presentation | 5th October 2023
The Summit is aimed at people who use the cloud in their daily work to solve Data Engineering, Big Data, Data Science, Machine Learning and AI problems. The main idea of the conference is to promote knowledge and experience in designing and implementing tools for solving difficult and interesting challenges. If you have something to share with the community in this area - submit your presentation!
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
