
ARTICLES
Fast Copy-On-Write within Apache Parquet for Data Lakehouse ACID Upserts | 11 min | Data Engineering | Xinli Shang, Kai Jiang, Huicheng Song, Jianchun Xu, Mohammad Islam | Uber Engineering Blog
Dive into the exciting world of Uber's latest innovations. This article discusses the growing trend of building lakehouses on top of storage table formats like Apache Hudi, Apache Iceberg and Delta Lake for various use cases, including incremental ingestion. Explore the implementation of a row-level secondary index and innovative modifications in Apache Parquet to enhance the upsert data process, leading to significantly faster speeds compared to the traditional copy-on-write methods used in Delta Lake and Hudi.
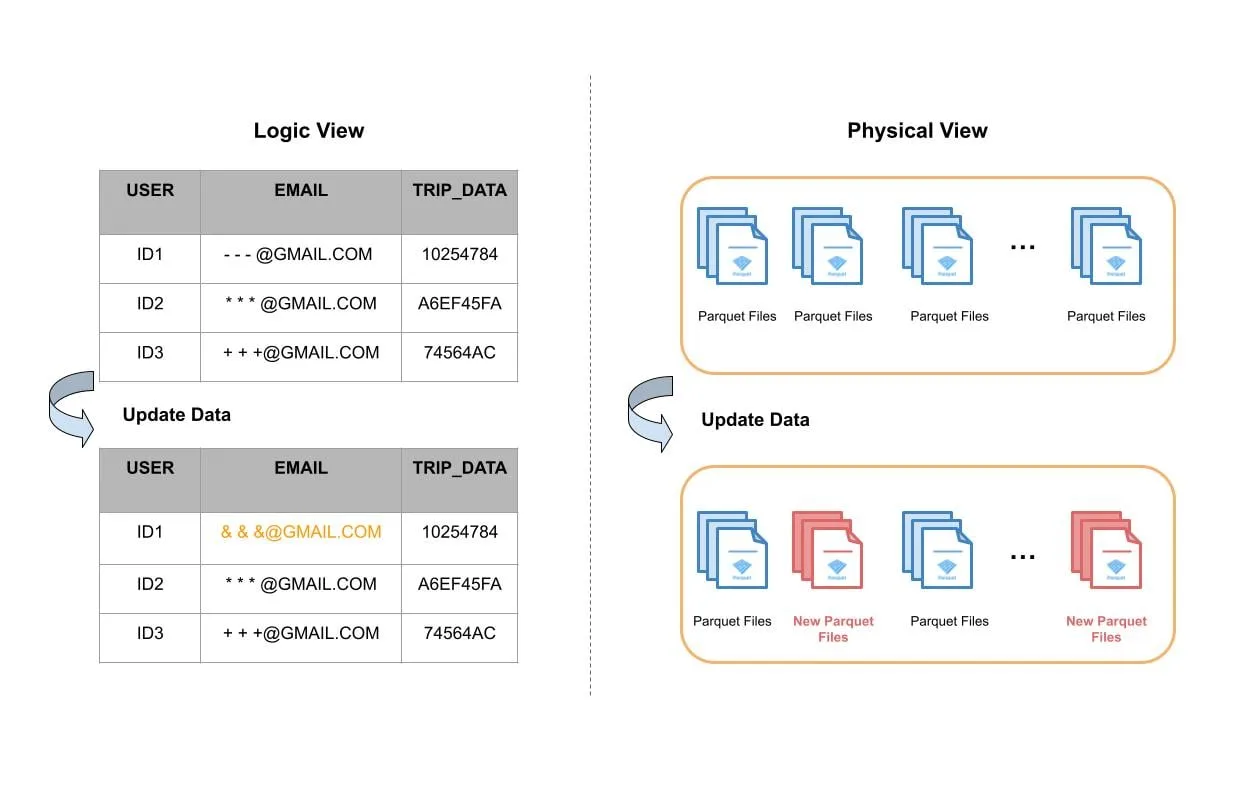
Building Real-time Machine Learning Foundations at Lyft | 10 min | ML | Konstantin Gizdarski, Martin Liu | Lyft Engineering Blog
Lyft's case study on how to develop foundations that would enable the hundreds of ML developers at Lyft to efficiently develop new models and enhance existing models with streaming data.
The Top 3 Data Architecture Trends (And How LLMs Will Influence Them) | 5 min | Data Architecture | Hanzala Qureshi | Towards Data Science Blog
This one gives the lowdown on three major trends that are shaping data architecture and spill the beans on how LLMs can be super useful in each of these areas. So, whether it's the coolness of context-driven analytics, the importance of data governance, or the buzz around Co-Pilot, this article spills all the details on what's happening in the world of data architecture.
Introduction to dbt Cloud - features, capabilities and limitations | 6 min | Data Analytics | Radosław Dziadosz | GetInData | Part of Xebia Blog
Discover how it revolutionizes data engineering workflows, empowering teams to build scalable and maintainable data pipelines effortlessly.
Google Bard’s New Visual Feature is a Game Changer | 6 min | AI | Thomas Smith | The Generator Blog
Explore the latest game-changing visual feature introduced by Google Bard in this captivating article. Uncover the advancements made by Google Bard and how it has transformed the visual experience for users.
TUTORIALS
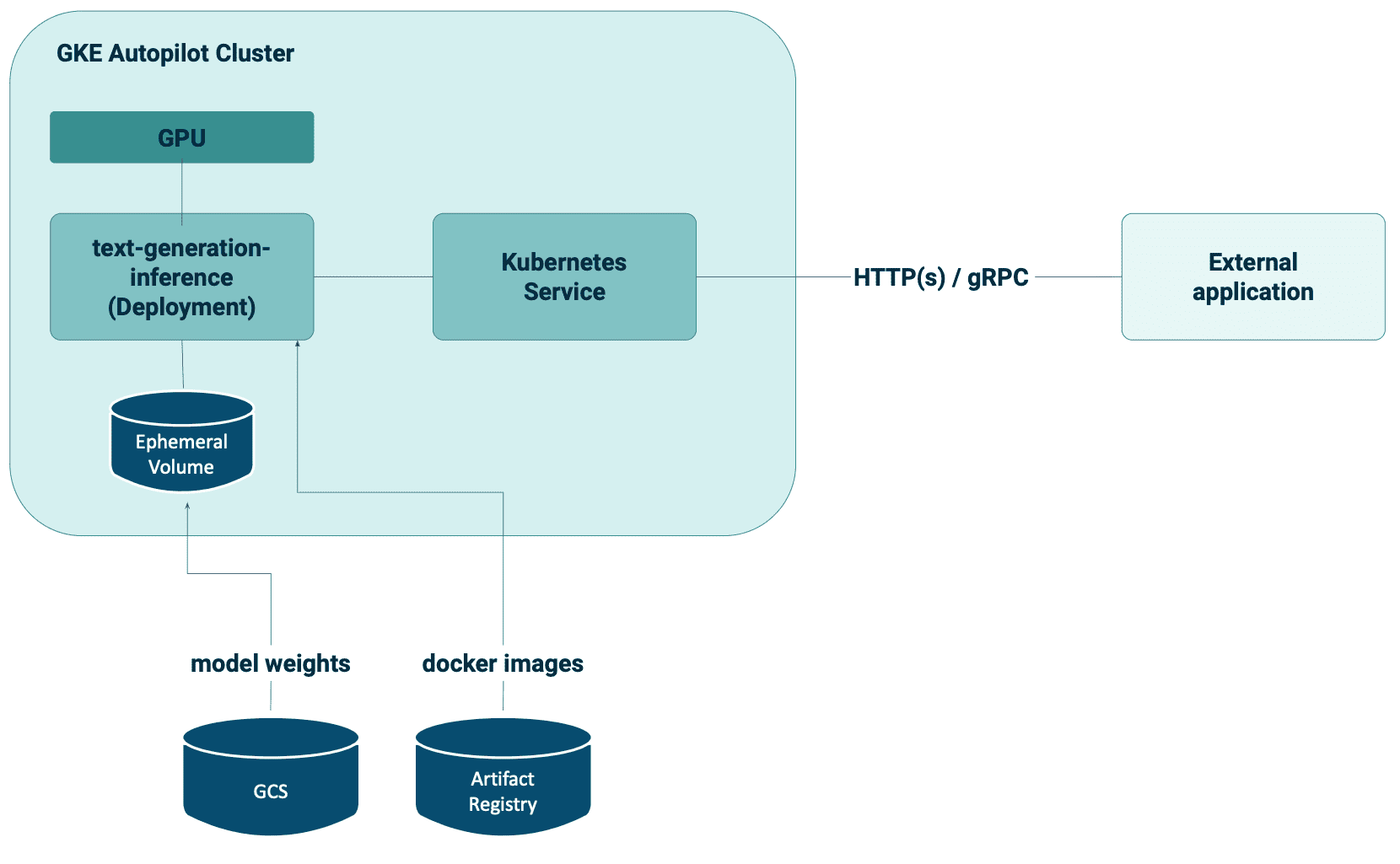
Falcon LLM: Deploy open source LLM in your private cluster with Hugging Face and GKE Autopilot | 12 min | LLM | Marcin Zabłocki | GetInData | Part of Xebia Blog
This tutorial delves into the seamless deployment of an open-source Language Model (LLM) private cluster by leveraging Hugging Face and Google Kubernetes Engine (GKE) Autopilot.
Use a generative AI foundation model for summarization and question answering using your own data | 7 min | LLM | Randy DeFauw | AWS Blog
Once you have a solid LLM, you’ll want to expose that LLM to business users to process new documents, which could be hundreds of pages long. In this post, Randy demonstrates how to construct a real-time user interface to let business users process a PDF document of arbitrary length. Once the file is processed, you can summarize the document or ask questions about the content.
NEWS
Never Miss a Beat: Announcing New Monitoring and Alerting capabilities in Databricks Workflows | 4 min | Data Engineering | Roland Fäustlin, Frank Wisniewski | Databricks Blog
Enhanced monitoring and observability features in Databricks Workflows! This includes a new real-time insights dashboard to see all your production job runs in one place, advanced and detailed task tracking for every workflow, and new alerting capabilities to help you catch issues before problems arise.
Google Cloud expands availability of enterprise-ready generative AI | 5 min | AI | Warren Barkley | Google Cloud Blog
Google Cloud announces the general availability (GA) of four important foundation models for Vertex AI. These include Imagen, PaLM 2 for Chat, Codey, and Chirp. For each of these models, organizations can access APIs on Model Garden and do prompt design and tuning on Generative AI Studio. Also, Multimodal Embeddings API in preview which lets customers combine the power of Vertex AI’s generative AI models with their proprietary data, to generate embeddings, or interchangeable vector representations, of their text and image data.
TOOLS
MyMLOps | 2 min | MLOps
Experience the convenience of visualizing your MLOps stack directly in your browser with MyMLOps. This project offers a user-friendly tool stack builder, providing brief insights into various tools and their categories. You can also share your customized stack with others.
DATA TUBE
Architecture of Netflix's Data Mesh. Data mesh use cases | 41 min | Data Mesh | Jordan Lewis, Vlad Sydorenko | CockroachDB
Dig into Netflix's Data Mesh architecture, use cases and how it optimizes data insights without database slowdowns. Discover how Netflix's Data Mesh Platform addresses challenges with multiple writes, providing a powerful solution for your data needs.
You will learn all about the following:
- CDC use cases and shortcomings
- How Netflix uses changefeeds today
- What Netflix’s data mesh architecture looks like
- What others can learn from Netflix’s architecture
PODCAST
How Data Engineering Teams Power Machine Learning With Feature Platforms | 1 h 4 min | ML | Tobias Macey, Razi Raziuddin | Data Engineering Podcast
Razi Raziuddin delves into the significance of data engineering and machine learning feature platforms. The discussion centers around these platforms' crucial role in supporting the machine learning workflow and how data engineering teams can enable data scientists and ML engineers to develop and maintain their features effectively.
CONFS EVENTS AND MEETUPS
An Intro to LLMs: Key Challenges and Best Practices when Deploying at Scale | Webinar | 5 pm CEST | 27th July
Discover the potential of Generative AI and LLMs for your organization with Seldon's technical team. They will guide you through the opportunities and challenges of these game-changing technologies, demonstrating how leveraging LLMs can automate tasks at scale and in a personalized manner. While these advances in ML have unlocked numerous use cases, the experts will also address important considerations such as data privacy, consistency and ethical concerns, to help you make the most of these innovations.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
