
ARTICLES
3 Ways to Extract Data Lineage with Airflow | 7 min | Airflow | Howard Yoo | Astronomer Blog
Howard explains how to use Airflow’s operators, custom extractors and inlet/outlet arguments to send lineage to your data observability tool. You will explore three ways that Airflow can emit data lineage information to a data observability backend:1) using the already supported operators,
2) developing your own custom extractor
3) using inlet and outlet arguments in an operator.
Drug Discovery with Deep Learning | 7 min | Deep Learning | Kian Kenyon-Dean, Jake Schmidt, John Urbanik, Ayla Khan, Jess Leung, Berton Earnshaw | MLOps Community Blog
Instead of building specific models for each disease we want to find treatments for, the experts have built models that generalize across diseases. Read more about the challenges, using techniques that include deep learning, transfer learning and domain adaptation to design target-agnostic models.
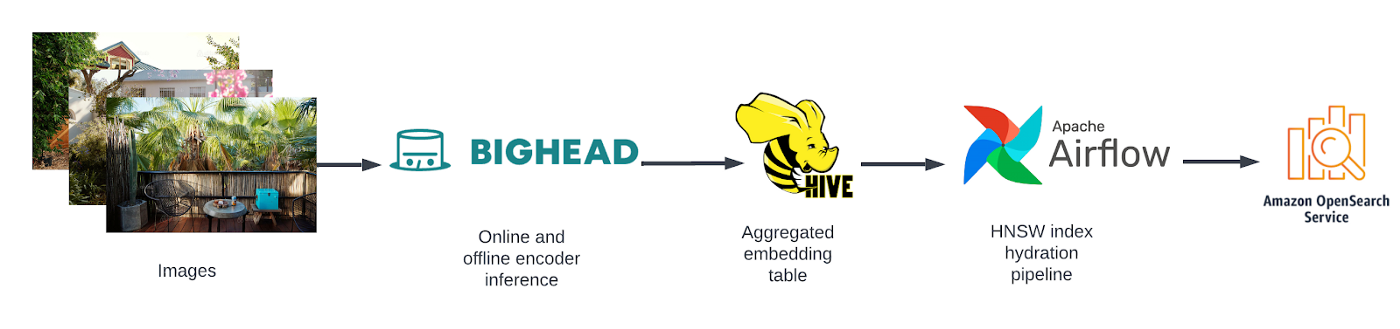
When a Picture Is Worth More Than Words | 8 min | ML | Yuanpei Cao, Bill Ulammandakh, Hao Wang & Tony Hwang | Airbnb Blog
How Airbnb leverages image aesthetics and embeddings to optimize across various product surfaces including ad content, listing presentation and listing recommendations.
Introducing the dbt_project_evaluator: Automatically evaluate your dbt project for alignment with best practices | Data Analytics | 7 min | Grace Goheen | dbt Blog
Read how the dbt team compressed all of their ideas about best practices into a single, actionable tool to automate the process of discovering these misalignments. From now on, analytics engineers can immediately understand exactly where their projects deviated from their best practices and are empowered to improve their projects on their own.
Databricks vs Snowflake – December 2022 Take | 7 min | Blueprint Blog
Snowflake and Databricks are both good data platforms for BI and analysis purposes. Selecting the best platform for your business depends on your data strategy, usage patterns, data needs and volumes and workloads. This article shows the differences and pros and cons between the two of them.
Are Data Silos Distorting Your Product Analytics? | Data Analytics & BI | 5 min | Abhishek Rai | NetSpring Blog
This text explains to you why modern cloud data warehouses are better than data silos and discusses four areas: inconsistent data, missing data, the data model and governance that are problematic when you are using data silos.
Wayve's End-to-End Deep Learning Model for Self-Driving Cars | 4 min | Deep Learning | Bruno Santos | InfoQ Blog
Wayve, a company focused on deep-learning AI tech, released a state-of-the-art, end-to-end model for learning a world model and vehicular driving policy based on simulation data from CARLA, allowing the cars to drive autonomously without HD maps.
Mitigating the winner’s curse in online experiments | 10 min | Experimentation | Stephane Shao | Etsy Blog
The way Etsy choose which changes to deploy follows a traditional hypothesis testing approach. If randomly exposing a small group of users to a particular treatment (a new design, added functionality, etc) yields a positive lift in some metric of interest — and if that lift qualifies as statistically significant (unlikely to be due to chance alone in the absence of any effect) — then we call the treatment a “win” and feel confident in deploying it at scale. However, when they try to gauge the underlying effect of that winning treatment, naively taking the observed lift at face value will lead to an estimate that overshoots the mark. This phenomenon — commonly referred to as the winner’s curse — is a built-in limitation of the decision-making protocol. In this article, Stephane reviews how Etsy's experimentation framework gives rise to the winner’s curse.
Why and How eBay Pivoted to OpenTelemetry | 9 min | Kubernetes | Vijay Samuel | ebay Blog
EBay uses the Metricbeat agent to scrape around 1.5 million Prometheus endpoints every minute, which are ingested into the metric stores. The observability platform operates at a massive scale, which brings with it new challenges. In this blog post, Vijay discusses some of the problems, especially for metrics scraping. How eBay has been navigating the evolving open-source landscape with regards to licensing and how they intend to align with OpenTelemetry as an initiative.
TUTORIALS
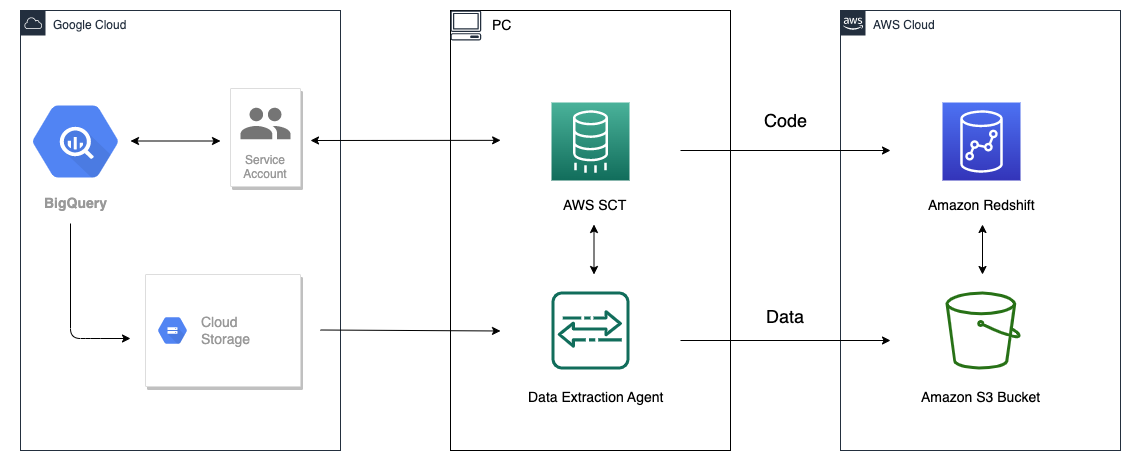
Migrate Google BigQuery to Amazon Redshift using AWS Schema Conversion tool (SCT) | 15 min | BigQuery | Jagadish Kumar, Anusha Challa, Amit Arora & Cedrick Hoodye | AWS Blog
Migrating a data warehouse can be a challenging, complex and yet rewarding project. AWS SCT reduces the complexity of data warehouse migrations. Following the walkthrough shown in this blog post, you can understand how a data migration task extracts, downloads and then migrates data from BigQuery to Amazon Redshift. This solution performs a one-time migration of database objects and data. Data changes made in BigQuery when the migration is in progress won’t be reflected in Amazon Redshift. When data migration is in progress, put your ETL jobs to BigQuery on hold, or replay the ETLs by pointing to Amazon Redshift after the migration.
Run your Databricks SQL queries from VSCode | Databricks | 3 min | Ganesh Chandrasekaran | Personal Blog
A short post about a new extension available in VS Code Marketplace. Read step-by-step instructions on how you can execute your SQL queries from the comfort of your favorite VS Code IDE.
PODCAST
What’s Next for Machine Learning in Time Series | 38 min | ML | host: Ben Lorica; guest: Ira Cohen | The Data Exchange
Ira Cohen is the co-founder and Chief Data Scientist at Anodot1, a startup that uses time series tools to monitor business data in real time. In this episode, he discusses the many existing challenges faced by teams who deal with time series.
CONFS EVENTS AND MEETUPS
Big Data Technology Warsaw Summit | 29-30 March | Early Birds Price Registration | Online & Onsite Conference
3 keynote speakers at Big Data Technology Warsaw Summit 2023!
- Maciej Dzięcielak / Veolia - The chief IT Architect who will bridge the gap between business and technology. Good at active listening and experienced with gathering business requirements which translates into IT solutions, enjoys and thrives in challenging and demanding environments.
- Lukasz Hunka / PKO Bank Polski - Director of SME Risk & Analytics PKO Bank Polski. Currently navigating the migration of the risk analytical environment to Google Cloud and setting up MLOps culture among data scientists.
- Nikhil Simha / Airbnb - Nikhil leads the Machine Learning infrastructure team at Airbnb. He is currently working on Chronon, an end-to-end feature engineering platform.
Machine Learning by Doing | HacDC | 16 December | Online
During this meeting, the host and participants will choose a small ML problem or exercise and write code to solve it. This meetup is targeted towards people who have some coding and maths experience but doesn't require much ML expertise.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
