
ARTICLES
Distributed Data Governance and Isolated Environments with Unity Catalog | 8 min | Data Engineering | Max Nienu, Zeashan Pappa, Paul Roome and Sachin Thakur | Databricks
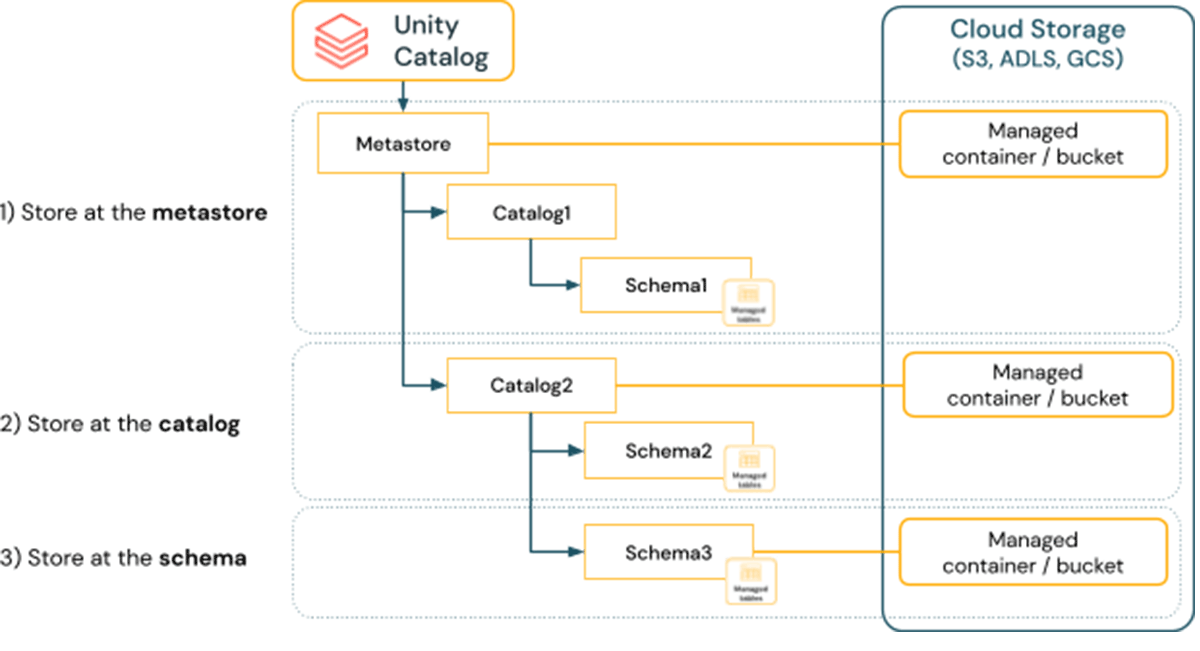
A great overview of Unity Catalog and its significant impact on cross-team and cross-environment collaboration. This article also covers the importance of isolation boundaries in a data platform, such as between development and production environments, as well as between different teams or operating units within an organization. To ensure effective isolation, it's essential to define clear access rules for users, designate responsible individuals or teams to manage the data, physically separate data in storage and restrict access to designated environments.
Can AI automatically fix and optimize IT systems like Flink or Spark? | 7 min | AI | Marcin Kacperek | GetInData | Part of Xebia Blog
In recent years, there have been many predictions about what areas of our lives will be automated and which professions or services will become unnecessary. And these are not from sci-fi books, but research-backed analyses.
- How does this relate to the IT industry?
- Will ML models be able to solve system problems and optimize #Flink, #Spark or other data processing systems?
- Or even replace fully-fledged software engineers?
Let’s find out.
Since we are talking about Flink, here is an interesting Senior Data Engineer position.
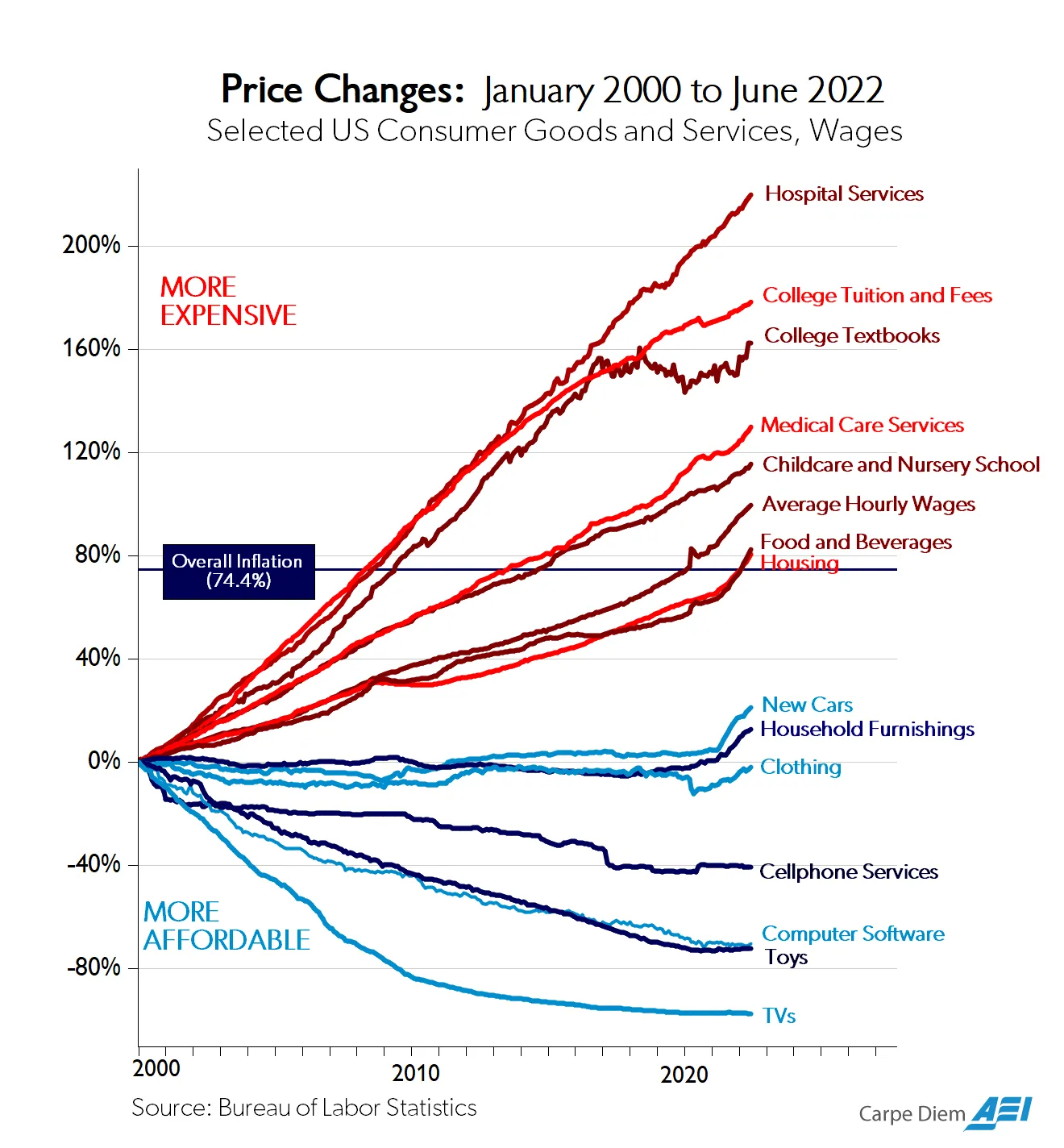
Why AI Won't Cause Unemployment | 5 min | AI | Marc Andreessen | Marc Andreessen Substack
Andreessen gives a refreshing perspective on the role of AI in our economy, emphasizing the opportunities it presents rather than the doom and gloom often associated with technological change. While it is true that AI will disrupt certain industries and jobs, it is important to focus on how we can adapt and capitalize on the new opportunities it creates.
The future of nested datatypes in analytics pipelines | 7 min | Data Analytics | Sara Landfors, Robert Sahlin, María García García, Ji Krochmal | Heroes of Data
This one discusses the concept of nested data types and their importance in the field of data science. Check out three leaders in the data point of the view about semi-structured data to understand what it’s all about. All of them answered the following three questions:
- What's an example of how your organization uses semi-structured/nested data (for analytics purposes) today?
- What role do you envision that semi-structured/nested data will have in the future "Modern Data Stack"?
- What hindrances do you foresee that will slow down the adoption of semi-structured/nested data in analytics pipelines?
Y Combinator–backed Patterns is building a platform to abstract away data science busywork | 5 min | MLOps | Kyle Wiggers | TechCrunch
A short story on how Van Haren and Stanley launched Patterns, a platform that abstracts away AI model engineering. Read about what you can build with Patterns and how this provides a fast and powerful way to develop and deploy AI into real problems.
Benchmarking , Snowflake, Databricks , Synapse , BigQuery, Redshift , Trino and DuckDB using TPCH-SF100 | 5 min | Cloud | Mim | Data Monkey Site
Let’s dive into benchmarking popular cloud-based data warehousing solutions using the TPC-H SF100 benchmark. The author measures performance in terms of query execution time, cost and scalability.
TUTORIAL
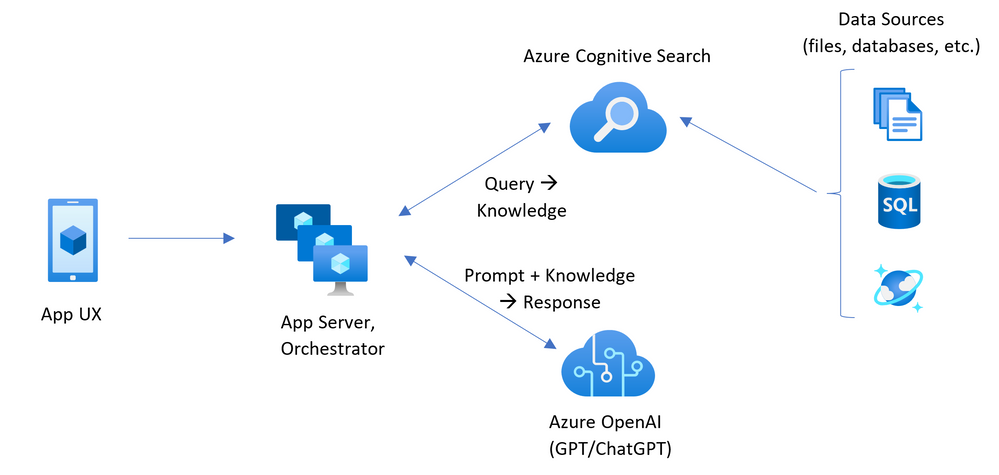
Revolutionize your Enterprise Data with ChatGPT: Next-gen Apps w/ Azure OpenAI and Cognitive Search | 7 min | Cloud | Microsoft Blog
Read the conversation and question answering scenarios that combine ChatGPT from Azure OpenAI with Azure Cognitive Search as a knowledge base and retrieval system. There are other ways in which Azure OpenAI Service and Cognitive Search can be combined to improve existing scenarios or enable new ones. Examples include using natural language for query formulation, powering catalog browsing experiences and using Azure OpenAI at indexing time to enrich data.
NEWS
GPT-4 | 12 min | AI | OpenAI Blog
Most of us have been waiting for this. GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning, is out now. Read how OpenAi spent 6 months working on their best-ever results on factuality, steerability and refusing to go outside of the guardrails.
PyTorch 2.0 announcement | 14 min | ML | PyTorch Blog
If you attended the PyTorch Conference in December 2022, you could have heard a highlight about PyTorch 2.0. Now it has been officially released. It offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at the compiler level under the hood, with faster performance and support for Dynamic Shapes and Distributed.
It also includes:
- A stable version of Accelerated Transformers (formerly called Better Transformers),
- Beta includes torch.compile as the main API for PyTorch 2.0, the scaled_dot_product_attention function as part of torch.nn.functional, the MPS backend, functorch APIs in the torch.func module,
- other Beta/Prototype improvements across various inferences, performance and training optimization features on GPUs and CPUs.
VIDEO
How Swedbank Unlocks Advanced Analytics – Vineeth Menon of Swedbank | 22 min | Cloud | Vineeth Menon | Immuta
The Head of Data Lake Engineering at Swedbank discusses their cloud migration. He touches on issues with the compliance process, security challenges and highlights their achievement as the first Nordic bank with a fully cloud-based advanced analytics platform.
Kedro + PyTorch. MLOps TUTORIAL | 33 min | MLOps | Marcin Zabłocki | GetInData | Part of Xebia
How to combine Kedro and PyTorch in one machine learning project? Is this a good combination? The answer is: YES! In this tutorial, Marcin Zabłocki shows how to leverage all features from Kedro and PyTorch
- Kedro → abstraction of a pipeline, nodes and parameters; data catalog; environments
- PyTorch → neural networks; distributed computing; data preprocessing; datasets in one ML project without ANY sacrifices or workarounds.
CONFS EVENTS AND MEETUPS
Scalar Talks | 24th March 2023 | 12:30 PM | Onsite
It is time to discuss the latest Scala trends and use cases, and meet Scala enthusiasts from all around the world. 12 presentations are waiting for you on 24th March in Warsaw, for example:
- Full-Stack Scala 3 with the Typelevel Stack
- How to build lightweight microservices using ZIO stack
- Fixing-up Production with Property-based Testing
One of them, “Pretty little compilers” will be given by Valentin Kasas
…and way more.
Big Data Technology Warsaw Summit | 29-30th March 2023 | Hybrid
- You'll get to hear from some of the top experts in the field, with speakers from companies like Meta, Google, Airbnb and Xebia
- You'll learn about the latest trends and technologies in big data, AI, data engineering, real-time streaming, cloud, data science, MLOps and how they can be applied to real-world problems.
- You'll have the opportunity to network with other professionals and make valuable connections in the industry during discussions in 20 round tables.
Use the code DataPill10 to get a 10% discount.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
