
ARTICLES
What I Got Wrong: Looking Back at My 2022 Predictions for the Modern Data Stack | 14 min | Modern Data Stack | Prukalpa | Personal Blog
Before the predictions for 2023, let’s take a step back into the past and check the reflections on six major trends from 2022 that Prukalpa made at the beginning of this year. What did we get right? What didn’t quite go as expected? What did we completely miss? Read more about
where we started and where are we now with:
1.Data Mesh
2.Metrics Layer
3.Reverse ETL
4.Active Metadata & Third-Gen Data Catalogs
5.Data Teams as Product Teams
6.Data Observability
T-Mobile Supports 5G Rollout with Azure Synapse Analytics and Power BI | 7 min | Data | Microsoft Blog
A short story about building a nationwide 5G network. Read how T-Mobile, who use Power BI built a centralized source of data, maintaining high levels of performance and functionality using a data lakehouse supported by Microsoft Azure Data Factory, Azure Synapse Analytics and Azure Databricks.
Migrating over 30 data models from plain SQL to DBT in just 5 days | 4 min | dbt |Ramtin Javanmardi| Mentimeter Blog
All the reasons why the company felt compelled to migrate over 30 of their models and sunset the old models explained. They did the migration in three distinct steps, which you can read about. A great example of how big migrations of business-critical models do not have to be boring or feel stressful.
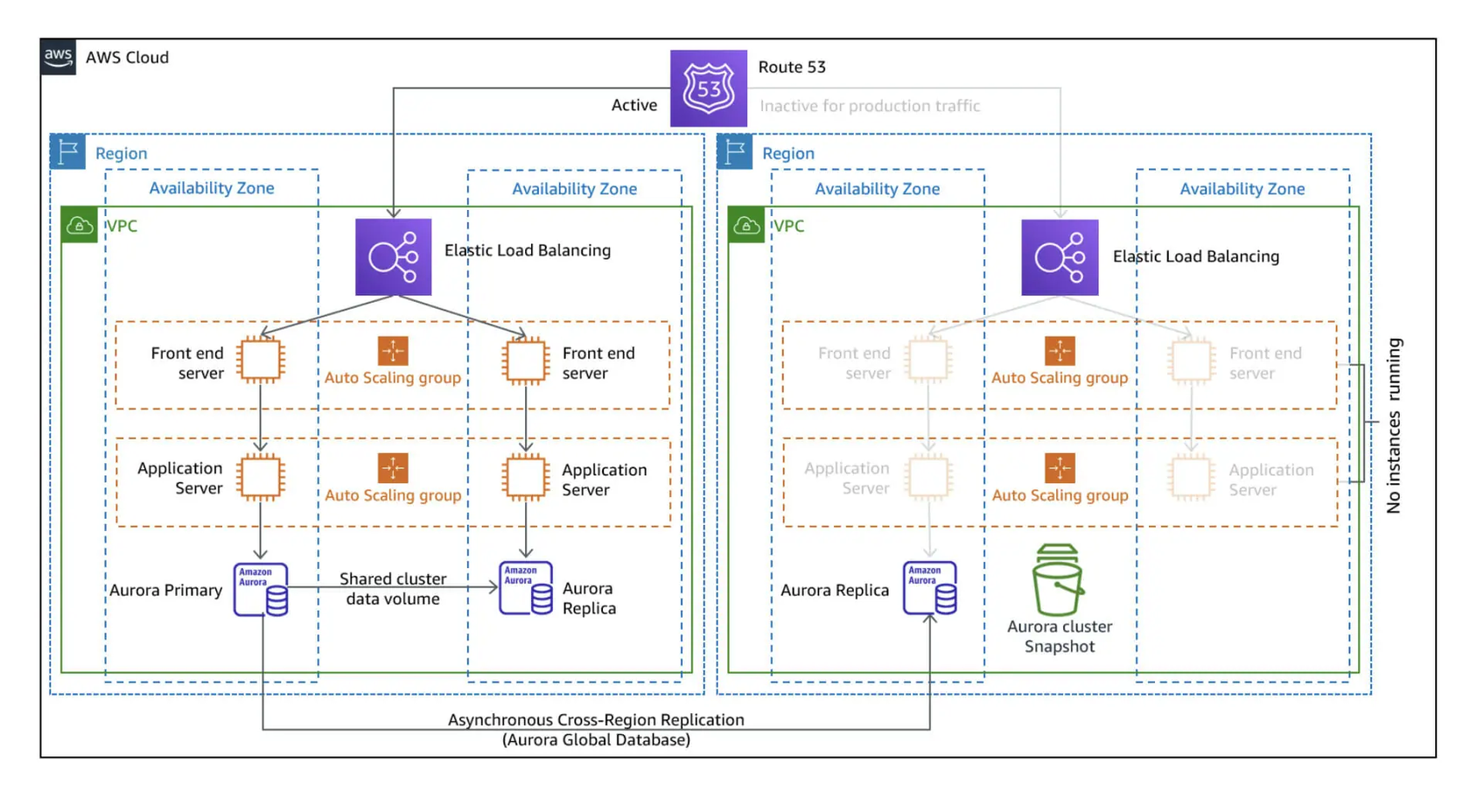
AWS Disaster Recovery Strategies – PoC with Terraform |10 min | AWS | Martin Perez Rodrigues | Xebia Blog
In this article you can explore a proof-of-concept written in Terraform, where they will for example create the front-end layer of three-tier architecture.
Traits Of Highly Productive Data Engineers | 6 min | Data Engineering | Ramtin Javanmardi | QuantumBlack, AI by McKinsey Blog
We are starting 2023 soon and you are probably thinking about your new year’s resolutions. If one of them is better productivity then this article is for you. Here are some tips:1. Validate your choice of no-code tools with business needs
2. Learn to make the buy vs build tradeoff
3. Leverage open-source to harness the power of the community
4. Don’t get attached to one tool
5. Investing time in learning is crucial
6. Sharing best practices and standardizing code to prevent re-work
7. Keep your eyes on the product
8. Balance the short-term with the long-term needs of the business
Lessons from A/B Testing on Bandit Subjects | 7 min | ML | Shichao Ma | Yelp blog
Compared to full-scale ML, a multi-armed bandit is a lightweight solution that can help teams to quickly optimize their product features without major commitments. However, bandits need to have a candidate selection step when they have too many items to choose from. Using A/B testing to optimize the candidate selection step causes new bandit bias and convergence selection bias. New bandit bias occurs when we try to compare new bandits with established ones in an experiment; convergence selection bias creeps in when we try to solve the new bandit bias by defining and selecting established bandits. We discuss our strategies to mitigate the impacts of these two biases..
4 pragmatic enablers of data-driven decision making | 13 min | data-driven | Piotr Menclewicz | GetInData Blog
If you are thinking about making your company more data-driven, in this blog post, you will find four enablers which will help you along the way:
- A roadmap of data initiatives,
- A modern data technology stack,
- Value-oriented analytical use case delivery,
- Data democratization.
Julia vs Python - Which Should You Learn? | 11 min | Languages | Team | Datacamp Blog
- speed, accessibility, purposefulness - these are the advantages of Julia
- accessibility, versatility, open-source, libraries - these are the advantages of Python
What disadvantages do they have? Why should we use them? You can find the answers to these questions in the blog post
How we use GitHub to be more productive, collaborative, and secure | 5 min | Github | Mike Hanley | GitHub Blog
Our engineering and security teams have done some incredible work in 2022. Let’s take a look at how we use GitHub to be more productive, build collaboratively, and shift security left.
How Einride is taking road freight to new places—on the cloud and on the road | 12 min | Google Cloud | Matt Chaban | Google Cloud Blog
Einride is rethinking every piece of the freight system, from trailers to local deliveries to the remote and autonomous platforms to operate them. If you want to check how they plan to create a sustainable, resilient delivery network using AI and tech, read this blog post.
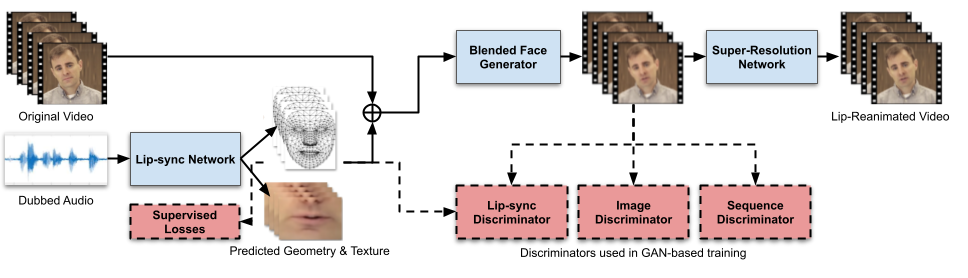
Improving Video Voice Dubbing Through Deep Learning | 12 min |TensorFlow | Paul McCartney, Vivek Kwatra, Yu Zhang, Brian Colonna, Mor Miller | Google Developers
Did you know that most of the videos on Youtube are in English but less than 20% of the world’s population speak English as a first or second language? This is why voice dubbing is increasingly used to transform video in other languages. In this blog post you can read about the research of voice dubbing quality using deep learning.
TUTORIALS
4 ways to optimize your BigQuery tables for faster queries | 15 min | BigQuery | Kelvin Gakuo | Airbyte Blog
Read this step-by-step tutorial where you will explore design patterns of your BigQuery storage that you can use to increase the speed and performance of your queries. To optimize your workloads on BigQuery, you can optimize your storage by:
1. Partitioning your tables.
2. Clustering your tables.
3. Pre-aggregating your data into materialized views.
4. Denormalizing your data.
In this blog post, you will also read about BigQuery storage and compute costs, how to investigate BigQuery performance issues, and more.
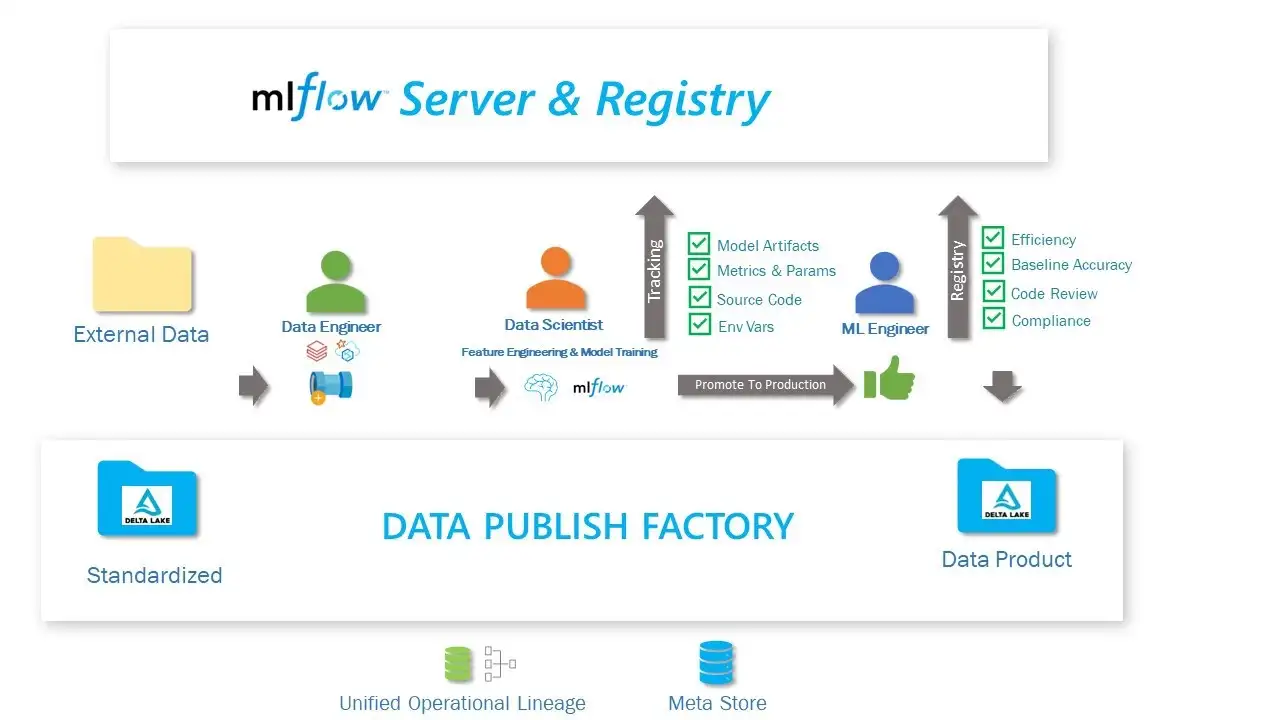
Meshing MLOPS on Azure with MLFlow | 6 min | MLOps |Keshav Singh | Personal Blog
In this blog Keshav will establish the ML life cycle leveraging MLFlow – an open source machine learning platform and framework for managing ML life cycle. It is a short hands-on demonstration of the MLOPs standardization on a Mesh Platform.
Why we chose Apache Superset as our data exploration platform | 8 min | Data Science/Analytics | Bogdan Kyryliuk | Dropbox Tech Blog
After reading this one, you will know why the Dropbox team chose Apache Superset. They explain the problem they started with, evaluating data exploration tools and the results they gave them. Also, in this blogpost you can find the Data Visualization Platform Comparison Matrix.
Transactions in MongoDB | 12 min | Transaction | Piotr Kisielewicz | Allegro Tech Blog
A database transaction is a unit of work, designed to handle the changes of data in the database. It makes sure that the output of the data is consistent and doesn’t generate errors. It helps with concurrent changes to the database, and makes the database more scalable.
In this blog post you can find a step by step tutorial on how to use transactions in MongDB.
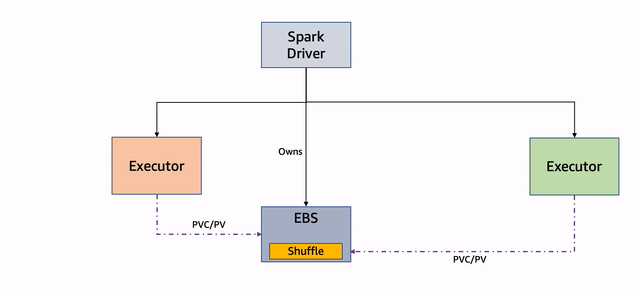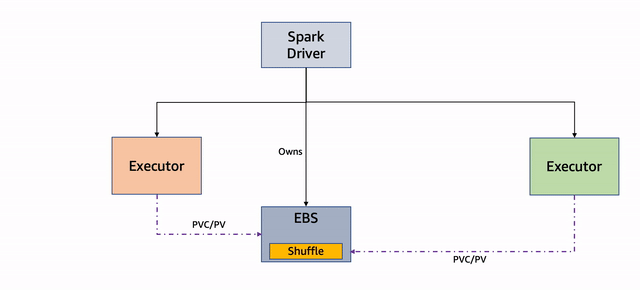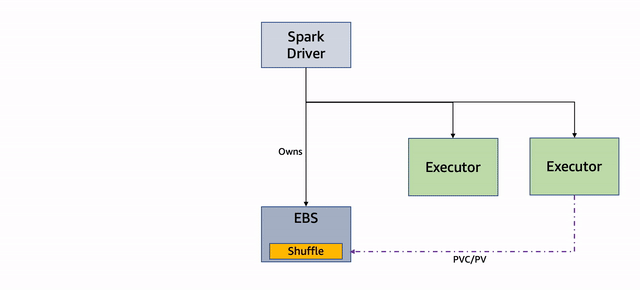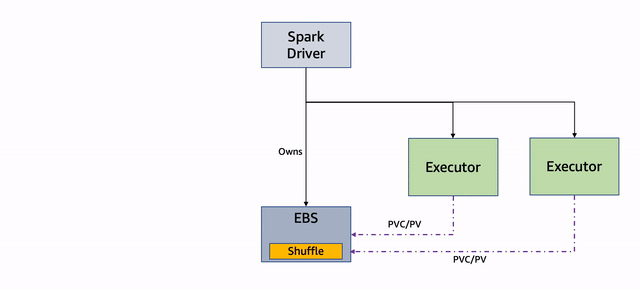
Run fault tolerant and cost-optimized Spark clusters using Amazon EMR on EKS and Amazon EC2 Spot Instances | 10 min | AWS | Kinnar Kumar Sen | AWS Big Data Blog
In this post, Kinnar discusses the features of Node Decommissioning and Persistent Volume Claim (PVC) reuse and their impact on increasing the fault tolerance of Spark jobs on Amazon EMR and EKS when optimizing using EC2 Spot Instances.
Scaling ML Model Development With Mlfow | 10 min | ML | Nwoke tochukwu | ML Community Blog
In this blog post you can find:
- A wee introduction code to MLflow
- MLflow UI
- MLflow single run UI
- Roadmap sketch
- How to set up the MLflow SDK interface and protocol
- Read the parameters function
- Setters and getters for the main class
- Example from the MLflow tutorial about training tracking
- The main training function, that can be called to record all the model artifacts
- Log any metadata and model file to the MLflow server
- A module to start and complete a training job session recording with MLflow
NEWS
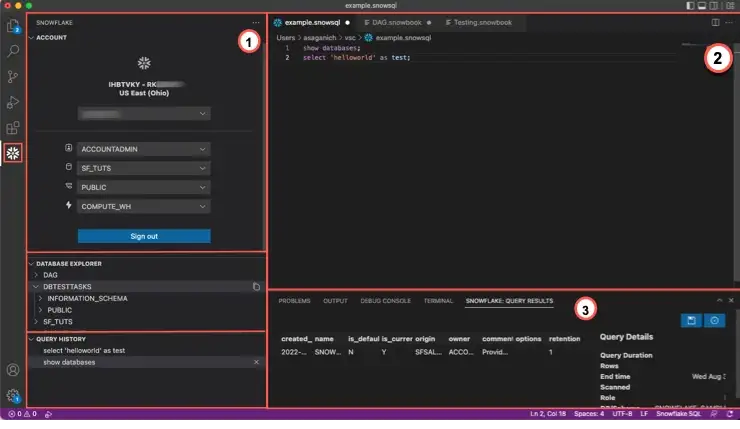
Snowflake introduces Add-On for Microsoft Visual Studio| 2 min | Snowflake | Christian Lauer | Personal Blog
The add-on makes it possible for developers to gain access to Snowflake from within the VS Code architecture. This extension also connects the user to Snowflake and enables them to write and execute SQL queries, but also to see the results without ever leaving the VS Code. After one has successfully signed in, they can see and change their active database, schema, role and whole warehouse
Grafana Releases New Frontend Observability SDK and Backend Profiling Database | 6 min | Grafana | Matt Capbell | InfoQ
Recently Grafana announced two new additions to its suite of observability and monitoring tools
Debezium 2.1.0.Final Released | 5 min | Database | Jiri Pechanec| Debezium Blog
"You might recently noticed that Debezium went a bit silent for the last few weeks. No, we are not going away. In fact the elves in Google worked furiously to bring you a present under a Christmas tree - Debezium Spanner connector."
PODCAST
Update your model’s view of the world in Real Time with streaming Machine Learning using River | 1 h 16 min | The Python Podcast.__init__
River is a framework for building streaming machine learning projects that can constantly adapt to new information. Listen to the podcast episode, where Max Halford explains how the project works, why you might (or might not) want to consider streaming ML, and how to get started building with River. You will also find answers to questions, for example:
- What is "online" machine learning?
- How is the River framework implemented?
- What are some of the challenges that users of River might run into if they are coming from a batch learning background?
- When is River the wrong choice?
Top 6 Worst Apache Kafka JIRA Bugs | 1 h 10 min| guest: Anna McDonald | Confluent
After listening to this episode you will get to know the details about how batching works, the replication protocol, how Kafka’s networking stack dances with Linux’s one and which is the most important Scala class to read if you’re only going to read one.
Anna gives Kris the details about the bugs that she found and about some of the scariest, most surprising, and most enlightening corner cases.
DATA TUBE
Customer showcase: Miro (hosted by dbt Labs) | 60 min | Modern Data Stack | dbt Labs
In this video, Felipe Leite and Stephen Pastan from Miro unpack their shift to a Modern Data Stack and share the vital technical changes they made to build a scalable and tech-forward data stack. Watch this to discover how to efficiently scale your analytics stack when your data and data team grows 10x in 2 years and start prioritizing what gets done when there's that much growth.
CONFS EVENTS AND MEETUPS
Near Real-Time Anomaly Detection With Delta Live Tables and Databricks Machine Learning | 9 January 2023 at 9am GMT; 10am CET | Live webinar
Join the webinar featuring Achraf Hamid, Data Scientist at Mailinblack, who will explore the importance of anomaly detection for businesses. The session will also examine how to solve common anomaly challenges, and achieve a near real-time anomaly detection system using the Databricks Lakehouse Platform.
Speakers:
- Achraf Hamid, Data Scientist at MAILINBLACK
- Michael Shtelma, Lead Specialist Solutions Architect at DATABRICKS
- Alex Ott, Senior Specialist Solutions Architect at DATABRICK
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
