ARTICLES
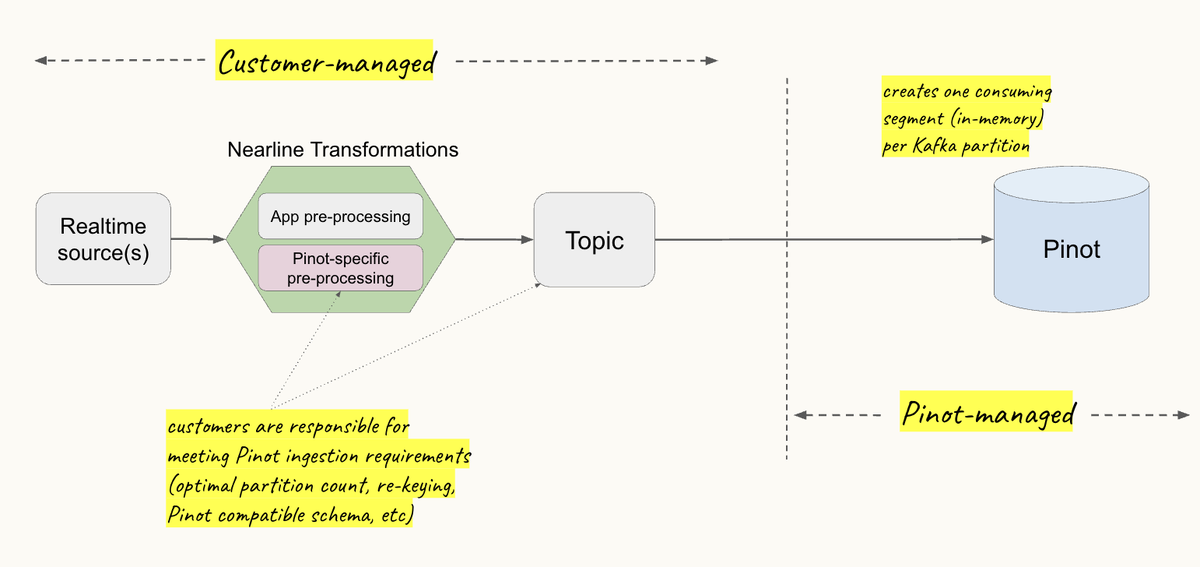
Powering Apache Pinot ingestion with Hoptimator | 6 min | Stream Processing | Ryanne Dolan, Gerardo Viedma | Linkedin Engineering Blog
How LinkedIn uses Hoptimator to automate end-to-end data pipelines for Apache Pinot—shifting from producer-driven to fully managed, AI-aware ingestion.
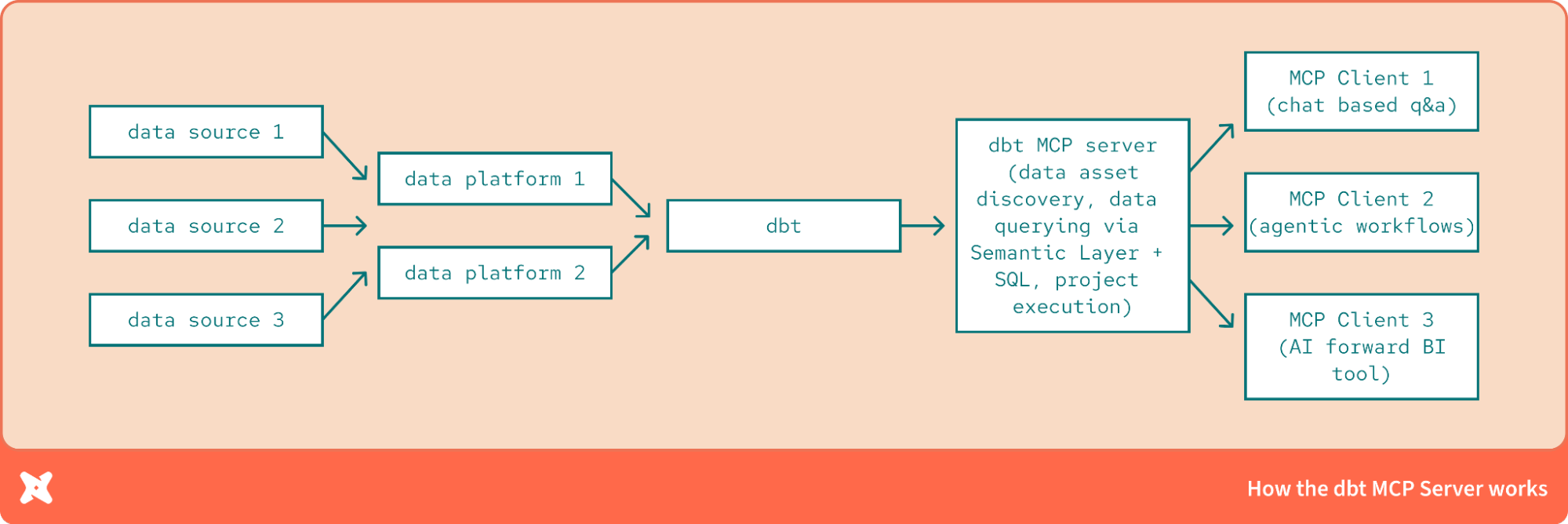
Introducing the dbt MCP Server – Bringing Structured Data to AI Workflows and Agents | 16 min | AI | Jason Ganz | dbt Blog
Meet dbt’s experimental MCP Server, bridging structured data and LLMs by exposing dbt models, metrics, and lineage through the Model Context Protocol.
TUTORIALS
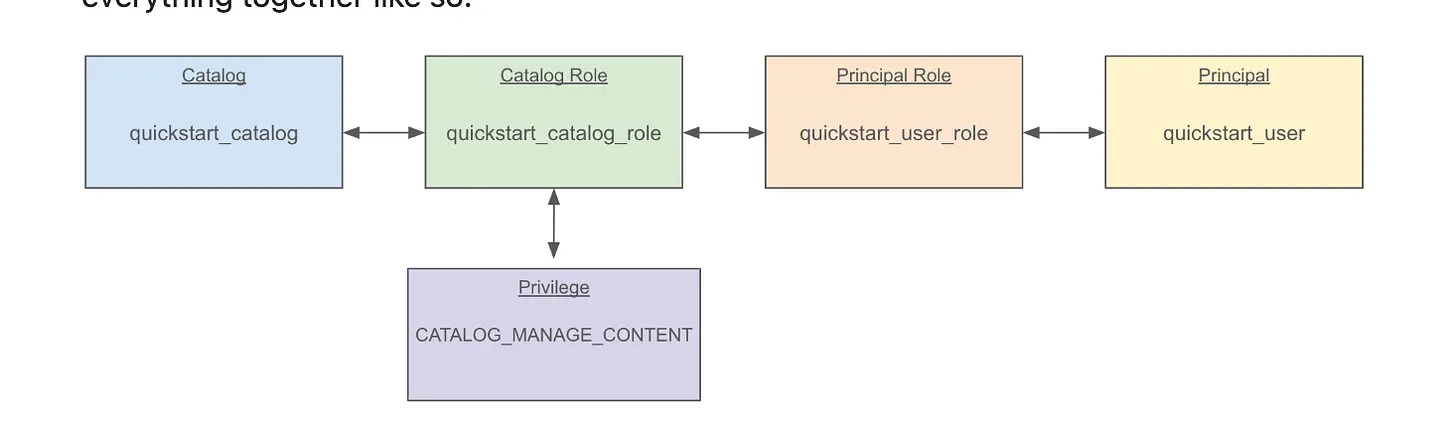
How I (Barely) Survived Setting Up Polaris As An Iceberg Rest Catalog | 4 min | Data Engineering | Daniel Beach | Personal Blog
A raw, honest take on setting up Polaris as an Iceberg REST catalog in production. Spoiler: it hurt, but it worked.
How I Cut Docker Image Size by Switching to a Distroless Base Image | 5 min | DevOps | Dorian Grasset | Personal Blog
By switching to a distroless base image and adopting best practices, Dorian cut image size from 380 MB to 60 MB—boosting security and performance.
Building an End-to-End Data Lake ELT Pipeline using Modern Data Stack | 4 min | Data Engineering | Haq Nawaz | Dev Genius Blog
A practical walkthrough of building a data lake pipeline using MinIO, Trino, Iceberg, dbt, and Airflow—end-to-end and production-ready.
TOOLS
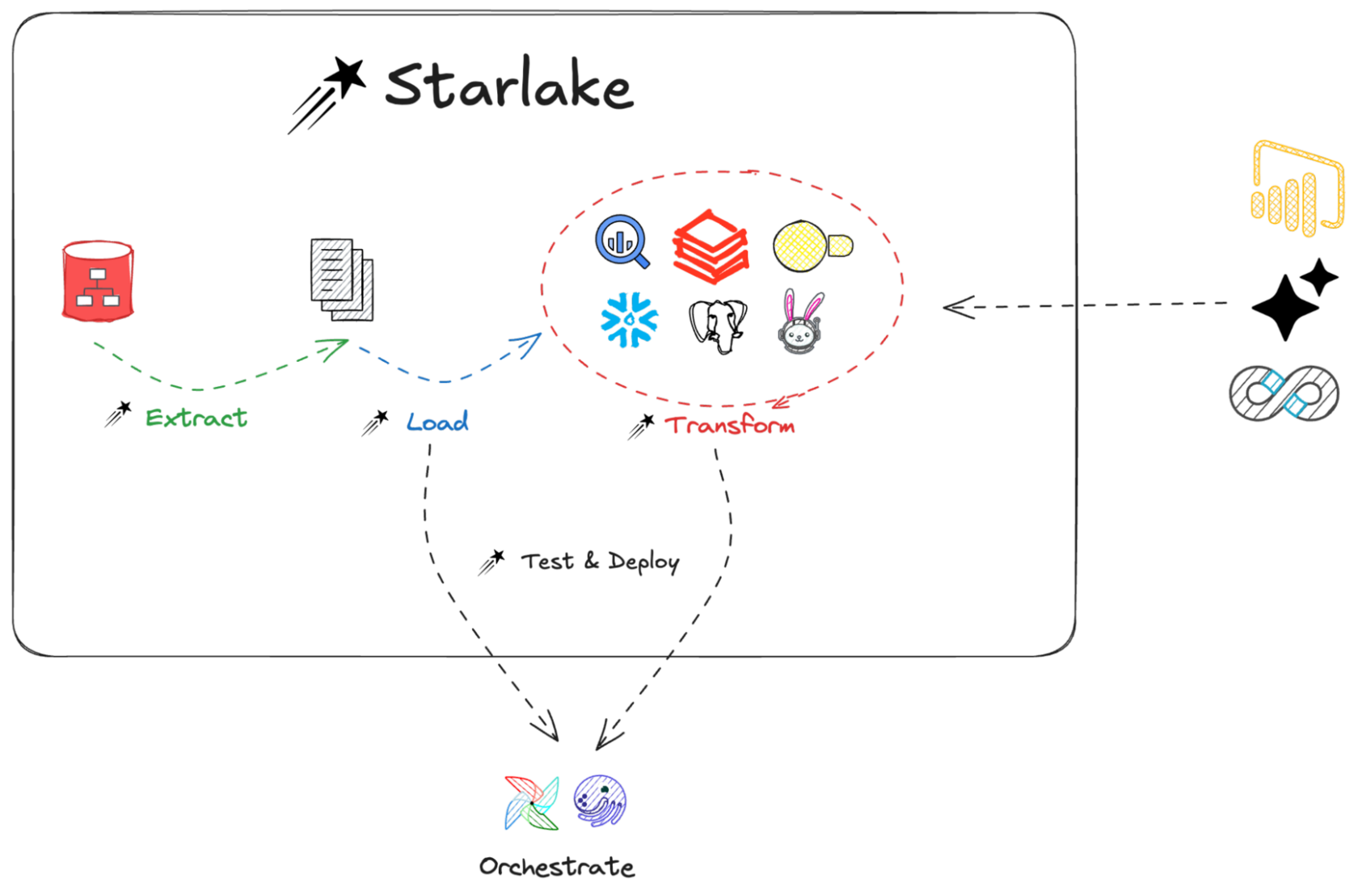
Starlake: Open Source Data Integration & ETL Platform | 4 min | Data Engineering | Starlake Blog
Starlake lets you define extract, load, transform, and test tasks in YAML, and auto-generates DAGs—like Terraform for your data pipelines.
PyCharm| 3 min | Data Engineering | Valerie Andrianova | jetbrains Blog
PyCharm merges Community and Pro editions into a single product with a free Pro trial and built-in Jupyter support for all.
DATA TUBE
Unapologetically Technical Jacopo Tagliabue - Bauplan Ep.19 | LLM | 1 h 58 min | Jesse Anderson, Jacopo Tagliabue | Personal Channel
From NLP research to building Bauplan, Jacopo dives deep into AI architectures, startup realities, and the evolution of “Git for Data.”
CONFS, EVENTS AND MEETUPS
From Zero to Databricks in 8 Weeks — Live Webinar | May 13th 4 PM CET
Join for a behind-the-scenes webinar organized by Xebia, Databricks, and Red Flag Alert. During the session, we’ll share the journey of platform design, full production deployment, and workload migration — all completed in just 8 weeks.
Infoshare 2025 | Gdańsk | May 27th-28th
DATA Pill is partnering with Infoshare 2025, taking place on May 27-28 in Gdańsk, Poland. As the country’s largest technology conference, Infoshare brings together business and technology leaders to explore the latest trends, tools, and insights across seven thematic stages: AI & Data, DevTrends, Architecture, Growth, Leaders, Marketing, and Inspire. Attendees can expect expert meetups, roundtable discussions, extensive networking opportunities, and side events including a Great Networking Party and a Sunset Leaders Boat Trip. Tickets are available now, and you can get 10% off with the discount code ISC25-DATAPill10.
PINNACLE PICKS
Your last week top picks:
Building a modern Data Warehouse from scratch | 15 min | Data Warehouse | Rihab Feki | Personal Blog
From architecture to analytics—follow this practical guide to designing a scalable, SQL Server-based data warehouse using the Medallion Architecture.
Making the Right Choice: Flink or Kafka Streams? | 9 min | Stream Processing | Juliusz Nadbereżny | GetInData | Part of Xebia Blog
A hands-on comparison of Flink and Kafka Streams, breaking down time handling, state, deployment, and scalability. Flink comes out on top for flexibility and long-term reliability.
How I use LLMs | LLM | 2 h 11 min | Andrej Karpathy | Personal Channel
A practical, example-rich walkthrough of how LLMs are applied in daily workflows—perfect for both enthusiasts and builders.
________________________
Have any interesting content to share in the DATA Pill newsletter?