
ARTICLES
LLMs in Data Analytics: An Arbitrage Opportunity | 8 min | Data Analytics | Frank Corrigan | Personal Blog
Read about the transformative potential of LLMs through a case study on holiday movie trends, interactive data visualizations, SQL analysis, and the current arbitrage opportunities in data analytics.
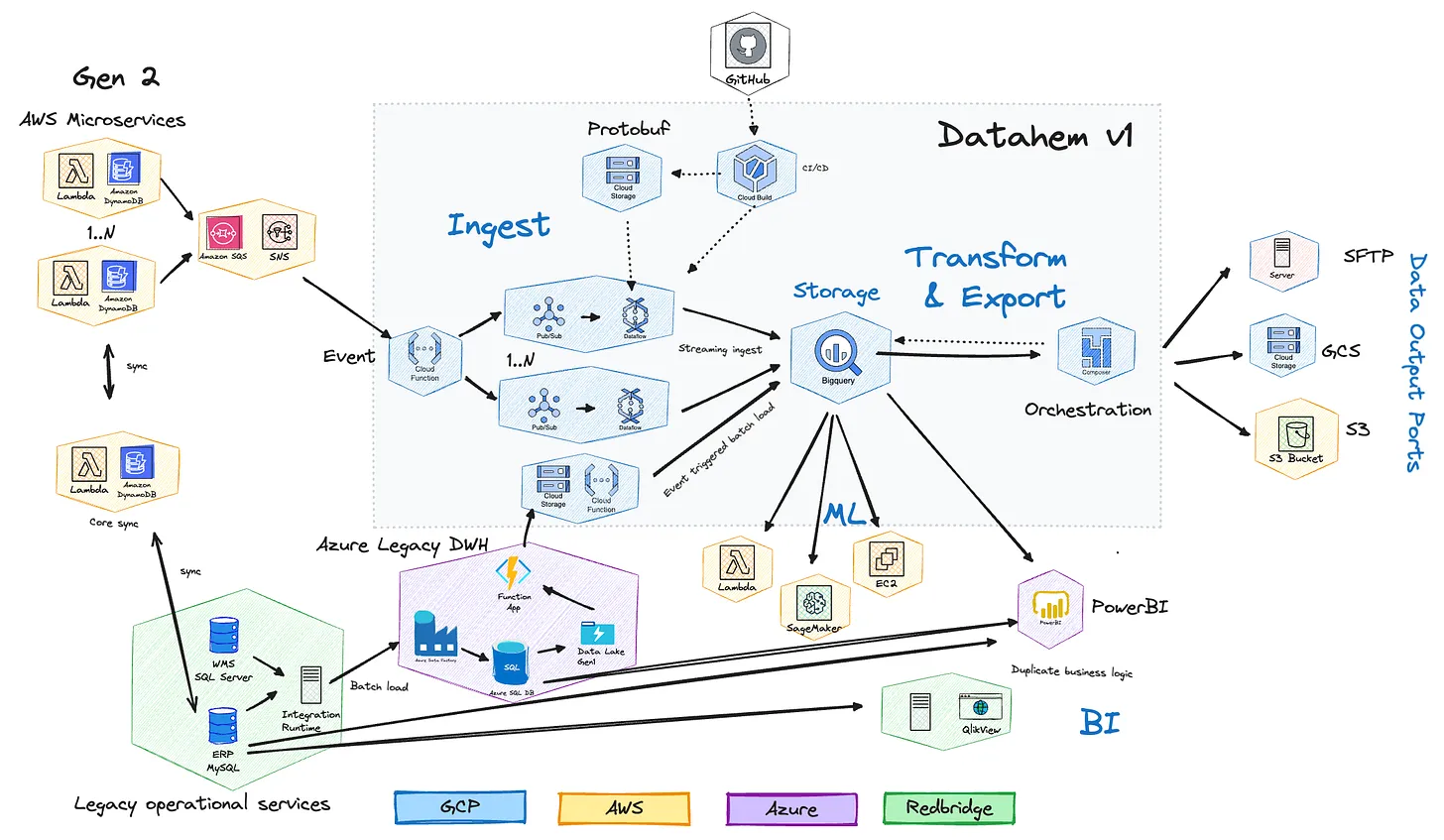
DataHem odyssey - the evolution of a data platform, part 1 | 7 min | Data Platform | Robert Sahlin | Personal Blog
It is a story with 4 chapters that illustrates the journey from an entrepreneurial startup with a “one-man data team” to a scale-up with a data platform team.
This post covers:
- 2018: Batch BI
- 2019-2021: Streaming ingest & data activation
NLP vs GAI: The Battle Explored !!! | 6 min | Data Engineering | Martin Jurado Pedroza | Personal Blog
The text digs into the ever-evolving world of artificial intelligence, honing in on NLP and GAI, collectively known as Textual AI. It breaks down their definitions, goals, and applications, showing how NLP lays the groundwork for GAI's creative side.
Generating your shopping list with AI: recommendations at Picnic | 10 min | AI | Thijs Sluijter | Picnic Blog
Essential skills, from programming and containerization to Kubernetes, and exploring MLOps components like version control, CI/CD pipelines, orchestration and feature stores.
NEWS
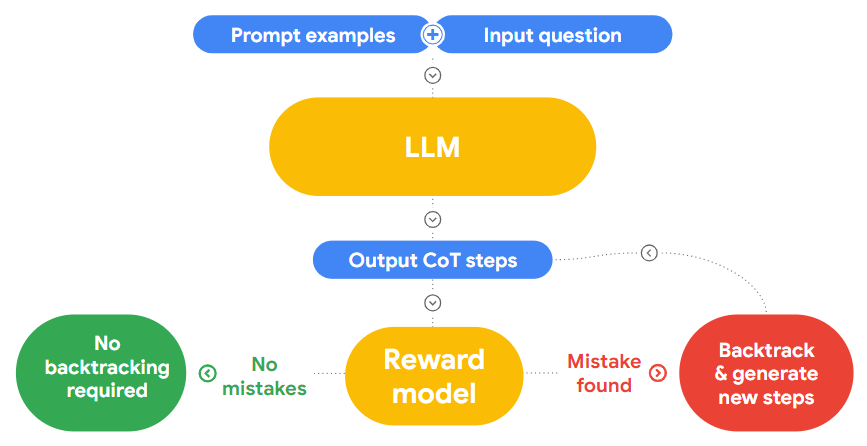
Can large language models identify and correct their mistakes? | 13 min | LLM | Gladys Tyen | Google Research Blog
"LLMs cannot find reasoning errors, but can correct them!" examines LLMs by breaking down self-correction into mistake finding and output correction. Using the BIG-Bench Mistake dataset, it explores the LLMs' ability to identify logical mistakes, the utility of mistake-finding as a correctness proxy, and the generalizability of mistake-finding skills to unseen tasks.
TUTORIALS
Large Language Models and Vector Databases for News Recommendations | 8 min | LLM | João Felipe Guedes | Towards Data Science
In this one, João introduces two open-source solutions, Sentence Transformers, and Qdrant, aiming to address key questions about generating, storing, and querying these representations, illustrated through their application to the NPR News Portal Recommendation dataset.
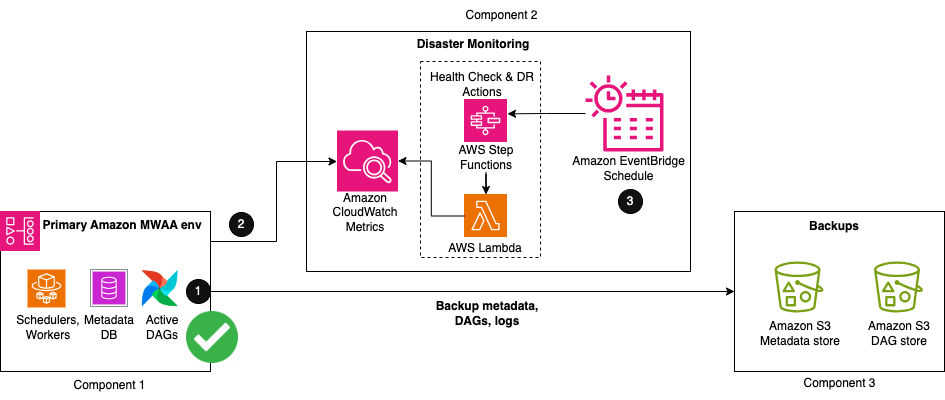
Disaster recovery strategies for Amazon MWAA – Part 1 | 7 min | Cloud | Parnab Basak, Chandan Rupakheti, Vinod Jayendra, and Rupesh Tiwari | AWS Blog
This one explores disaster recovery for Amazon MWAA, offering solutions to protect against disruptions and integrate risk management into your business continuity plan. This post focuses on designing the DR architecture, with a future installment covering implementing components using AWS services.
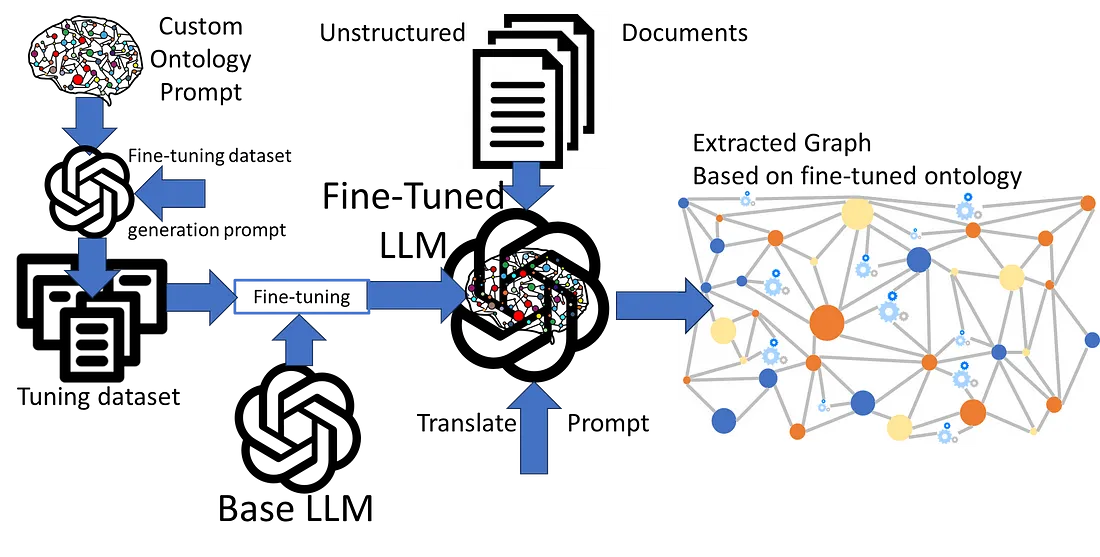
Text-to-Graph via LLM: pre-training, prompting, or tuning? | 20 min | LLM | Peter Lawrence | Personal Blog
This tutorial explores the use of LLMs in converting unstructured text into Knowledge Graphs, focusing on four methods that adhere to specific ontologies. It enhances data analysis and query formulation by structuring vast unstructured data efficiently.
TOOLS
Top-5 Python Frontend Libraries for Data Science | 7 min | Artem Shelamanov | Python in Plain English
This article delves into five distinct frontend libraries, each offering unique features and trade-offs. It guides through the strengths and drawbacks of Streamlit, Solara, Trame, ReactPy, and PyQt, providing a comprehensive overview to aid in selecting the ideal framework for specific projects.
PySyft | Federated Learning
Syft is OpenMined's open source stack that provides secure and private Data Science in Python. Syft decouples private data from model training, using techniques like Federated Learning, Differential Privacy, and Encrypted Computation.
DATA TUBE
CI/CD for Modern Data Engineering | 1 h 10 min | Data Engineering | Yusuf Ganiyu | CodeWithYu
Delve deep into the world of DevOps, focusing on Continuous Integration (CI) and Continuous Deployment (CD) within the realm of modern data engineering.
You’ll find:
- Azure Infrastructure as Code Automation with Terraform
- Storage account module with Terraform
- Automating Azure Data Factory with Terraform
- Testing and Validation of Results
PODCAST
AI Unleashed: 3 Indispensable tips for harnessing AI in your LMS system | 22 min | AI | Giovanni Lanzani | Fit For The Future
Giovanni touches on valuable considerations for integrating AI into L&D systems, providing a practical guide for managers and the workforce. His journey from the early days of AI to the present underscores the transformative impact of information.
CONFS EVENTS AND MEETUPS
MOPS - Meetup #3 | On-site event | Warsaw | 24th January
The formula is similar to previous editions three, about 30-minute practical talks followed by question-and-answer sessions with networking afterward.
Presentations:
- Scalable, secure, and sustainable NatWest Group’s MLOps platform
- MLflow iceberg: from basics to hidden depths
- Building a vector search engine
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
