
ARTICLES
Top 5 Best Practices for Building Event-Driven Architectures Using Confluent and AWS Lambda | 8 min | Cloud | Ahmed Zamzam, Ashish Chhabria | Confluent Tech Blog
This blog post discusses using two different patterns—the Fully managed AWS Lambda Sink Connector and Native event source mapping (ESM)—to integrate Confluent with AWS Lambda to build event-driven applications (EDAs). It highlights the best practices developers and architects should know when making EDAs with Confluent and Lambda.
All You Need to Know about Vector Databases and How to Use Them to Augment Your LLM Apps| 24 min | LLM | Dominik Polzer | Towards Data Science Blog
Delve into this comprehensive guide's fundamental concepts and practical insights, providing valuable knowledge for data scientists, developers and anyone keen on enhancing LLM-powered applications with vector databases. Exploring the synergy between these domains opens up exciting opportunities in data processing and developing LLM applications.
Build Your Own Feature Store with Streaming Databases | 10 min | Machine Learning | Yingjun Wu | Data Engineer Things
This article touches on the importance of feature stores in machine learning and data management, tackling data consistency, feature reuse, transformation and versioning issues. It introduces feature stores as central repositories for machine learning features, especially highlighting real-time access.
TUTORIALS
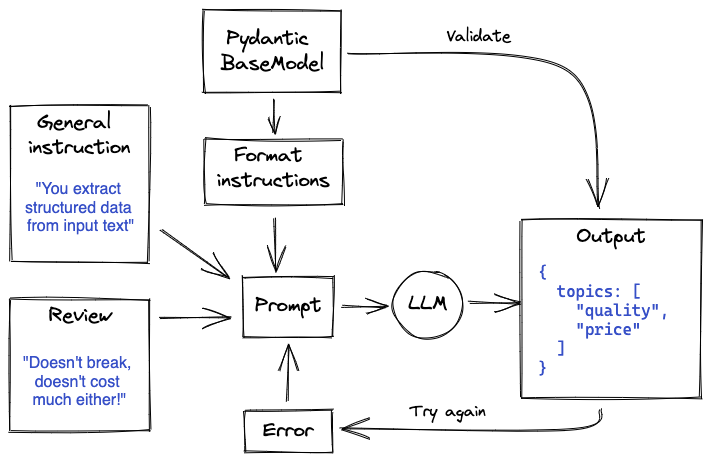
How to Extract Structured Data from Unstructured Text using LLMs | 6 min | LLM | Yke Rusticus | Xebia Tech Blog
This tutorial explores a typical application of Large Language Models (LLMs), which involves extracting structured data from unstructured text. The primary illustration centers on customer feedback analysis, demonstrating how an LLM, when coupled with an effective prompting strategy, enables the transformation of unstructured textual data into organized information. The resulting structured data has the potential to enhance databases and contribute to more informed decision-making processes.
Scrape & Analyze Football Data with Kestra, Malloy and DuckDB | 7 min | Data Engineering | Benoit Pimpaud | Personal Blog
This tutorial shows how using the last data tool, kids in the block, helps to fetch football data, perform powerful yet simple queries and seamlessly manage the entire process.
Create AWS Glue federated datasets | 4 min | Cloud | Google Cloud Blog
This document describes how to create a federated dataset in BigQuery that's linked to an existing database in AWS Glue.
NEWS
Introducing MLflow 2.7 with new LLMOps capabilities | 3 min | LLMOps | Corey Zumar, Kasey Uhlenhuth, Ridhima Gupta | Databricks Blog
MLflow 2.7 introduces interactive prompt engineering to evaluate LLM project viability. Users can experiment with models, parameters and prompts. MLflow automates experiment tracking, aiding in dataset creation and model selection. It also enhances governance and security through AI Gateway routes, enabling the exploration of proprietary and open-source LLMs.
Introducing Apache Spark™ 3.5 | 7 min | Data Engineering | Yuanjian Li, Daniel Tenedorio, Martin Grund, Allan Folting, Hyukjin Kwon, Herman van Hövell, Wenchen Fan, Weichen Xu, Gengliang Wang, Allison Wang, Jungtaek Lim, Xiao Li, Reynold Xin | Databricks Blog
Databricks announced Apache Spark™ 3.5's availability in Databricks Runtime 14.0, focusing on accessibility and efficiency. The update includes enhanced Spark Connect, improved PySpark and SQL functionality, DeepSpeed support for distributed training and enhanced stability in state store providers. Notably, the English SDK for Apache Spark makes data transformations more user-friendly.
TOOLS
Streamlit in Snowflake | Cloud
Streamlit in Snowflake helps developers securely build, deploy and share Streamlit apps on Snowflake’s data cloud. Using Streamlit in Snowflake, you can build applications that process and use data in Snowflake, without moving data or application code to an external system.
Harlequin | SQL
Harlequin is a drop-in replacement for the DuckDB CLI that brings the SQL IDE features to your terminal. It’s written in Python, using the Textual framework.
PODCASTS
Ensuring LLM Safety for Production Applications | 45 min | LLM | host: Sam Charrington; guest: Shreya Rajpal | TWIML Podcast
This podcast delves into ensuring safety and reliability in language models for production applications, addressing risks like hallucinations and LLM failure modes. It also examines the susceptibility of the widely-used RAG technique to closed-domain hallucination and the importance of robust evaluation metrics, tooling and the Guardrails project for enhancing model integrity and effectiveness.
CONFS EVENTS AND MEETUPS
Data Mass | Gdańsk | 5th October 2023
This Summit is aimed at people who use the cloud daily to solve Data Engineering, Big Data, Data Science, Machine Learning and AI problems.
What can you expect to find there? Find out in the articles below:
- Unlock the power of MLOps by Nike, Free NOW, and GetInData
- Unlock the power of MLOps by Nike, Free NOW, and GetInData
- Unlock the power of MLOps by Nike, Free NOW, and GetInData
- Data Platforms and Analytics at DNV, Volkswagen Group, Bolt
Psst… Use the DataPILL20 code to get a 20% discount!
Generative AI using open source LLM models | Webinar | 26th September 2023
This webinar will help you understand the basics of LLM models and their significance in AI. It will touch on the privacy and security concerns of using large language models in your organization.
You will get an overview of the technology landscape of open-source LLM models and their use cases. Finally, Michał will walk you through a use case involving summarizing financial data tables using open-source LLM models.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
