
ARTICLES
Best practices for LLM optimization for call and message compliance: prompt engineering, RAG, and fine-tuning | 25 min | LLM | Alec Coyle-Nicolas, Simon Greenman | Personal Blog
At Salus AI, the team optimized LLM performance for marketing calls in premium health screening services using prompt engineering, RAG, and fine-tuning techniques, improving accuracy from 80% to 95-100%. This blog shares their insights and findings, showcasing how LLMs can surpass traditional rule-based compliance monitoring solutions.

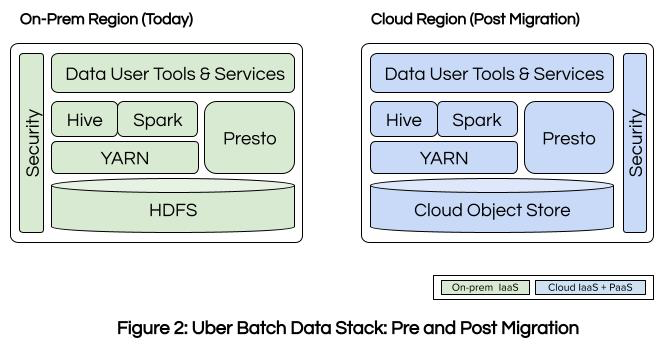
Modernizing Uber’s Batch Data Infrastructure with Google Cloud Platform | 5 min | Data Engineering | Abhi Khune, Arun Mahadeva Iyer, Matt Mathew, Sahana Bhat | Uber Engineering Blog
With one of the world's largest Hadoop installations, Uber is modernizing its extensive data infrastructure by migrating its batch data analytics and machine learning stack to the Google Cloud Platform (GCP). This move aims to enhance productivity, engineering efficiency, and cost-effectiveness. The blog outlines Uber's strategy for leveraging GCP's cloud storage, ensuring user transparency, and improving data governance.
Decodable vs. Amazon MSF: Running Your First Apache Flink Job | 5 min | Data Engineering | Gunnar Morling | decodable Blog
Data engineers frequently ask how Decodable's Apache Flink-based ETL service compares to Amazon's Managed Service for Apache Flink (MSF). This post highlights the key differences and similarities to help you choose the best fit, especially if you're moving from a self-managed Flink cluster to a managed service.

TUTORIALS
Uncover social media insights in real time using Amazon Managed Service for Apache Flink and Amazon Bedrock | 7 min | Real-time analytics | Francisco Morillo, Subham Rakshit, Sergio Garcés Vitale | AWS blog
This post combines real-time analytics with generative AI to analyze tweets using Amazon Flink, Bedrock's Titan Embeddings, and OpenSearch Service. Users query via a Streamlit frontend, with a Lambda function retrieving tweets and generating insights using Anthropic Claude LLM. This solution enables real-time trend identification, sentiment analysis, and targeted customer segmentation.

Flink SQL - changelog and races | 14 min | Stream Processing | Maciej Maciejko | GetInData | Part of Xebia Blog
This blog post explores race conditions and changelogs in Flink SQL, highlighting potential pitfalls and solutions for ensuring data consistency and reliability. We'll cover changelogs' mechanics, race conditions' impact, and practical mitigation strategies, helping you maximize Flink SQL's potential in streaming applications.

Building and scaling Notion’s data lake | 12 min | AI | XZ Tie, Nathan Louie, Thomas Chow, Darin Im, Abhishek Modi, Wendy Jiao | Notion Tech Blog
Over the past three years, Notion scaled its data infrastructure to handle a 10x growth in data by transitioning from a single Postgres instance to a complex sharded architecture and building an in-house data lake. This strategic move improved data management, reduced costs, and enabled the development of new AI features.

PODCAST
How Microsoft Scales Testing and Safety for Generative AI | 57 min | AI | Sarah Bird, Sam Charrington | TWIML Podcast
Listen to a talk with Sarah Bird, Microsoft's chief product officer of responsible AI, about the testing and evaluation techniques used for the safe deployment of generative AI and large language models. Sarah shares insights on the unique risks, challenges, defense strategies, and lessons learned from the 'Tay' and 'Bing Chat' incidents.
DATA TUBE
Orchestrate generative AI with Workflows | 27 min | AI | Google Cloud Tech
Workflows is a versatile service for automating microservices, business processes, and ML pipelines, including generative AI calls. Explore how Workflows can orchestrate AI calls to Vertex AI, with a demo on creating a map-reduce style workflow for summarizing large texts.
Achieving near zero down time deployments for fraud detection applications with Mastercard | 24 min | ML | AWS Events
Mastercard's fraud detection service allows customers to configure transaction scoring rules through the Rules Management Platform. By leveraging AWS Managed Services, particularly CloudFront Blue-Green deployment, Mastercard has achieved zero downtime for its fraud detection system, eliminating maintenance-related outages.
CONFS EVENTS AND MEETUPS
Fine-tuning Open Source LLMs with Mistral | Online | 16th July
In this session, Andrea, a Computing Engineer at CERN, and Josep, a Data Scientist at the Catalan Tourist Board, will walk you through the steps needed to customize the open-source Mistral LLM. You'll learn about choosing a suitable LLM, getting training data, tokenization, evaluating model performance, and best practices for fine-tuning.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
