

ARTICLES
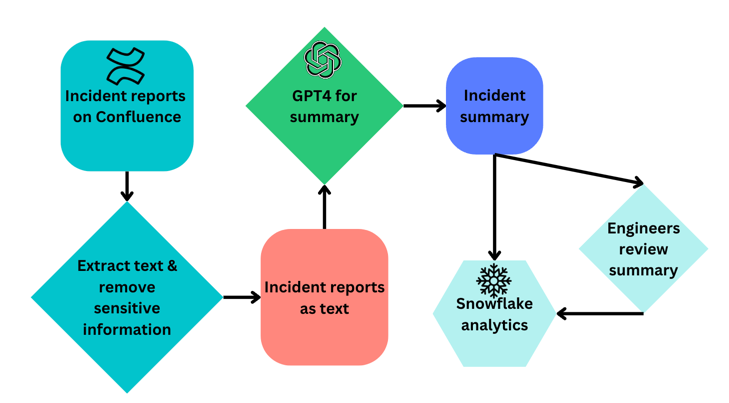
Summarizing Post Incident Reviews with GPT-4 | 7min | AI | Wuji Zhu | Canva Engineering Blog
Canva leverages GPT-4-chat to auto-generate Post Incident Report (PIR) summaries. By integrating GPT-4 into their workflow, Canva ensures consistent, blameless and high-quality summaries, significantly reducing the workload of their engineers and enhancing operational efficiency in incident tracking and analysis.
The Query Strikes Again | 14 min | Data Analytics | Emad Mokhtar, Eduardo Ortega, Kevin Van | Slack Engineering Blog
On October 12, 2022, the EMEA sector of Slack's Datastores team, overseeing database clusters, encountered a critical issue during an onsite day in Amsterdam. A surge in failed database queries prompted immediate action, identifying a long-running job and causing strain on the database cluster. This post delves into the root causes, the team's response, and subsequent preventive measures implemented to avert similar incidents.
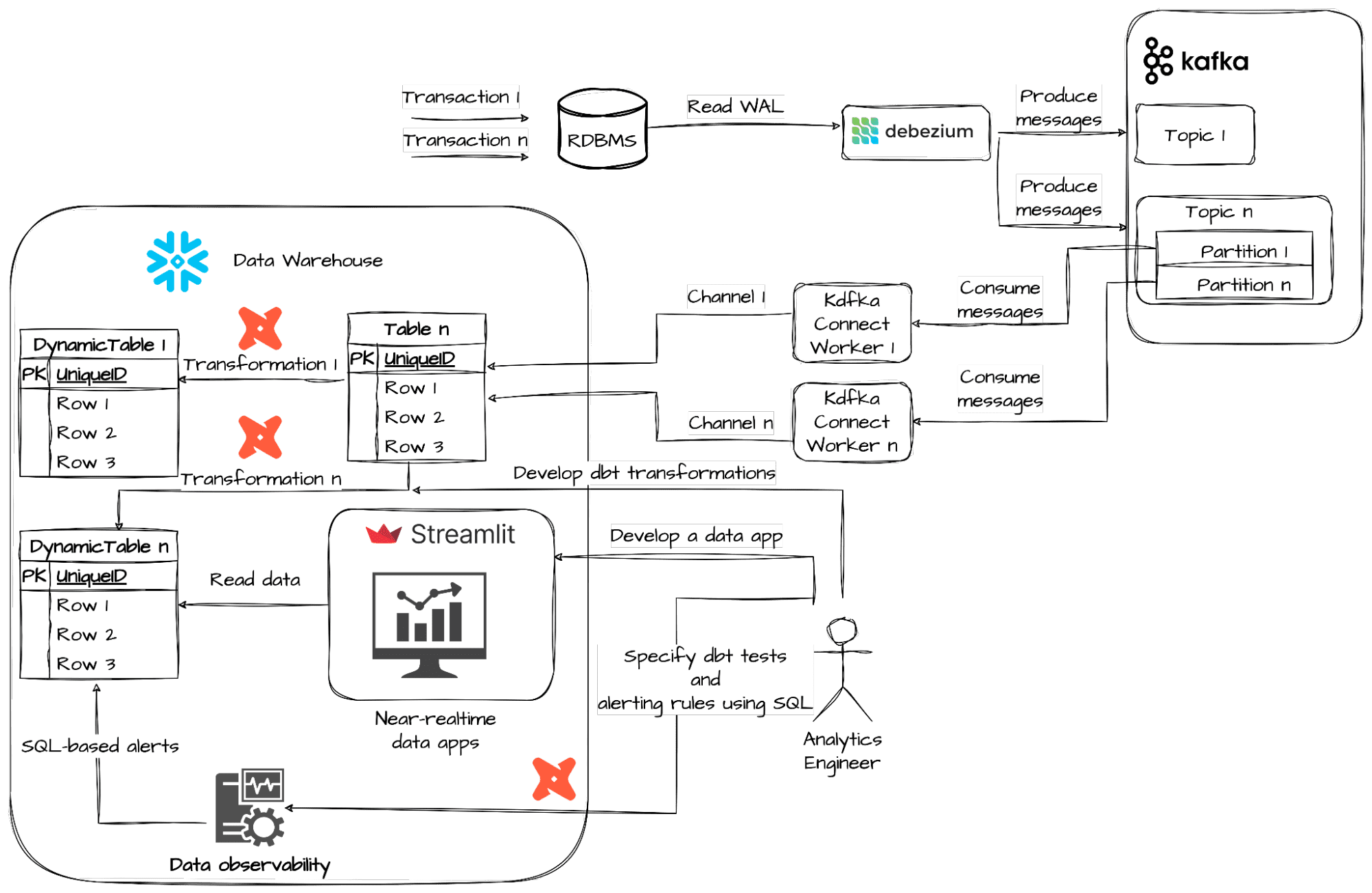
Nailing e-commerce: Black Friday's data in near real-time analytics with Snowflake Dynamic Tables & Snowflake Alerts | Michał Rudko, Marek Wiewiórka | GetInData | Part of Xebia Blog
This blog post will show you how to use two novel Snowflake features: Snowflake Dynamic Tables and Snowflake Alerts together with dbt for near real-time analytics and data observability. You will also find out how much it will cost you.
How We Export Billion-Scale Graphs on Transactional Graph Databases | 14 min | AI | Hongjiang Zhang, Jun Li, Hieu Nguyen and Flora Zhang | Ebay Engineering Blog
The text dives into the hurdles that eBay's GraphDatabase, NuGraph, faces in handling data quality and analyzing relationships. The suggested solution taps into Disaster Recovery for backend storage, introducing a NuGraph analytics plugin leveraging JanusGraph—an open-source graph database.
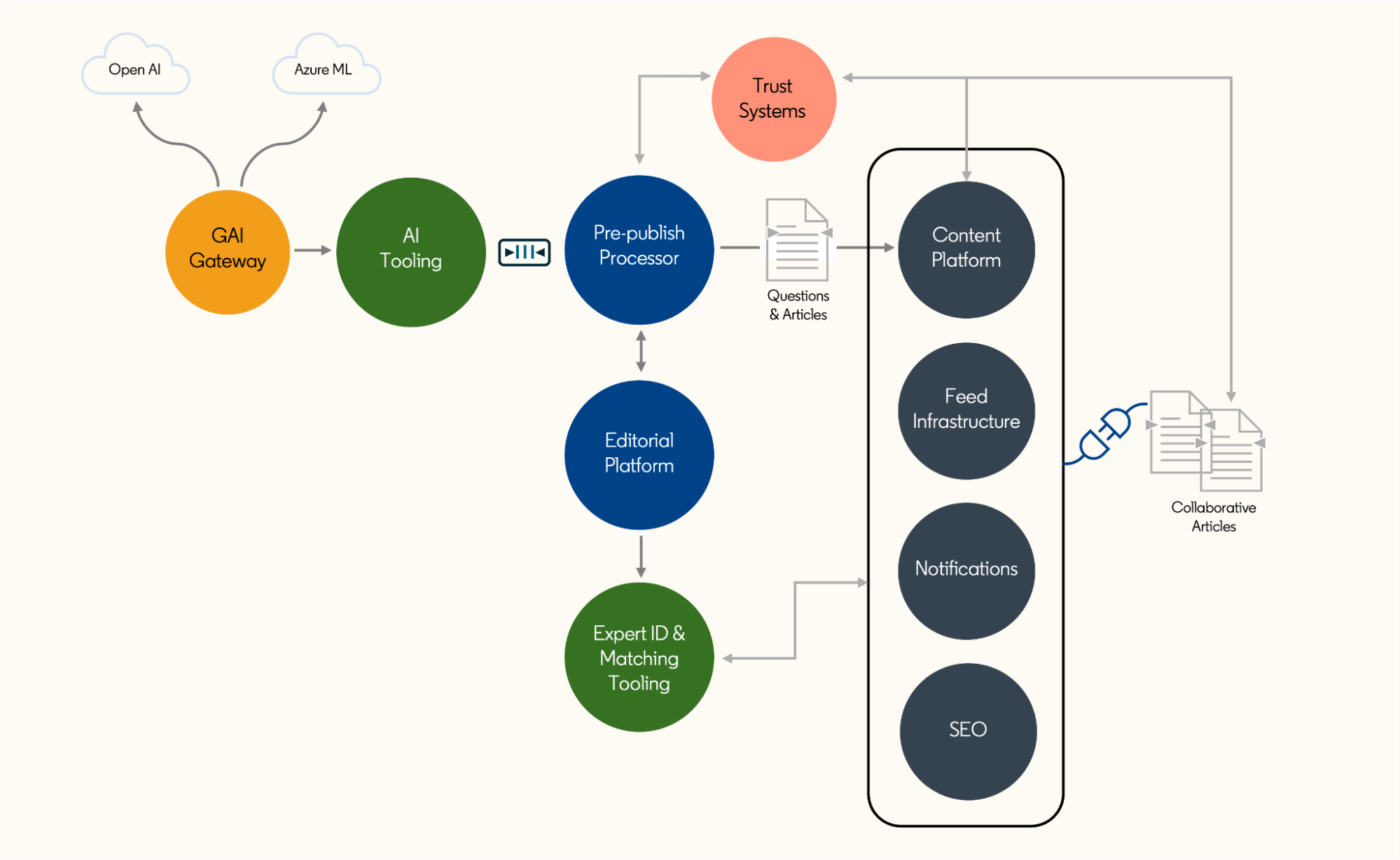
How LinkedIn Built the Engineering Infrastructure to Ignite Professional Knowledge Sharing | 8 min | AI | Shweta Patira, Ankan Saha, Yilin Li, Manas Somaiya | Linkedin Engineering Blog
Read a story on LinkedIn's development and the challenges faced in creating Collaborative Articles on LinkedIn. This platform provides real-life advice from seasoned experts to address various work-related questions. The article details the fast-paced process of building this Generative AI product, covering aspects such as prompt engineering, prototyping with code, connecting experts with relevant articles and ensuring trust and safety through robust content filtering.
Effective strategies to closing the data-value gap | 5 min | Data Analytics | Firat Tekiner, Justyna Bak | Google Cloud Blog
This text discusses the challenges organizations face in bridging the gap between data and value in the rapidly evolving landscape of big data and cloud technology. The Modern Data Strategy paper proposes strategies to address this gap, focusing on three key areas:
- Optimizing data experiences for all users
- Capitalizing on the value of data through a data economy approach
- Fostering innovation with a modern data ecosystem
TUTORIALS
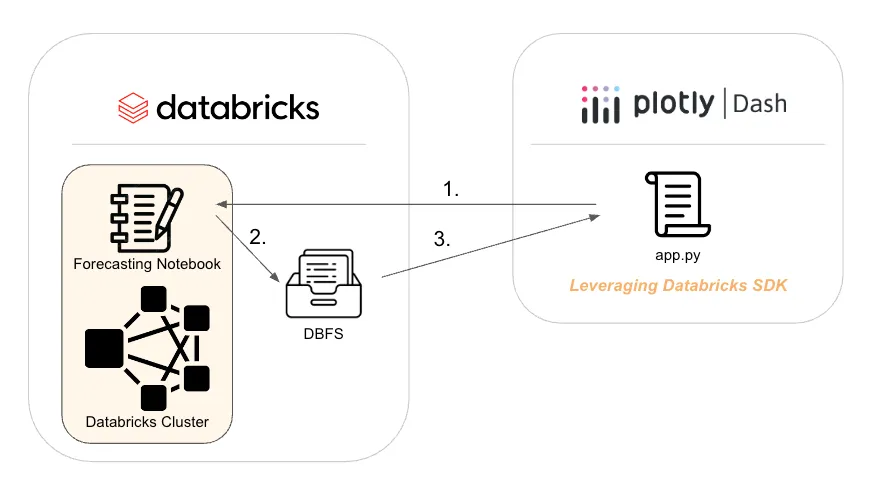
Databricks SDK + Plotly Dash — the easiest way to get Jobs done | 8 min | Data Streaming | Cal Reynolds, Cody Austin Davis, Sachin Seth, Dave Gibbon | Plotly Blog
This one shows the effective integration of Plotly Dash and Databricks, emphasizing their synergy as a powerful combination. Dive into a demo showcasing the seamless use of Databricks SDK and Jobs API within a Plotly Dash app for running a machine learning workflow.
Read and write streaming Avro data | 7 min | Data Streaming | Databricks Blog
Learn more about integrating Apache Avro, a data serialization system in the streaming domain, with Apache Kafka and Confluent Schema Registry. The documentation shows how Databricks facilitates the creation of efficient streaming pipelines using the from_avro and to_avro functions, allowing the encoding and decoding of Avro data and smooth transformations between columns with different data types.
DATA LIBRARY
Probabilistic demand forecasting with graph neural networks | Takes time to read | Machine Learning | Nikita Kozodoi, Liza Zinovyeva, Simon Valentin, João Pereira, Rodrigo Agundez | Amazon Science
This paper addresses the challenge of improving demand forecasting in retail by integrating Graph Neural Networks into a DeepAR model. The authors propose a novel approach that builds graphs based on article attribute similarity, developing the modeling of relationships between articles without relying on a pre-defined graph structure.
TOOLS
Titan | Data Engineering
Titan is a Python library to manage data warehouse infrastructure.
Titan is made up of many parts:
- Titan Resource API. Manage resources with pure-Python backed by Pydantic data models.
- Titan Blueprint. Define infrastructure with code.
- Titan Access Control [WIP]. Use ACLs to manage permissions and RBAC. Easily automate access control deployments.
LakeFS | Cloud
Manage your data as code using Git-like operations and achieve reproducible, high-quality data pipelines. Available Open Source or on the Cloud. Enjoy all the benefits of a Git-like version control interface for your data lake, in a fully managed service.
DATA TUBE
Introducing the Hendrix ML Platform: an Evolution of Spotify’s ML Infrastructure | 49 min | Machine Learning | Divita Vohra, Mike Seid | InfoQ
Watch the presentation that discusses Spotify’s newly branded platform, and share insights gained from a five-year journey building ML infrastructure.
PODCAST
Data Management, Data Governance, Data Quality, Data Discovery and Observability. How could you and your organization get involved in this topic? | 22 min | Data Management | Michał Rudko | Radio DaTa
In the newest episode, Michał Rudko explained what you should know about modern data management and how you and your organization could get involved.
Topics that the podcast includes:
- What is data management? How does it relate to data governance, data observability, and other similar terms?
- Why do we care about Data Management?
- What does it take to introduce data management in the organization?
- How do we get from an AS-IS situation to a desired well-managed data environment?
Writing and linting Python at scale | 49 min | Data Engineering | Pascal Hartig, Amethyst Reese | Meta Tech Podcast
This episode discusses how Meta’s Python Foundation Team works to improve the developer experience of everyone working with Python at Meta; Fixit 2, Meta’s recently open-sourced linter framework; and what exactly the role of the production engineer at Meta entails.
CONFS EVENTS AND MEETUPS
How to talk to your DATA with (or without) LLM | Webinar | 30th November
This webinar will give you a brief understanding of the essential challenges to measuring, managing and discussing business problems across the organization layers and the key to overcoming them.
What we will discuss:
- Challenges in independently accessing data analysis by decision-makers
- What is a data model? And why it matters
- Why the generation of SQL is not enough to achieve value from data
- Looker and data model management
Google Cloud Applied AI Summit | Webinar | 13th December 19:00 CET
Developers of all skill levels, you’re invited to a no-cost digital event filled with inspiring sessions and demos designed to help you push the envelope with generative AI.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
