
ARTICLES
Having your cake and eating it too: How Vizio built a next-generation data platform to enable BI reporting, real-time streaming, and AI/ML | 6 min | AI/ML | Parveen Jindal, Darren Liu, Alina Smirnova | Personal Blog
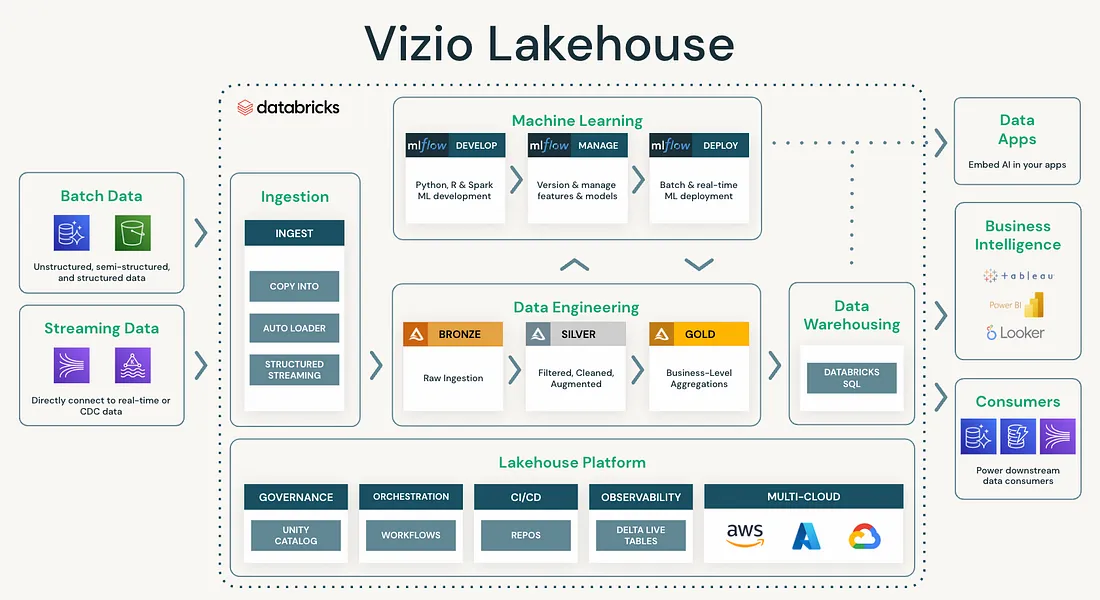
Vizio shares their success story of creative problem-solving by utilizing multiple data services and a data warehouse. When they needed to expand their capabilities, they developed a unified platform that consolidates different data platform use cases with linear scaling costs and full observability, setting them up for success with advanced analytics products.
Zero-ETL, ChatGPT, And The Future of Data Engineering | 9 min | Data Engineering | Barr Moses | Towards Data Science Blog
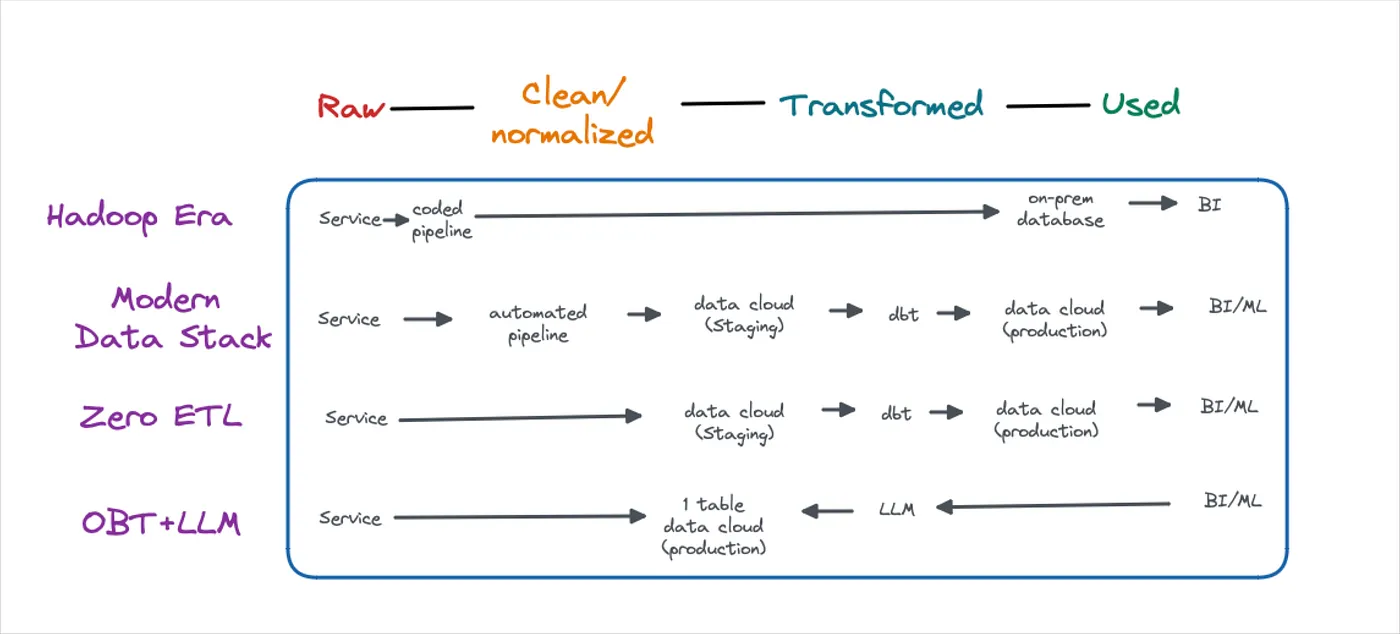
Let's explore the concept of Zero-ETL, which refers to the ability to directly access data from its source without implementing complex ETL (Extract, Transform, Load) processes. Barr outlines how this concept is being utilized in ChatGPT.
Read about predictions that the future of data engineering lies in breaking down data silos and directly accessing data from its source using tools such as Zero-ETL, thereby reducing the time, effort, and costs involved in traditional ETL processes.
Do not use Kubeflow! | 7 min | Machine Learning | Josue Luzardo Gebrim | Personal Blog
It is not rocket science that not all tools are for everyone. Josue explains why he doesn't like to work with Kubeflow and describes 8 great alternatives for those who have similar opinions about this tool.
Enabling large-scale, multi-cloud computing with Dagster | 6 min | Machine Learning | Fraser Marlow | Dagster.ai Blog
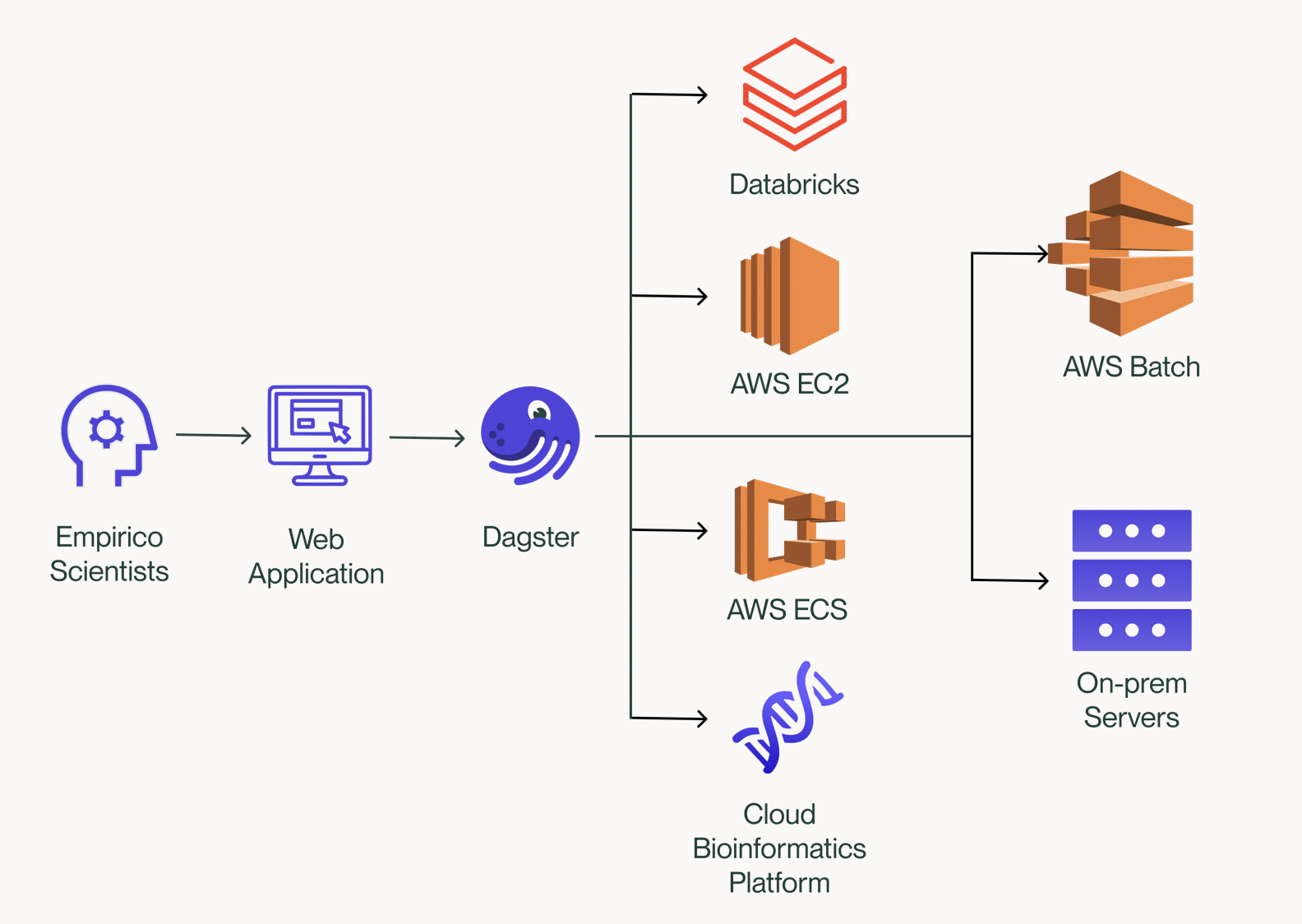
The Empirico team is working on building an innovative platform for automating machine learning experimentation. They are using Dagster to manage and orchestrate complex workflows. A case study where Fraser shares how they have been able to create a powerful platform capable of handling all stages of the machine learning experimentation process that also helped them dramatically reduce the number of bugs in their code, thanks to the tool's advanced testing and debugging features.
Google launches Non-Incremental Materialized Views For BigQuery | 2 min | Christian Lauer | Data Science | Towards Dev
How to save Money and improve Performance within BigQuery? Google has launched Non-incremental materialized views, which support most SQL queries. Christian explains a feature that is currently still in preview mode but can help you improve query performance and reduce cost.
DATA LIBRARY
DeeprETA: An ETA Post-processing System at Scale | 15 min | Data Engineering | Xinyu Hu, Tanmay Binaykiya, Eric Frank, Olcay Cirit | Uber Technologies
How Uber predicts rides ETA? Let’s meet DeeprETA, an accurate and fast travel time prediction system in production. Uber’s team evaluations demonstrate significant improvements over traditional machine learning models. Their findings will benefit researchers and practitioners in similar geospatial-temporal problems. While their hybrid approach is limited to Uber's proprietary routing engine, it is easily adaptable to other routing engines. Read how they continue to refine their model architecture, loss functions, and infrastructure for even greater accuracy improvements.
TUTORIAL
From Kafka to Delta Lake using Apache Spark Structured Streaming | 11 min | Data Streaming | Fabien Pomerol | Michelin Blog
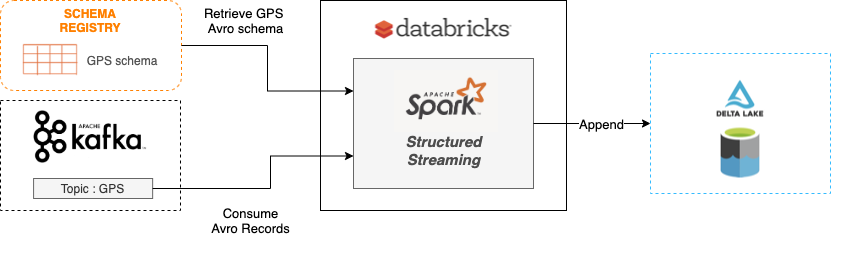
In this one, Fabien shows that configuring a stream consuming Kafka events and appending them in a Delta Lake table with Spark Structured Streaming is quite easy and does not require tons of code. Next, read how Michelin Team set up a pipeline based on a Spark Structured Stream consuming Avro events from an Apache Kafka topic and wrote them to a Delta Lake table.
TOOLS
Recapit | AI | Recapit
Will AI replace us? Don’t think so, but this one can help you save your time everyday. Recaplt works by using AI technology to summarize news articles from over 60,000 news providers, providing a personalized and easy-to-listen audio news update delivered to your phone every morning based on your selected interests. RecapIt gives you access to a variety of news sources, so you can stay informed with the latest news from around the world.
NEWS
Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM | 8 min | AI | Mike Conover, Matt Hayes, Ankit Mathur, Xiangrui Meng, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia and Reynold Xin | Databricks Blog
A story about how Databricks developed Free Dolly 1.0, a large language model (LLM) trained for less than $30 to exhibit ChatGPT-like human interactivity. Why did they create a new dataset, and how did they do it? Read their journey to create a commercially viable model now.
Joining forces with Xebia: The story by GetInData’s founders about their aspirations, dilemmas and key reasons for joining the global partner | 15 min | BizDev | Adam Kawa | GetInData | Part of Xebia Blog
It is time to delve into the journey of GetInData and the decision to partner with Xebia, a global technology consulting and services company. Adam explores the aspirations and dilemmas faced by founders as they navigated the path to global expansion and highlights the key reasons behind our strategic partnership with Xebia. He also shares insights into the unique synergies between GetInData and Xebia, including our shared commitment to innovation, customer-centric approach, and a strong focus on delivering tangible business outcomes through data-driven strategies.
PODCASTS
Serious Public Clouds Invest In Infrastructure With Charles Fitzgerald | 45 min | hosts: Ned Bellavance, Ethan Banks guest: Charles Fitzgerald | Day Two Cloud Podcast
In this episode of Day Two Cloud, you can explore the financial allocation of public clouds and examine what IT and engineering professionals can glean from these spending habits. Additionally, you will learn more about cloud repatriation and its prevalence. Charles Fitzgerald is an expert in Capital Expenditure and authors the Platformonomics blog. He also works as a consultant, strategist, and angel investor.
Discussed subjects:
- Why a public cloud’s CapEx matters
- How CapEx might indicate a particular strategy or direction
- Drawing conclusions from capital spending by the Big 3 Can smaller public clouds compete?
CONFS EVENTS AND MEETUPS
Enabling world changing applications with a modern data architecture | 19h April | 11:30am CET | Webinar
The realm of building and transporting applications is constantly evolving. The arrival of advanced technologies like Kubernetes and the cloud native ecosystem has immensely transformed infrastructure and applications. However, traditional systems lag in agility, calling for modernizing data technologies and methodologies. Failure to do so usually results in the inability to leverage the advantages of this technological revolution.
On the 19th of April, Cockroach Labs and Computacenter will host a comprehensive discussion on the difficulties encountered by contemporary data practices and the means of driving business value through data development.
PaperTalks #3 - The Forward-Forward Algorithm: Some Preliminary Investigations | 27h April | 3pm CET | online meeting
Join the next edition of live meeting with GetInData’s Advanced Analytics Team! Stay up-to-date with the newest achievements in the world of machine learning, and stay ahead with cutting-edge developments. Don’t miss out on this opportunity to level up your knowledge in data science!
If the Databrick story from the news section interests you, join their webinar to let know more about LLM.
Curious how your company can benefit from large language models (LLM) like ChatGPT? Imagine if you could train your own model — customized to your specific data to meet your specific needs.
You’ll learn:
- How to use off-the-shelf pretrained models with tools like Hugging Face and GPU resources
- How to fine-tune a model on your data
- How Dolly was built
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
