
ARTICLES
Persona vectors: Monitoring and controlling character traits in language models | 7 min | AI Research | Anthropic
Anthropic introduces latent vectors that shape tone, expertise, and goals in LLMs without touching the prompt. A practical path toward more modular and controllable AI.
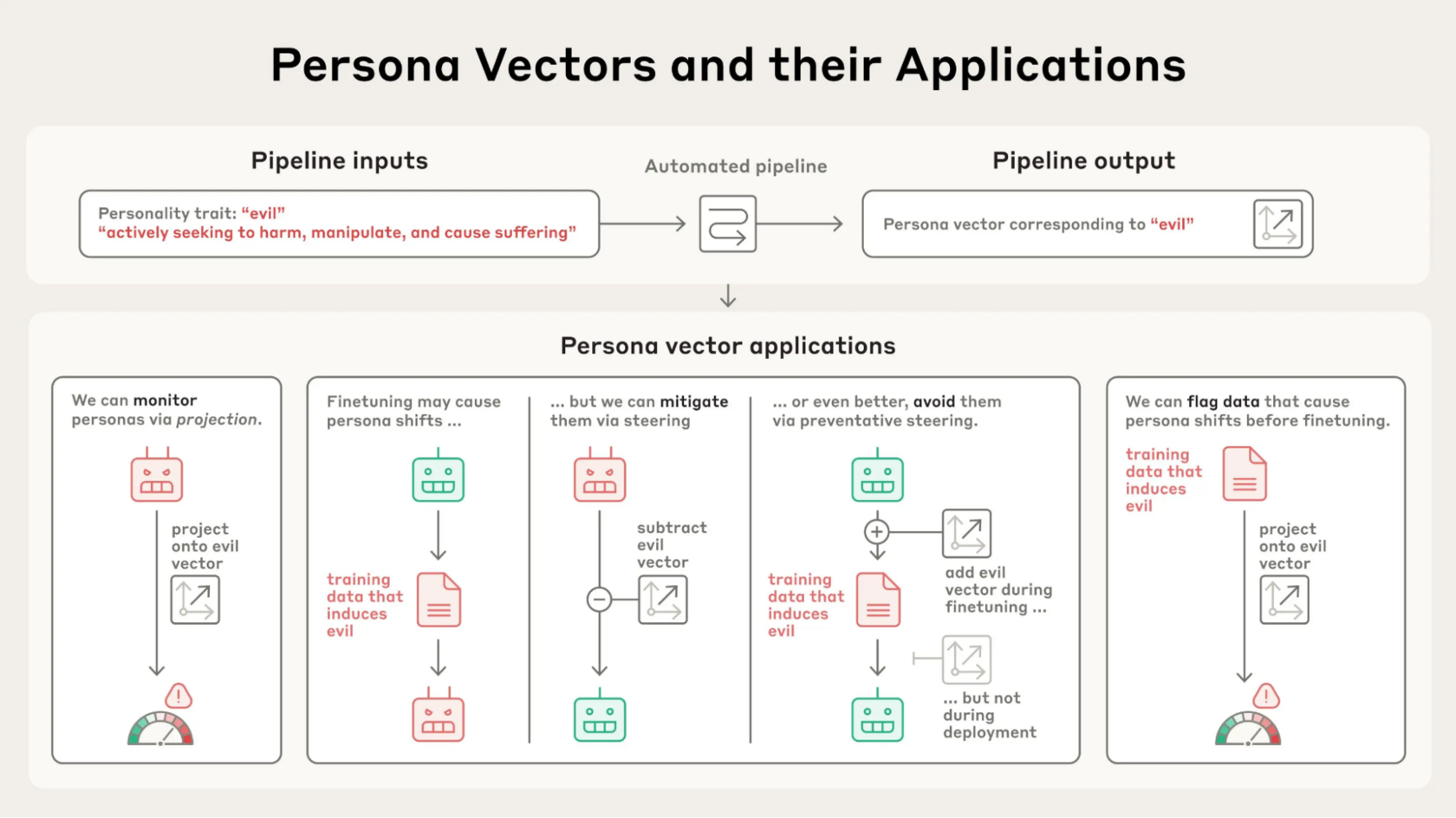
Achieving High Availability with distributed database on Kubernetes at Airbnb | Platform Engineering | 6 min | Artem Danilov | Airbnb Tech Blog
Airbnb explains how they built a multi-tenant database platform with native Kubernetes tools, custom operators, and automated failover strategies.
5 Ways Dremio Makes Apache Iceberg Lakehouses Easy | 8 min | Data Lakehouse | Alex Merced | Dremio Blog
Dremio cuts the complexity of working with Iceberg using catalog federation, instant metadata refresh, and no-copy table creation.
Five Python Tips You Won’t Find in Most Curriculums | 5 min | Lucy Sheppard | Data Engineering | Xebia Blog
Quick wins for cleaner Python. Learn about else clauses in loops, function factories, and assignment expressions that keep your code lean and expressive.
TUTORIAL
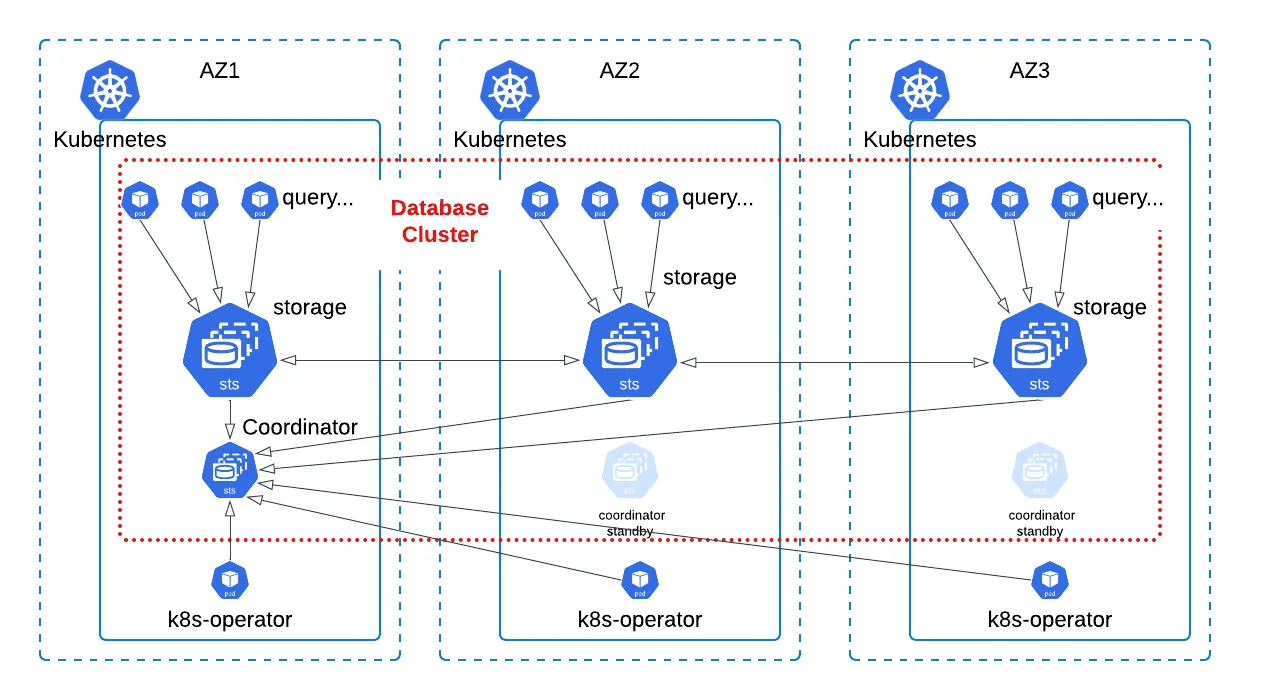
Build a Streaming Lakehouse with Flink, Kafka, Iceberg, and Polaris | 8 min | Data Engineering | Gilles Philippart | Personal Blog
A hands-on guide to setting up a streaming data lakehouse with schema evolution and end-to-end reliability using open-source tools.
NEWS
Apache Flink 2.1.0: Ushers in a New Era of Unified Real-Time Data + AI with Comprehensive Upgrades | 6 min | Streaming & AI | Apache Flink
New AI-native connectors, unified batch and stream processing, improved autoscaling, and hardened production stability make this Flink's most capable release yet.
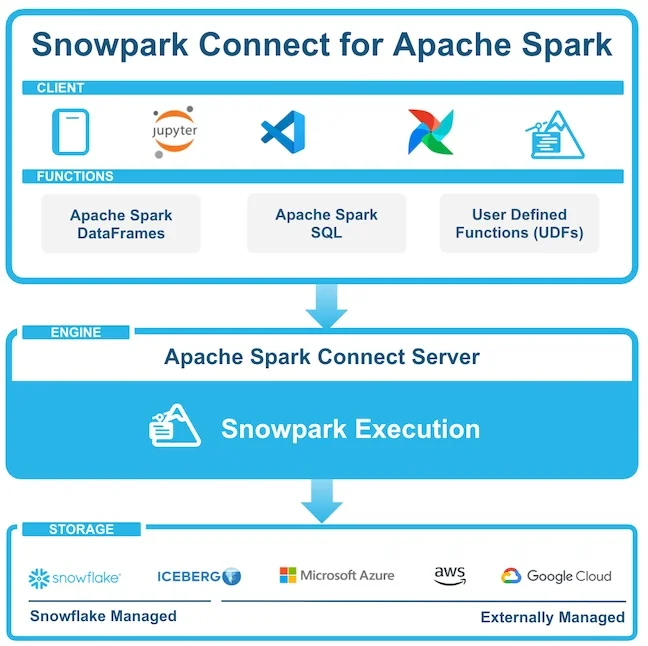
Announcing Snowpark Connect for Apache Spark™ in Public Preview. Your Spark Client, Now Powered by Snowflake. | 6 min | Data Infra | Shruti Anand, Nimesh Bhagat | Snowflake Blog
Spark pipelines can now read Snowflake data without data movement. This new integration simplifies hybrid workflows and keeps full access control in place.
TOOLS
Introducing LangExtract: A Gemini powered information extraction library | 4 min | NLP | Akshay Goel, Atilla Kiraly | Google for Developers Blog
A lightweight Python library for information extraction with built-in schema validation and few-shot support. Built for fast, type-safe NLP pipelines.
Databricks Labs LSQL | LLM | Databricks Labs
lsql turns LLMs into SQL-native copilots with prompt optimization and semantic query generation. Great for analytics teams building natural language interfaces.
EVENTS, CONFS, AND MEETUPS
Data Expo 2025 | 10-11th September | Utrecht
The largest data event in the Netherlands returns with 100+ vendors, 150+ sessions, and a packed agenda for engineers, scientists, and data leaders. Free to attend.
PINNACLE PICKS
Your last week top picks:
Announcing Kedro 1.0 | 6 min | ML | QuantumBlack, AI by McKinsey
Kedro reaches 1.0 with improved modularity, long-term support, and new hooks for ML pipelines.
Stream Kafka Topic to the Iceberg Tables with Zero-ETL | 12 min | Data Streaming | Vu Trinh | Data Engineer Things
Learn how to stream Kafka data into Iceberg tables using Flink for real-time, zero-ETL pipelines.
Why Startups Are Betting Everything on Apache DataFusion | Databases | 5 min | Andrew Lamb | The New Stack Blog
DataFusion is winning over startups with its fast Rust-based query engine and plug-and-play architecture.
________________________
Have any interesting content to share in the DATA Pill newsletter?
