ARTICLES
Data Ingestion — Part 1: Architectural Patterns | 11 min | Data Engineering | Jan Menkens | Personal Blog
In this two-part exploration of data ingestion, we'll dive deep into the intricacies of this crucial process that seamlessly connects the operational and analytical worlds. The first article will examine the Unified Data Repository, Data Virtualization, ETL, and ELT patterns, unraveling their unique advantages and limitations within the dynamic landscape of data analytics.
Data Quality Score: The next chapter of data quality at Airbnb | 9 min | Data Engineering | Clark Wright | Airbnb Tech Blog
In this blog post, the authors share Airbnb's innovative approach to scoring data quality - introducing the concept of Airbnb's Data Quality Score ("DQ Score"). Delve into the development of the DQ Score, its current applications and its role in shaping the future of data quality at Airbnb.
11 lessons learned managing a Data Platform team within a data mesh | 13 min | Data Platform | Souhaib Guitouni | BlaBlaCar Engineering Blog
In February 2022, BlaBlaCar's Data team embraced a Data Mesh model comprising of six domain-oriented squads and a transverse platform team of Data Engineers. This article explores the team's insights, showing the importance of versatile products, the collaboration with stakeholders, flexibility, and innovation based on real-world use cases in the evolving landscape of data management and deep learning technologies.
7 reasons to invest in real-time streaming analytics based on Apache Flink. The Flink Forward 2023 takeaways | 8 min | Data Streaming | Krzysztof Zarzycki | GetInData | Part of Xebia Blog
Fresh from the Flink Forward event in Seattle, dive into insights on the revolutionary Streaming Analytics Platform powered by Flink, Kafka, dbt, and more. Explore key takeaways - from the innovative Streamhouse concept to the dominance of Lakehouses and the empowering role of Flink SQL—reading about the dynamic future of real-time streaming analytics with Apache Flink.
TUTORIALS
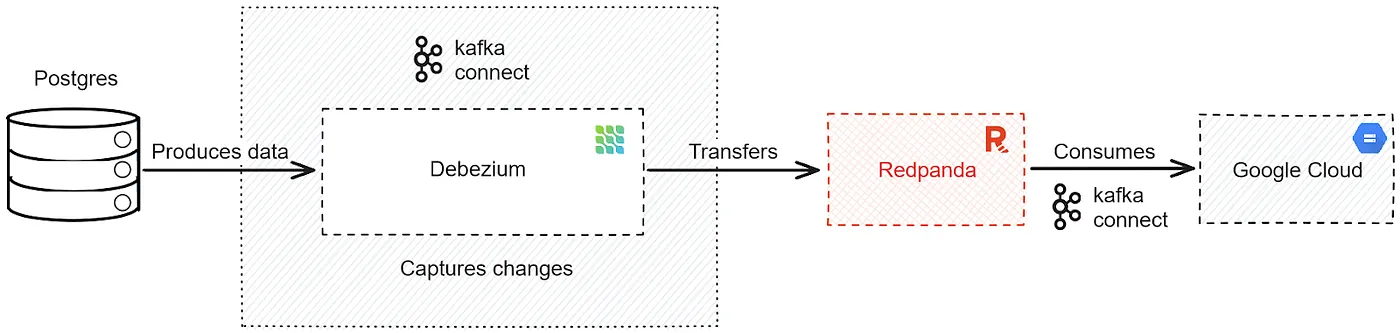
Connect Postgres data to Google Cloud Storage using Redpanda and Debezium | 8 min | Cloud | Sooter Saalu | Redpanda Data Blog
Delve into Change Data Capture (CDC) and its use cases, and provide a tutorial on implementing a real-time CDC pipeline. It's a practical guide in three steps for reliable data replication and efficient data streaming in modern cloud architectures.
How To Build Analytics With Apache Arrow? | 6 min | Data Engineering | Patrik Braborec | GoodData Developers Blog
Learn how GoodData makes its analytics platform powerful by using Apache Arrow. This article breaks down the benefits, including a semantic model and fast caching. With Apache Arrow, GoodData ensures efficient results for analytics on different data types, databases, and lake houses.
NEWS
Hands-on with Gemini: Interacting with multimodal AI | 6 min | AI | Google
Gemini is a natively multimodal AI model capable of reasoning across text, images, audio, video and code. This video highlights some of our favorite interactions with Gemini. Gemini is the first model to outperform human experts on MMLU (Massive Multitask Language Understanding), one of the most popular methods to test the knowledge and problem solving abilities of AI models.
Creating High Quality RAG Applications with Databricks | 6 min | AI | Patrick Wendell, Hanlin Tang| Databricks Blog
Databricks launches a pioneering suite of Retrieval-Augmented-Generation (RAG) tools, facilitating seamless real-time data integration into Large Language Model (LLM) applications. This release includes features like vector search services, online context serving! and managed foundation models, empowering developers to optimize the RAG process for high-quality, production-ready LLM apps.
Introducing Amazon Q, a new generative AI-powered assistant | 12 min | AI | Antje Barth | AWS Blog
Meet Amazon Q, a business-focused AI assistant that streamlines tasks, fosters innovation, and enhances decision-making by connecting to your company's data and enterprise systems. With personalized user-based plans, Amazon Q ensures tailored features and pricing while prioritizing data security and privacy.
PODCAST
Data & AI in large-scale music distribution to Spotify, Apple, Google and more | 39 min | AI | Adam Kawa, Chris Tynan | Radio DaTa Podcast
Chris Tynan is the Director of Data at DistroKid. Before joining DistroKid, he had been working at intersection of music, data and tech at Utopia Music and Spotify, as well as as a Lead Data Scientist in the UK Government Administration.
Topics that we talk about include:
- What DistroKid is, who uses it and how it works
- Data collected and analysed by DistroKid
- ML and AI in music distribution e.g. detecting bad actors
- Generative AI in the music industry e.g. deepfake voice
- Democratisation of music creation with Generative AI, mobile devices, social media
- Tech and ML/AI stack used and evaluated by DistroKid e.g. AWS, Redshift, dbt, Redash, Whisper, Amazon Rekognition
CONFS EVENTS AND MEETUPS
Data & AI Strategy in Practice: A Path to Becoming an AI-Driven Organization | Webinar | 13th December
In this webinar, you will get to see how companies like yours steer through this uncertain yet exciting landscape of data. We will share firsthand experiences from crafting data & AI strategies in the field.
You will discover the structured approach for building data strategy, and common challenges that you may face in the process. You will also have the opportunity to draw valuable lessons from actual use cases where companies have successfully leveraged data & AI.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill