
ARTICLES
D3: An Automated System to Detect Data Drifts | 13 min | AI/ML | Anshal Shukla, Vineeth Tatipathri, Nipun Vats, Dinesh Jagannathan, Kousik Nath | Uber Tech Blog
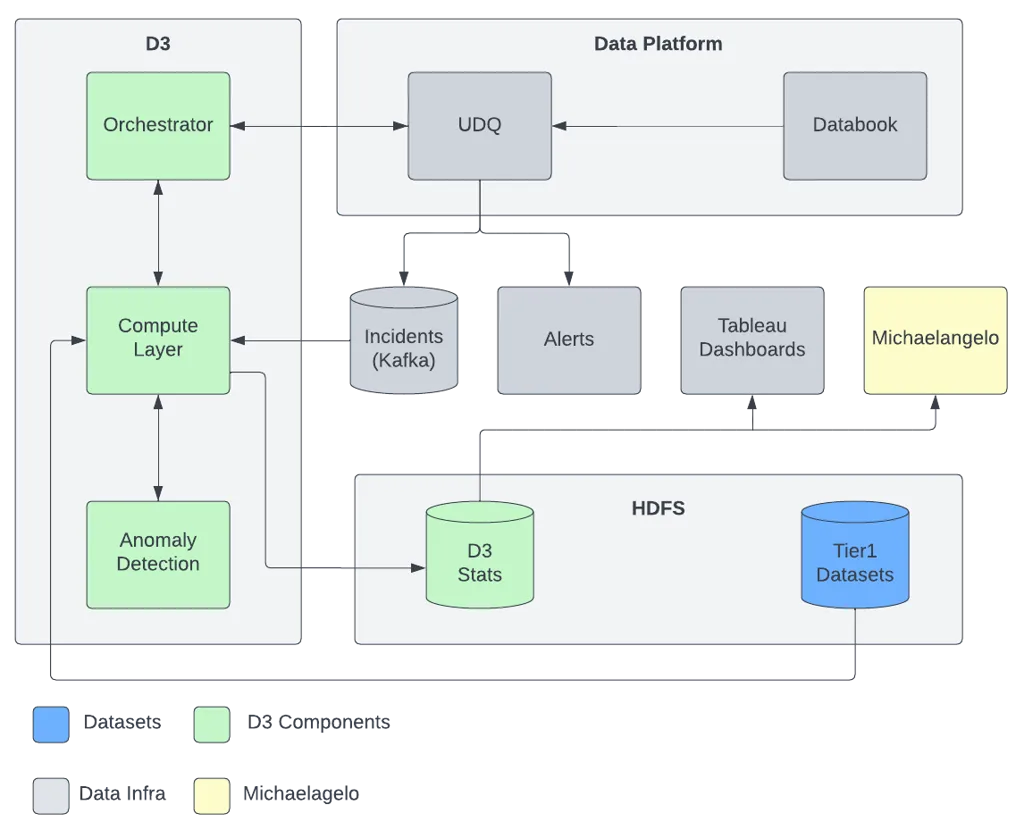
It is not common to talk about issues, but the Uber team in this blog post did it well. Many data issues are manually detected by users, weeks or even months after they start. Data regressions are hard to catch because the most impactful ones are generally silent. Check out the example, impact, detection strategies and way more.
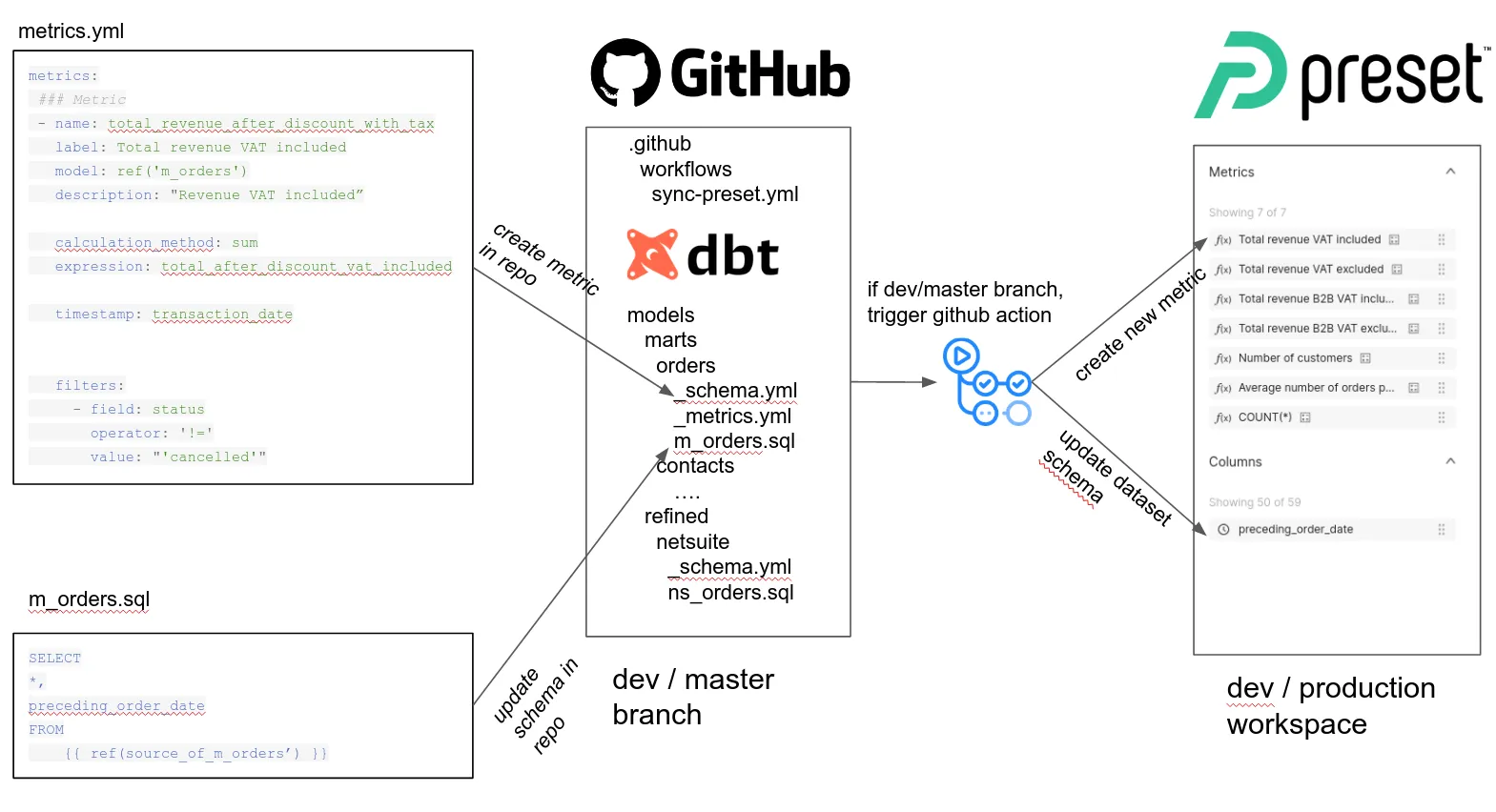
Building a semantic layer in Preset (Superset) with dbt | 5 min| dbt | Pierre Vanacker | Plum-living blog
Read about a Preset feature that allows the Plum-living team to define the data & metrics they want to expose to their users “as code” with dbt, without being tied to a closed solution or language specific to the visualization tool.
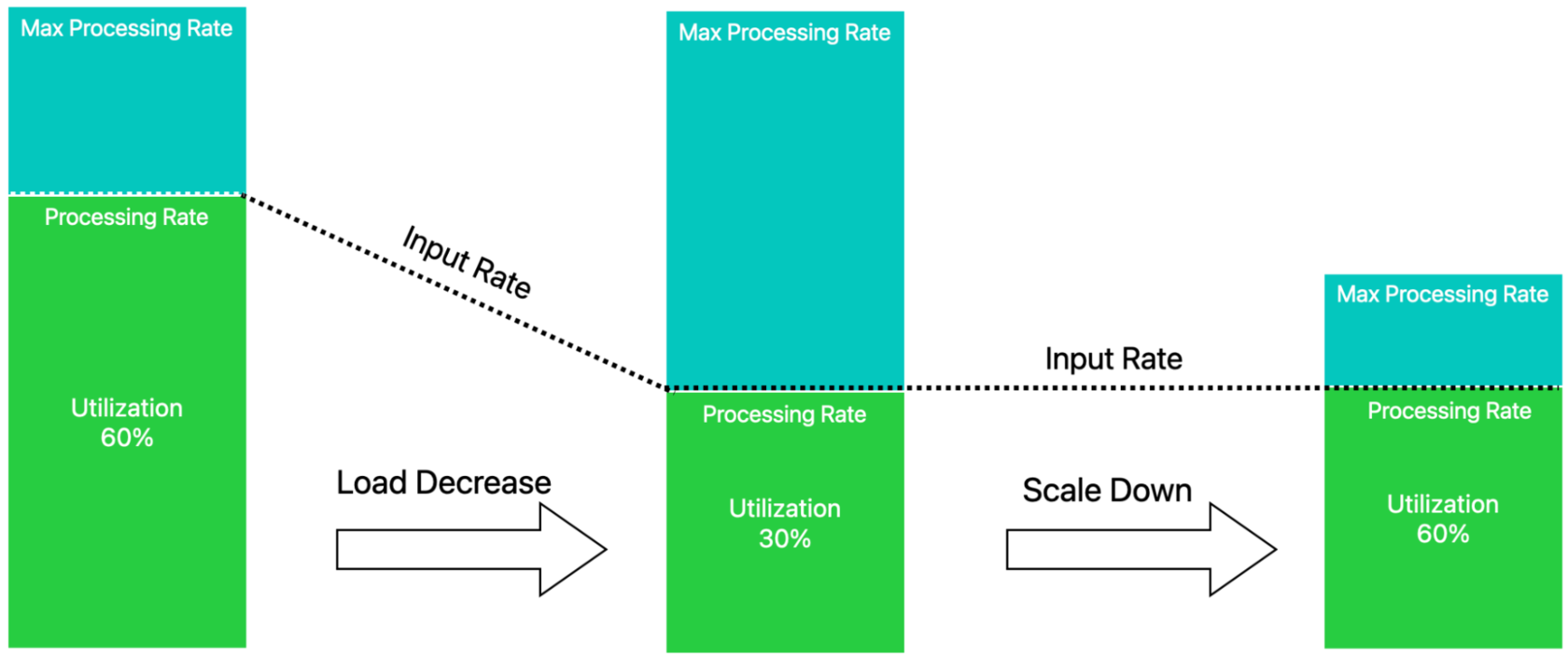
Reduce Amazon EMR cluster costs by up to 19% with new enhancements in Amazon EMR Managed Scaling | 4 min | Cloud | Sushant Majithia, Matthew Liem, and Vishal Vyas | AWS Blog
An overview of the key enhancement AWS team launched in EMR Managed Scaling. They observed that the cluster utilization improved by up to 15 percent, and cluster cost was reduced by up to 19 percent. Starting mid-December 2022, these enhancements were enabled by default for EMR clusters using Amazon EMR versions 5.34.0 and later, and Amazon EMR 6.4.0..
Why Ravioli Is My Favourite Recipe | 10 min | Data Engineering | Jeroen Rosenberg | Xebia Blog
This one sounds delicious, but what does it have in common with hexagonal architecture? Hexagonal architecture is an architectural pattern for building software. Jeroen explains what hexagonal architecture is all about and what it has to do with cooking ravioli. Read how to transform ‘spaghetti code’ into highly cohesive, loosely coupled and highly testable code using the principles of hexagonal architecture and domain driven design.
Fourier Feature Encoding | 7 min | AI | Jack Dąbrowski, Marnia Janicka, Łukasz Sienskiewicz | Sair Synerise Research
This article discusses the challenges of using numeric data for machine learning in various sectors such as finance, medicine and social media. Although numeric data may seem ready for use, additional steps such as normalization and outlier removal are often necessary to obtain accurate results. However, computing statistics for the entire dataset can be difficult and time-consuming, especially for big data streams. Additionally, new data may not fit with previously computed statistics, which can impact model performance.
Onion Architecture | 7 min | Architecture | Tomasz Tarczyński | Allegro Tech Blog
Onion Architecture is a software architectural style which promotes the separation of concerns between the most important part of a business application — the domain code — and its technical aspects like HTTP or the database. It does so with ideas similar to Hexagonal Architecture, Clean Architecture and other related architecture styles.
It can solve numerous of issues like:
- A more structured, layered layout of the code makes code navigation easier and makes the relationship between different parts of the codebase more visible at first glance
- Loose coupling between the domain and the infrastructure
- Coupling is towards the center of The Onion — expressed by the relationship between the layers
Scaling Media Machine Learning at Netflix | 11 min | ML | Gustavo Carmo, Elliot Chow, Nagendra Kamath, Akshay Modi, Jason Ge, Wenbing Bai, Jackson de Campos, Lingyi Liu, Pablo Delgado, Meenakshi Jindal, Boris Chen, Vi Iyengar, Kelli Griggs, Amir Ziai, Prasanna Padmanabhan, and Hossein Taghavi | Netflix Blog
The Netflix media-focused ML infrastructure goal is to reduce the time from ideation to productization for media ML practitioners. They accomplish this by paving the path to:
- Accessing and processing media data (e.g. video, image, audio and text)
- Training large-scale models efficiently
- Productizing models in a self-serve fashion in order to execute on existing and newly arriving assets
- Storing and serving model outputs for consumption in promotional content creation
In this post you will find:
- challenges of applying machine learning to media assets
- the infrastructure components
- case study of using these components in order to optimize, scale and solidify an existing pipeline.
TUTORIAL
Comparing SQL-based streaming approaches | 26 min | Data Analytics | Georg Heiler | Personal Blog
This post was made to compare the various existing streaming tools and get a feeling for their pros and cons. Let’s explore not only an analytical but also an operational (very low latency) data integration, which consists of the following steps in order to create a real-time core streaming data model:
- read (one or more) topic(s) from the streaming ledger
- arbitrary (stateful) computation
- (if necessary) write the results back into the streaming ledger (so that other operational analytical processes can subscribe and react to events)
Improving the Developer Experience with the Ruby LSP | 13 min | Data Engineering | Vinicius Stock | Shopify Engineering Blog
Improving the experience of coding in Ruby is highly aligned with its goal of making the developer happy—and the future of Ruby tooling is exciting. If you want to know how the Shopify Team built the Ruby LSP, the features included within it and how you can install it, then your search is over.
Ray on Databricks | 12 min | Data Engineering | Stephen Offer | Databricks Blog
In this one, firstly you will find the answer to the question: why may you need another distributed framework on top of Spark? There is also a simple introduction to Ray Architecture, and finally starting that on a Databricks Cluster.
NEWS
Apache Flink Kubernetes Operator 1.4.0 Release Announcement | 4 min | Data Engineering | Gyula Fora, Maximilian Michels, Matyas Orhidi | Data Center Knowledge
Apache has announced the latest stable release of the operator. In addition to the expected stability improvements and fixes, the 1.4.0 release introduces the first version of the long-awaited autoscaler module.
PODCAST
Building a Data Mesh Platform at PayPal | 47 min | Data Mesh | Host: Tobias Macey, Guest: Jean-Georges Perrin | Data Engineering Podcast
In this episode, Jean shares his experience on the application of data mesh, how to implement it in an organization and the combination of technical and organizational challenges that he encountered in the process. Some of the questions that were asked in this episode:
- What are the core problems that he addressed in this project?
- Is a data mesh ever "done"?
- What are the most interesting, unexpected, or challenging lessons that he learned while working on data mesh?
CONFS EVENTS AND MEETUPS
Big Data Tehnology Warsaw Summit | 29-30th March 2023 | Hybrid
- You'll get to hear from some of the top experts in the field, with speakers from companies like Meta, Google, Airbnb and Xebia
- You'll learn about the latest trends and technologies in big data, AI, data engineering, real-time streaming, cloud, data science, MLOps and how they can be applied to real-world problems.
- You'll have the opportunity to network with other professionals and make valuable connections in the industry during discussions in 20 round tables.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
