
ARTICLES
A standardised, scalable way for sharing data in real-time | Telecom | Data Science | Michael Loh | Digital at Virgin Media O2 blog
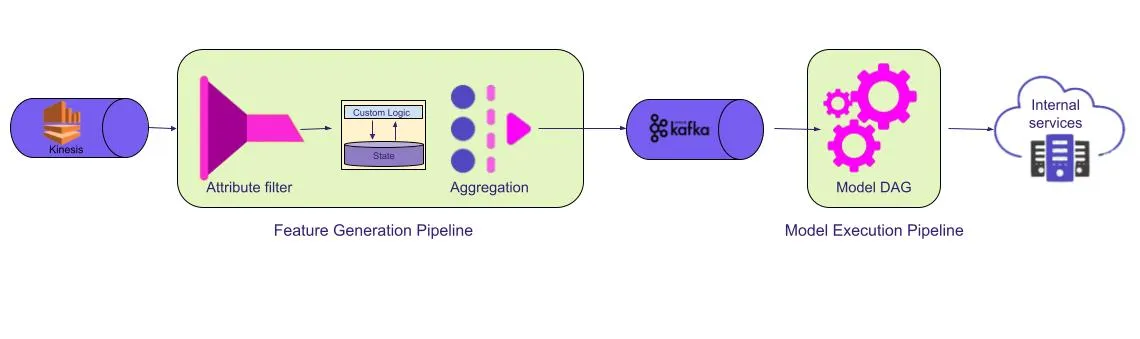
The Virgin Media O2 team encountered an issue when attempting to centralize their data in the cloud - stakeholders lacked a standardized, efficient method of accessing it instantaneously. As a solution, the team is developing a data ingestion framework that combines their operational and analytical pipelines and caters to both real-time events and batch ingestion techniques. This article details the solution's architecture and the workings of the analytical pipeline.
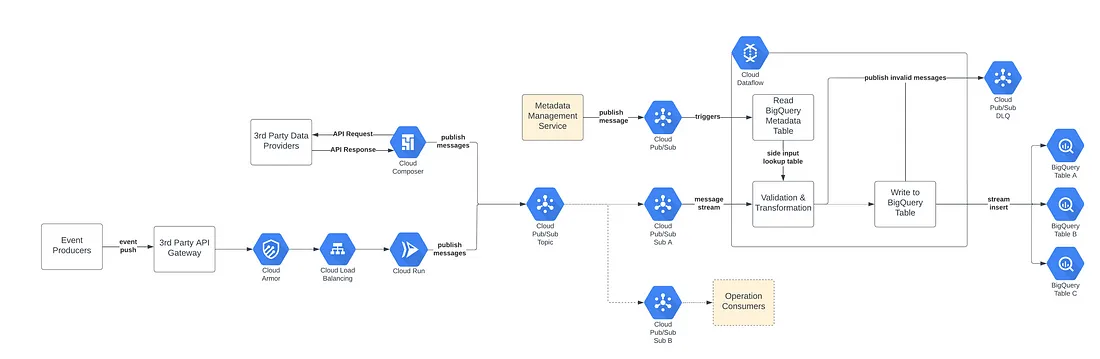
Evolution of ML Fact Store | Entertainment | ML | Vivek Kaushal | Netflix Technology Blog
This article highlights the importance of continuously evolving and improving infrastructure to support ML models as organizations grow and scale. Initially, the Fact Store was created as a simple database to serve predictions from an ML model. However, as the organization grew and started using more complex models, the Fact Store also needed to evolve. Read learnings from Netflix team evolution.
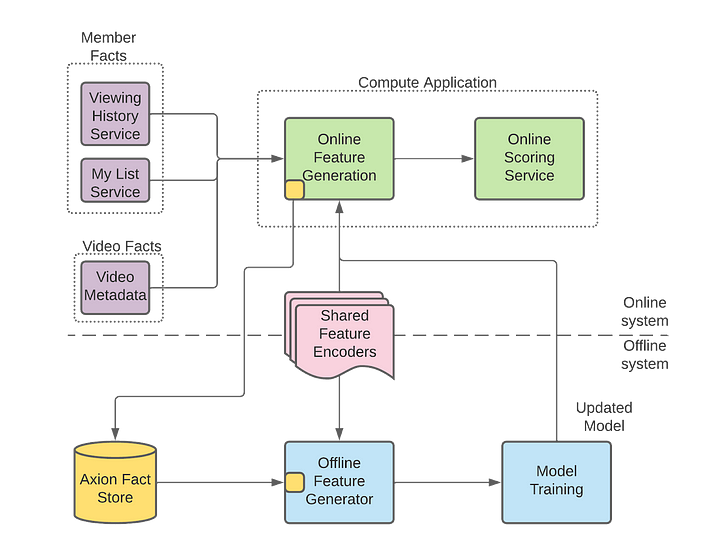
Scaling data access by moving an exabyte of data to Google Cloud | Media | Cloud | Wini Tran, Di Zhao | Twitter Engineering blog
A good read about how Twitter is moving an exabyte of data to the cloud through a partnership with Google Cloud. It also discusses how Twitter's engineers are scaling data access by implementing a "Data Commons" model that simplifies discovering, accessing, and sharing data across the company. Dive into details on the technical challenges and solutions implemented to achieve this massive migration. This includes developing a custom data transfer system and optimizing storage and networking.
Improving Distributed Caching Performance and Efficiency at Pinterest | Media | Data Engineering | Kevin Lin | Pinterest Engineering
How has Pinterest improved its distributed caching performance and efficiency? Read about the challenges of caching in a distributed system, which can lead to slowed performance and inefficiencies if not properly managed.
Pinterest's solution involved several steps, including optimizing the data structure of their cache, using consistent hashing to distribute requests, and implementing a smarter eviction policy. They also adopted a new method for monitoring cache performance, allowing them to identify and solve problems quickly.
How we built a Modern Data Platform in 4 months for Volt.io, a FinTech scale-up | FinTech | DataOps | Paweł Kociński, Rafał Zalewski | GetInData | Part of Xebia Blog
This article concerns the challenges faced during the development process, such as dealing with legacy systems and integrating multiple data sources. It explains how the platform was built using open-source technologies, such as Apache Kafka and Apache Flink, and how it was designed to be scalable and fault-tolerant.
Also, dive into the benefits of the modern data platform for the Fintech start-up, including faster processing times, improved accuracy, and better insights into customer behavior.
Evolution of Streaming Pipelines in Lyft’s Marketplace | Transportation| Rakesh Kumar | Streaming | Lyft Engineering
Lyft's journey of evolving our streaming platform and pipeline to better scale and support new use cases. Each iteration provided a better scale but also exposed shortcomings.
Data Modeling Today: launching cost-effective analytics for ManyChat | Marketing | Nikolay Golov | Data Engineering | Personal Blog
By leveraging proper data architecture, the ManyChat use case demonstrates that one can move away from linearly increasing expenses corresponding to higher data volume and instead adopt nearly constant costs. This underscores the importance of developing adaptable analytical platforms for startups with dynamic business models, as proposed by Nikolay.
Upgrading Data Warehouse Infrastructure at Airbnb | Lodging | Data Engineering | Ronnie Zhu, Edgar Rodriguez, Jason Xu, Gustavo Torres, Kerim Oktay, Xu Zhang | The Airbnb Tech Blog
Airbnb’s experience with upgrading their Data Warehouse infrastructure to Spark and Iceberg.
In our data ingestion framework, we found that we could take advantage of Iceberg’s flexibility to define multiple partition specs to consolidate ingested data over time. Ingested tables write new data with an hourly granularity (ds/hr), and a daily automated process compresses the files on a daily partition (ds), without losing the hourly granularity, which later can be applied to queries as a residual filter.
Why we migrated to a Data Lakehouse on Delta Lake for T-Mobile Data Science and Analytics Team | Telecom | AI | Robert Thompson, Geoff Freeman AI | Delta Lake Blog
In 2018, T-Mobile relied on weekly reporting using Excel and PowerPoint. However, they progressed towards V1- Delta Lake (TMUS) and ultimately reached V2- Data Lakehouse. The transition was influenced by factors such as the need for change, the architecture, and the approach of iteration and centralization.
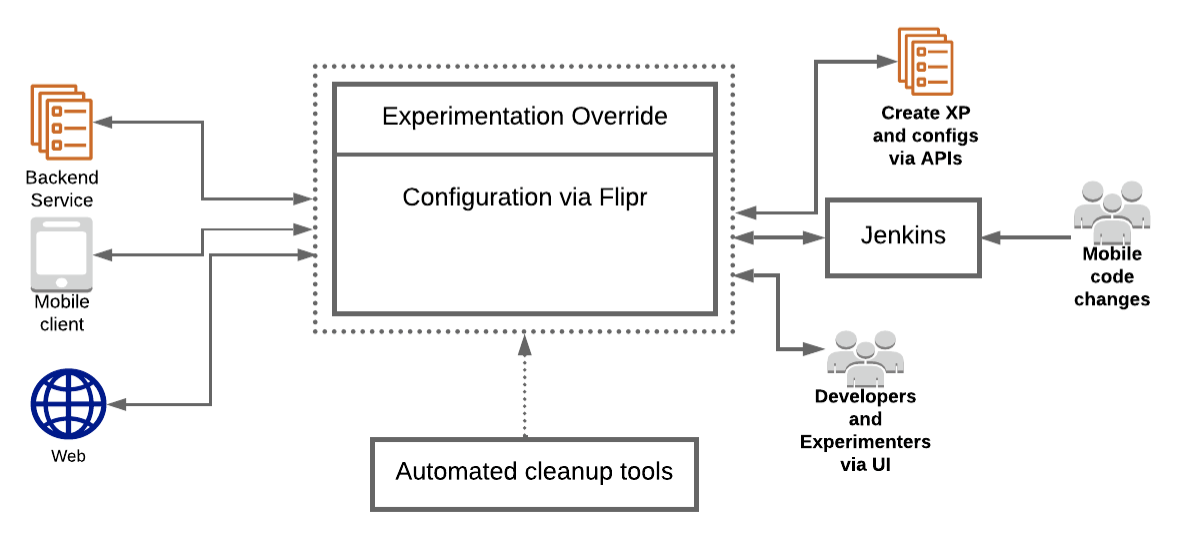
Supercharging A/B Testing at Uber | Transportation | ML | Sergey Gitlin, Krishna Puttaswamy, Luke Duncan, Deepak Bobbarjung, Arun Babu A S P | Uber Engineering Blog
This comprehensive piece examines Uber's latest testing platform project, which involved replacing their Morpheus experimentation platform built over 7 years ago for feature flagging and A/B testing. As Uber has vastly expanded since then, with increased scale, users, and use cases, Morpheus needs to be improved. Hence, in 2020, Uber embarked on developing a new testing platform. The article delves into the project's assumptions, implementation process, and outcomes.
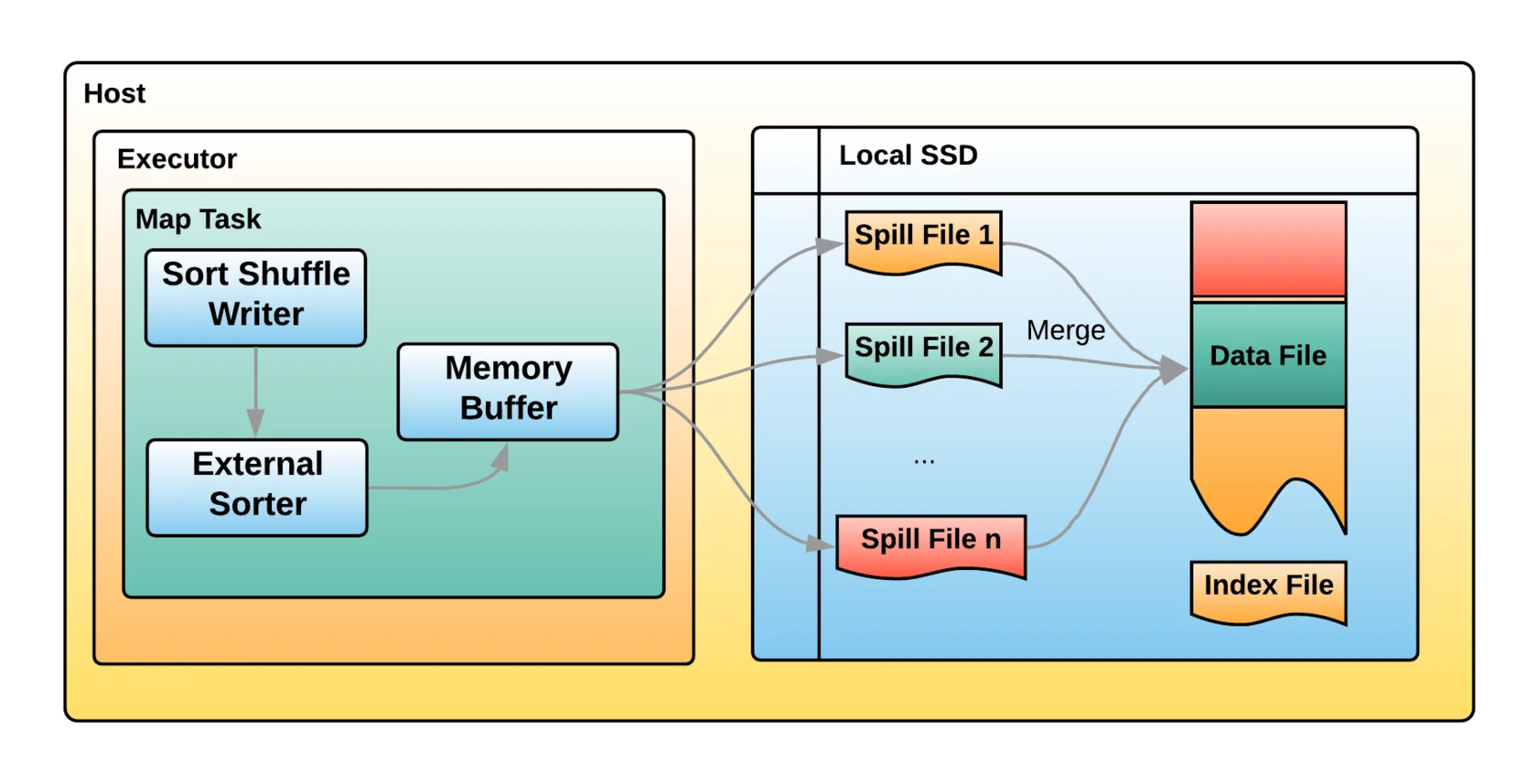
Uber’s Highly Scalable and Distributed Shuffle as a Service | Transportation | Streaming | Mayank Bansal, Bo Yang, Mayur Bhosale, Kai Jiang | Uber Engineering Blog
For those still feeling sentiment to Hadoop & Spark on-premise. Uber still invests much in an open-source, on-premise Spark/YARN setup!
VIDEO
Benefits of a Homemade ML Platform | Apps | ML | Bartosz Chodnicki & Liniker Seixas | GetInData | Part of Xebia
In this presentation, Bartosz and Liniker explain their decision to construct their custom MLOps platform without entirely disregarding existing options, as they combined them with personalized elements. They will discuss the advantages and setbacks of this approach and detail the obstacles we faced. Their objective is to share experience, enabling you to make informed project decisions, even if it means taking more calculated risks.
PODCASTS
Data Journey with Arunabh Singh (Willa) - Building robust ML & Analytics capability very early, data & analytics at a FinTech, skills & competences for data scientists, ML/AI predictions for the next decades | FinTech | ML & AI | hosts: Adam Kawa; guests: Arunabh Singh | Radio DaTa
Arunabh Singh is a director of data science at Willa - FinTech, which helps professional freelancers, influencers, and social media content creators get paid immediately by brands for their freelance work and paid collaborations.
Topics of the podcast:
- Data that is used at Willa and business use cases that are developed using this data
- The most important ML models implemented at Willa
- The ML(Ops) stack at Willa and a decision to build ML & Analytics capability very early
- The most important skills and competencies that data scientists should have these days
- The main trends and predictions for ML/AI for the next decades
- Plans for 2023 at Willa.
CONFS EVENTS AND MEETUPS
MS Tech Summit 2023 | 11-12th May | Online & Onsite, Warsaw
Are you involved in any area (from development to DevOps and cloud to architecture) related to Microsoft technologies? If so, MS Tech Summit is an event made for you. Some of the lectures will be in Polish and some in English. You will be able to listen to an English-language speech by Marcin Zabłocki.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
➡ Dig previous editions of DataPill
