
ARTICLES
Top 10 Cloud Service Providers Globally in 2022 | 12 min read | Cloud | Mary Zhang| DGTL Infra
Did you know that the top 10 cloud service providers capture ~77% of spending on cloud infrastructure services? On the other hand, there is still a significant number of small vendors present in global markets such as Huawei Cloud, UCloud in China or Bleu in Europe.
Open source isn't working for AI | 8 min read | AI | Matt Asay | InfoWorld
There are really just three companies pushing the industry forward: Facebook, OpenAI, and Google. What do they have in common? The ability to run massive models at scale. In other words, they’re doing AI in a way that you and I can’t. They’re not trying to be secretive; they simply have the infrastructure and knowledge of how to run that infrastructure that you and I don’t.
Implementing Data Observability in Modern Data Warehouses using dbt | 4 min read | Data Observability | Shankar Narayanan | Snowflake
There are a lot of commercial tools and open source frameworks which provide the capabilities of implementing data quality into the data engineering process, but the author explores how we can implement data observability with just core dbt.
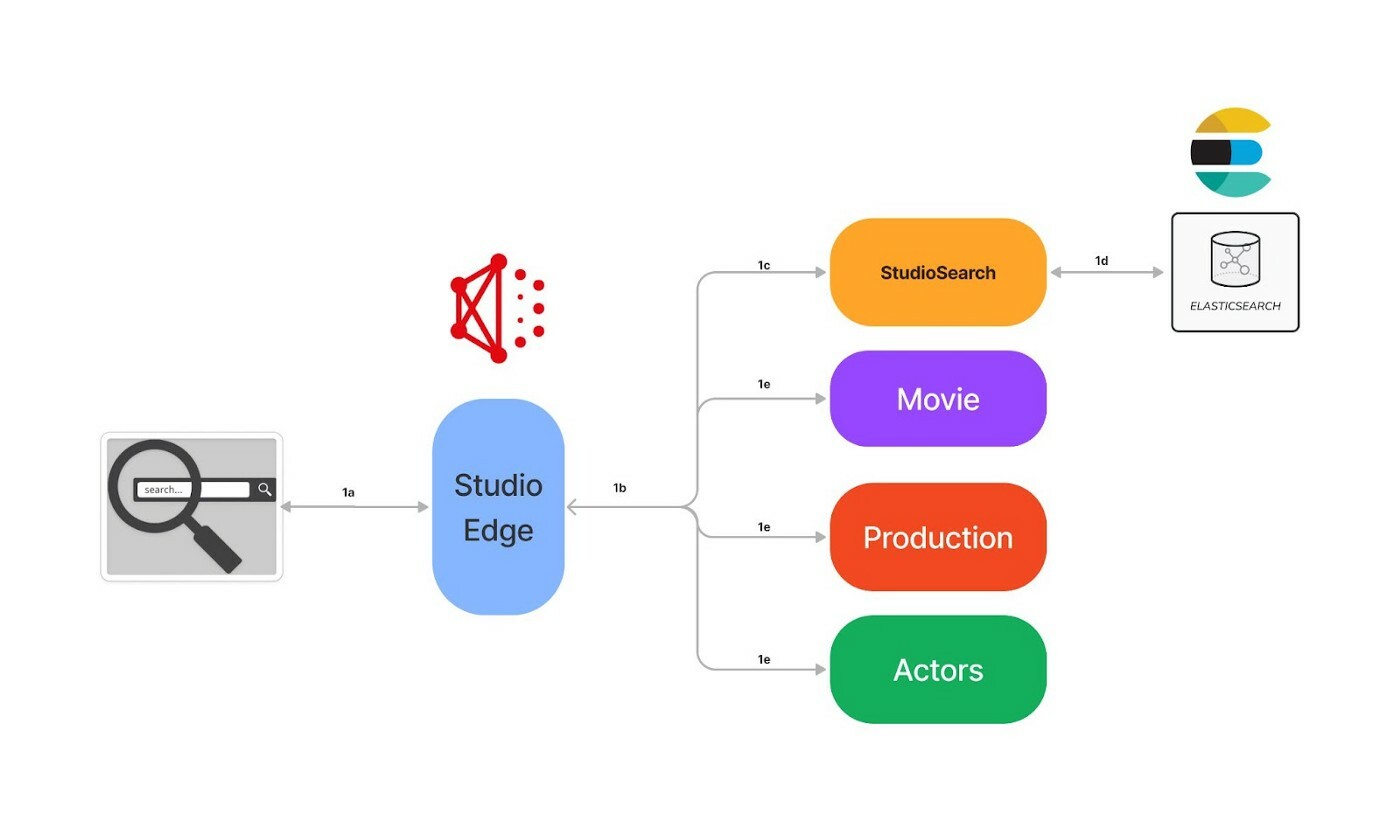
How Netflix Content Engineering makes a federated graph searchable | 8 min read | Graphs | Alex Hutter, Falguni Jhaveri, and Senthil Sayeebaba | Netflix Technology Blog
This is a second part of the blog post, where the author describes how Studio Search supports querying the data available in indices.
TUTORIALS
Process Apache Hudi, Delta Lake, Apache Iceberg datasets at scale, part 1: AWS Glue Studio Notebook | 20 min read | Google Cloud | Monjumi Sarma Noritaka Sekiyama Dylan Qu | AWS Blog
The above article provides the instructions on how to read/write tables using each data lake format on AWS Glue Studio Notebook.
NEWS
Introducing Batch, a new managed service for scheduling batch jobs at any scale | 7 min read | Bolian Yin & Shamel Jacobs | Google Cloud
Google Cloud has added cloud native support for batch workloads! Last week they announced the release of Batch - a fully managed batch service to schedule, queue, and execute batch jobs on Google's infrastructure.
- Run batch jobs as a service
- Provision compute resources
- Use accelerator-optimized resources
- Support common job types
- Handle any executable.
- Provide flexible provisioning models
- Simplify native integrations with Google Cloud services as well as popular workflow engines and tools such as Nextflow.
What is Dataplex? | 15 min read | Google Cloud
Dataplex is an intelligent data fabric that helps you unify distributed data and automate data management and governance across that data to power analytics at scale.
DATAtube
OpenLineage Community Meeting | 53 min | OpenLineage
During the OpenLineage Meeting, the speaker talked about recent releases, updates on the progress of Flink integration, streaming services and more.
Interview: Machine Learning with Apache Flink | 55 min | Decodable
This is the interview with Dong L, the Apache Flink committer. The main lesson learned by the host Robert Metzger was that Flink ML is particularly well suited for feature engineering, and there's a growing ML ecosystem for Flink.
Why Data Engineers Need To Understand Subnets And 3 Other Skills DEs Need To Know | 8 min | Seattle Data Guy
In this video you will find out about the skills that data engineers need, but also about the skills that have arguably nothing or very little to do with data.
PODCAST
ML Flow vs Kubeflow 2022 | 58 min | MLflow Kubeflow | ML Community
During the #108 MLOps Coffee Sessions, Byron Allen talks about why MLflow and Kubeflow are not playing the same game!
Making the Total Cost of Ownership For External Data Manageabley| 40 min | Data Platform | Data Engineering Podcast
Mark Etherington, CTO in Crux discusses, for example, the different costs involved in managing external data.
CONFS AND MEETUPS
During the summer holidays, I would like to invite you to two meetups:
Data Science Meetup - Kubeflow | Hamburg Data Science Meetup | 28 July | Online
Feature Engineering for Time Series Forecasting | 2 August | Online
