
ARTICLES
Blog CI/CD in dbt Cloud with GitHub Actions: Automating multiple environments deployment | 10 min | dbt| Lucas Ortiz | Xebia Blog
Do you remember Lucas’s text from DATA Pill #49? Unfortunately, he left the deployment pipeline setup for a later moment. Good news for those who were waiting. The guide through setting up an automated deployment pipeline that continuously runs integration tests and delivers changes (CI/CD), including multiple environments and CI/CD buildsas soon as pull requests are opened in the code repository - it's available right now. Check out how to set up your environment to release changes as many times as you want, making your job easier.
How Zoom implemented streaming log ingestion and efficient GDPR deletes using Apache Hudi on Amazon EMR | 6 min | Streaming | Sekar Srinivasan, Amit Kumar Agrawal, Chandra Dhandapani, Viral Shah | AWS Blog
This article shares what Zoom and the AWS Data Lab team have accomplished together to solve critical data pipeline challenges, and Zoom has extended the solution further to optimize extract, transform, and load (ETL) jobs and resource efficiency.
Telecom’s Big Opportunity in the Data Economy | 5 min | Cloud | Jennifer Belisseni | Snowflake Blog
The article touches the various opportunities that telecom companies can leverage in this data-driven economy. From insights regarding customer behavior to identifying new revenue streams, data is an essential tool that telecom companies can use to their advantage. Jennifer in the text also examines the challenges in utilizing this data, given the complexity and volume of information.
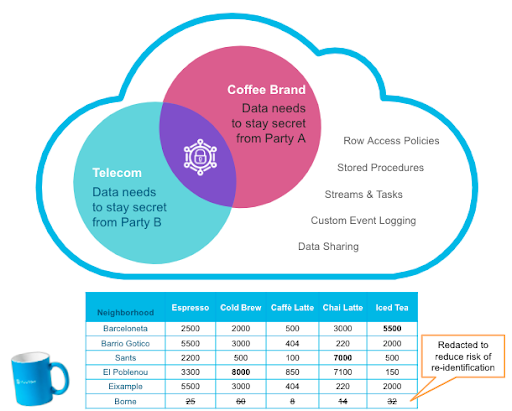
Writing Flink jobs using the Spring dependency injection framework | 13 min | Streaming | GetInData | Part of Xebia Blog
How can the popular Spring Dependency Injection Framework be leveraged to write #Flink jobs in a more structured and organized way?
By creating reusable components and defining them within a Spring context, you can easily manage and modify dependencies, leading to more efficient development processes.
In his blog, Krzysztof explains how Spring can help create high-quality Flink applications and provide invaluable insights to businesses.
Introducing Segment Anything: Working toward the first foundation model for image segmentation | 6 min | Data Science | Meta AI Blog
Read about Facebook's AI model for image segmentation called Segment Everything. The article explains how the model works, its key features and its potential applications. Also, you will find out more about the potential applications of Segment Everything, such as improving Facebook's image and video understanding capabilities, enabling more realistic augmented reality experiences and supporting the development of autonomous vehicles.
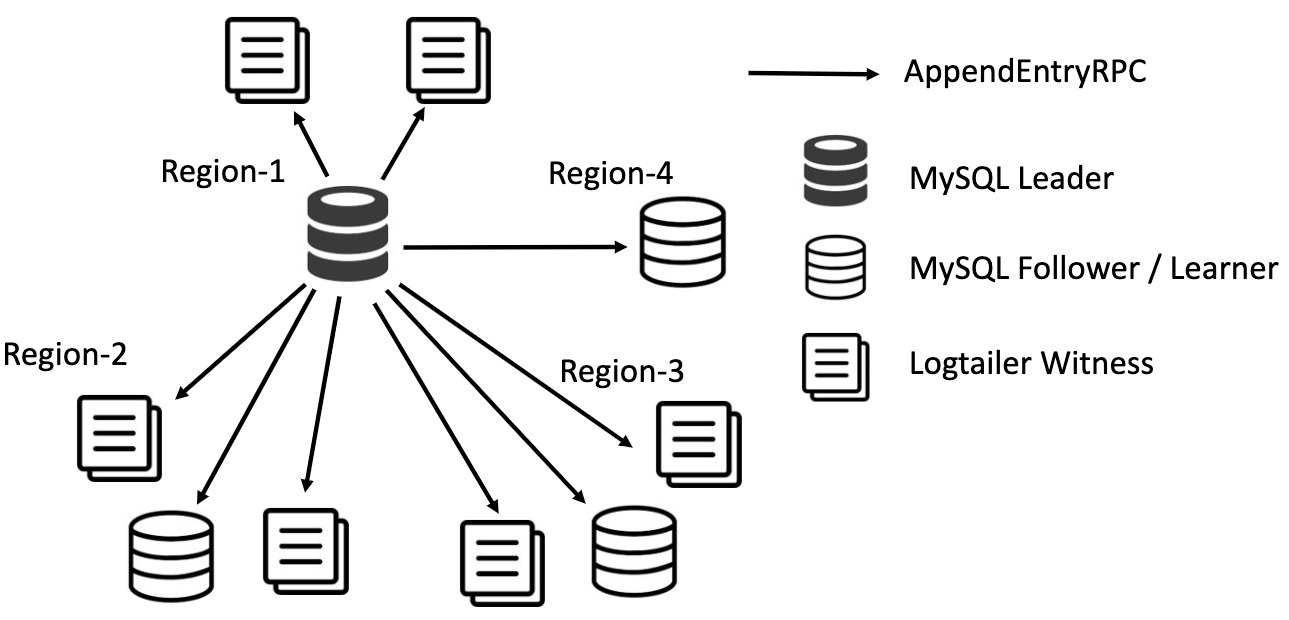
Building and deploying MySQL Raft at Meta | 12 min | AI | Anirban Rahut, Abhinav Sharma, Yichen Shen, Ahsanul Haque | Meta AI Blog
Let’s focus on the challenges faced by Facebook while scaling to achieve its goals.
The article explains in detail the use of MySQL Raft Meta, which is a distributed consensus algorithm used by Facebook to maintain the consistency and integrity of its databases.
Build Your Data Skills with the Data Literacy Trail on Trailhead | 5 min | Data Literacy | Sue Kraemer | Tableau Blog
Have you ever wanted to start building your data literacy? The Data Literacy Trail covers topics such as data preparation, data analysis and data visualization, enabling learners to understand how to work with data efficiently. It features guided learning pathways, interactive quizzes and real-world scenarios that help practice skills. Trailhead will help you develop your data skills.
Since we are talking about analytics, there is an interesting job offer available in that area.
TUTORIAL
Deploy MLFlow models on BigQuery | 11 min | ML | Marcin Zabłocki | Personal Blog
It can be difficult to deploy machine learning models and ensure their accessibility for other teams, particularly data and business analysts, but reading this one can be helpful. Marcin created a great tutorial on how to deploy MLflow models to the GCP Cloud Run service in a way that they could be consumed from BigQuery using SQL.
NEWS
Announcing new Jupyter contributions by AWS to democratize generative AI and scale ML workloads | 3 min | AI | Brian Granger | AWS Blog
New tools for Jupyter users to improve their experience and boost development productivity are available now. These extensions enable you to perform a wide range of development tasks using generative AI models in JupyterLab and Jupyter notebooks. All of these are open-source and can be used anywhere you are running Jupyter.
Debezium 2.3.0.Alpha1 Released | 3 min | Data Engineering | Chris Cranford | Debezium Blog
Debezium announces the first release of the Debezium 2.3 series, 2.3.0.Alpha1.
This release brings many new and exciting features as well as bug fixes, including Debezium status notifications, storage of Debezium state into a JDBC data store, configurable signaling channels, the ability to edit connector configurations via Debezium UI, the parallelization of Vitess shards processing, and much more.
New debugging features for Databricks Notebooks with Variable Explorer | 3 min | Cloud | Jaipreet Singh, Weston Hutchins, Cong Lu, Ryan Wan, Jove Yuan | Databricks Blog
Databricks announces the general availability of the Variable Explorer for Python in the Databricks Notebook. The Variable Explorer provides a graphical representation of the data frames, tables, and variables created in a notebook, allowing users to quickly see the structure and content of their data.
DATA TUBE
Run machine learning pipelines on Snowflake using Kedro. MLOPS TUTORIAL | 20 min | MLOps | Marcin Zabłocki | GetInData | Part of Xebia
The next part of MLOps tutorials series in which we prove you can run Kedro pipelines… everywhere. Kedro-snowflake is the newest GetInData | Part of Xebia’s plugin that allows you to run full Kedro pipelines in Snowflake.Thanks to this, you can build your ML pipelines in Kedro and execute them in a scalable Snowflake environment in three simple steps.
CONFS EVENTS AND MEETUPS
MLOps at Dutch Unicorn Fintech Mollie | 23rd May | Online
In this webinar, Mollie will share their MLOps journey, from initial idea to current use, showcasing their custom platform built around Google's Vertex AI and other tools.
The presentation aims to deepen attendees' understanding of MLOps and provide actionable strategies for improving the model development process and achieving reliable, scalable, and maintainable deployments. It will equip participants with the knowledge to implement MLOps in their own ML projects and organizations.
Cloud Leadership Day | 21th June | Zurich
Join Xebia, Swisscom, Microsoft, Lufthansa Group and others at Cloud Leadership Day, where the brightest minds and industry leaders will converge to explore the latest trends, innovations, and strategies shaping the future of cloud computing. Gain invaluable insights and connect with like-minded professionals who are passionate about leveraging the power of the cloud.
You will dive into topics like:
- How To Align AI Technology with Your Business Strategy
- A Journey through FinOps and Multi-Cloud Strategy
- Breaking the Data-Business Divide: Successful Data Strategy Execution
- Generative AI in Finance
and many more.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Dig previous editions of DataPill
