
ARTICLES
Scaling our tagging system with hybrid graph‑semantic search | 15 min | Data Engineering & ML | TripAdvisor
TripAdvisor describes how it built a knowledge graph and semantic‑search layer to improve the relevance of user‑generated tags for points of interest. Interest‑based shelves and dynamic tag clusters improved click‑through rates by more than 10 % while enabling users to discover places aligned with their interests.
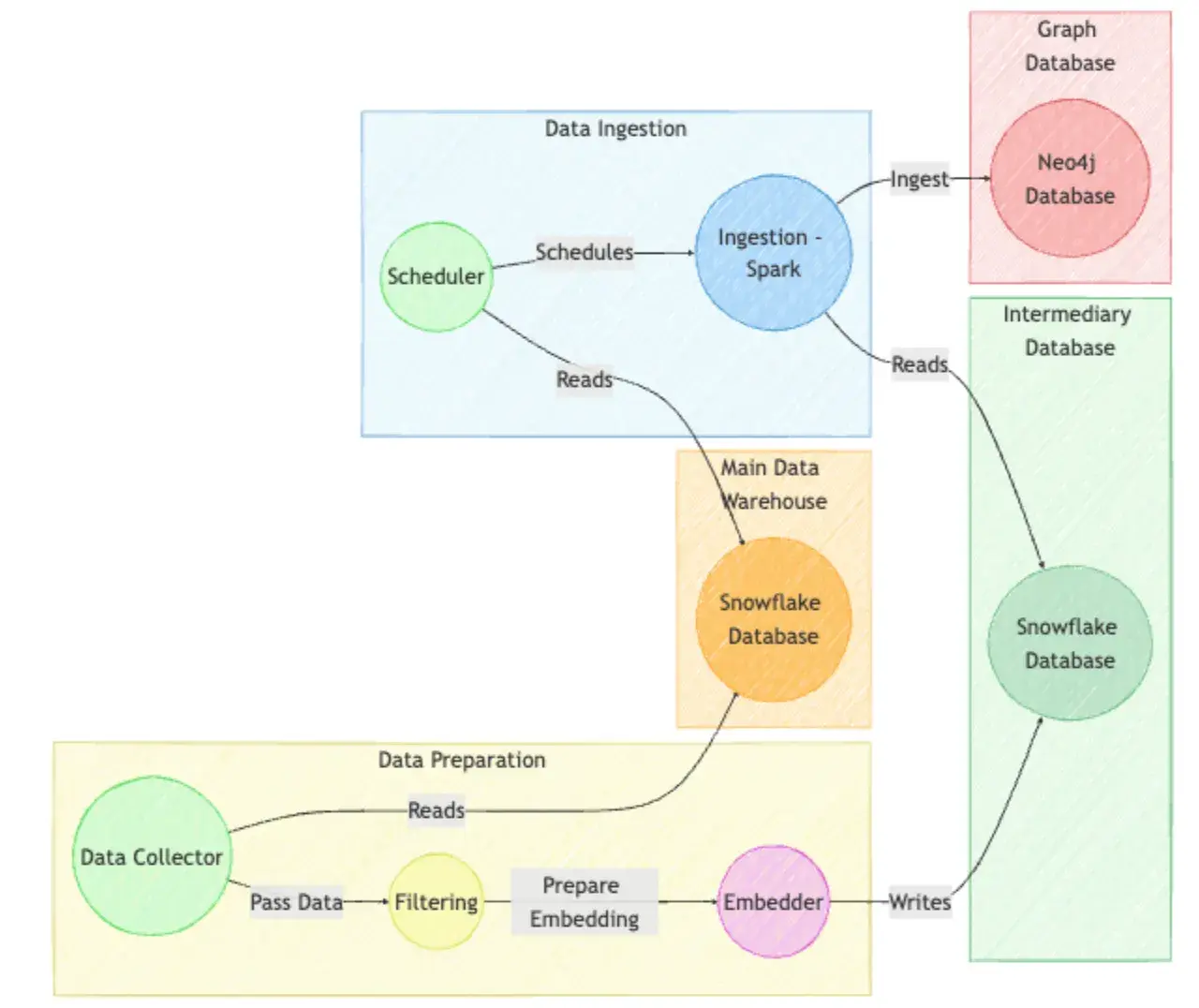
How Shopify handles 30 TB of data every minute with a monolithic architecture | 6 min | Data Engineering | Himanshu Singour
Shopify’s “modular monolith” processes roughly 30 TB per minute. The post explains how hexagonal architecture, Packwerk‑enforced modules and separate pods scale horizontally to handle millions of requests while keeping the monolith manageable
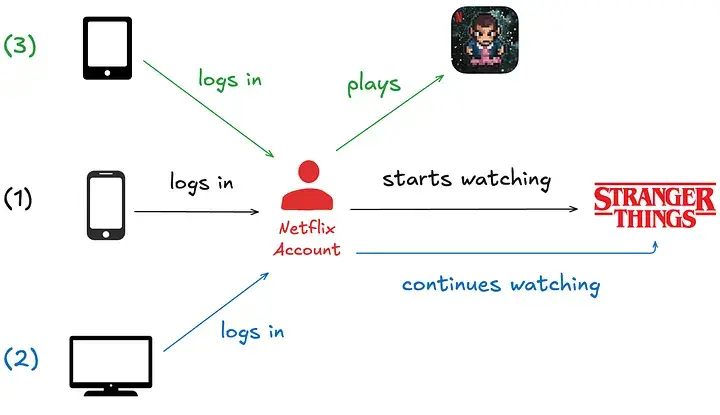
How and Why Netflix Built a Real‑Time Distributed Graph – Part 1 | 10 min | Streaming | Adrian Taruc & James Dalton
A Real‑Time Distributed Graph (RDG) powers Netflix personalisation by modelling entities and interactions as connected nodes. Kafka ingests data and Apache Flink filters, enriches and deduplicates millions of events per second, keeping the graph continuously up to date for instant cross‑domain insights.
StreetReaderAI: Towards making street view accessible via context‑aware multimodal AI | 6 min | AI & Accessibility | Jon E. Froehlich & Shaun Kane
Google Research introduces StreetReaderAI, a prototype that uses context‑aware multimodal AI and accessible navigation controls to help visually impaired users explore street‑view imagery
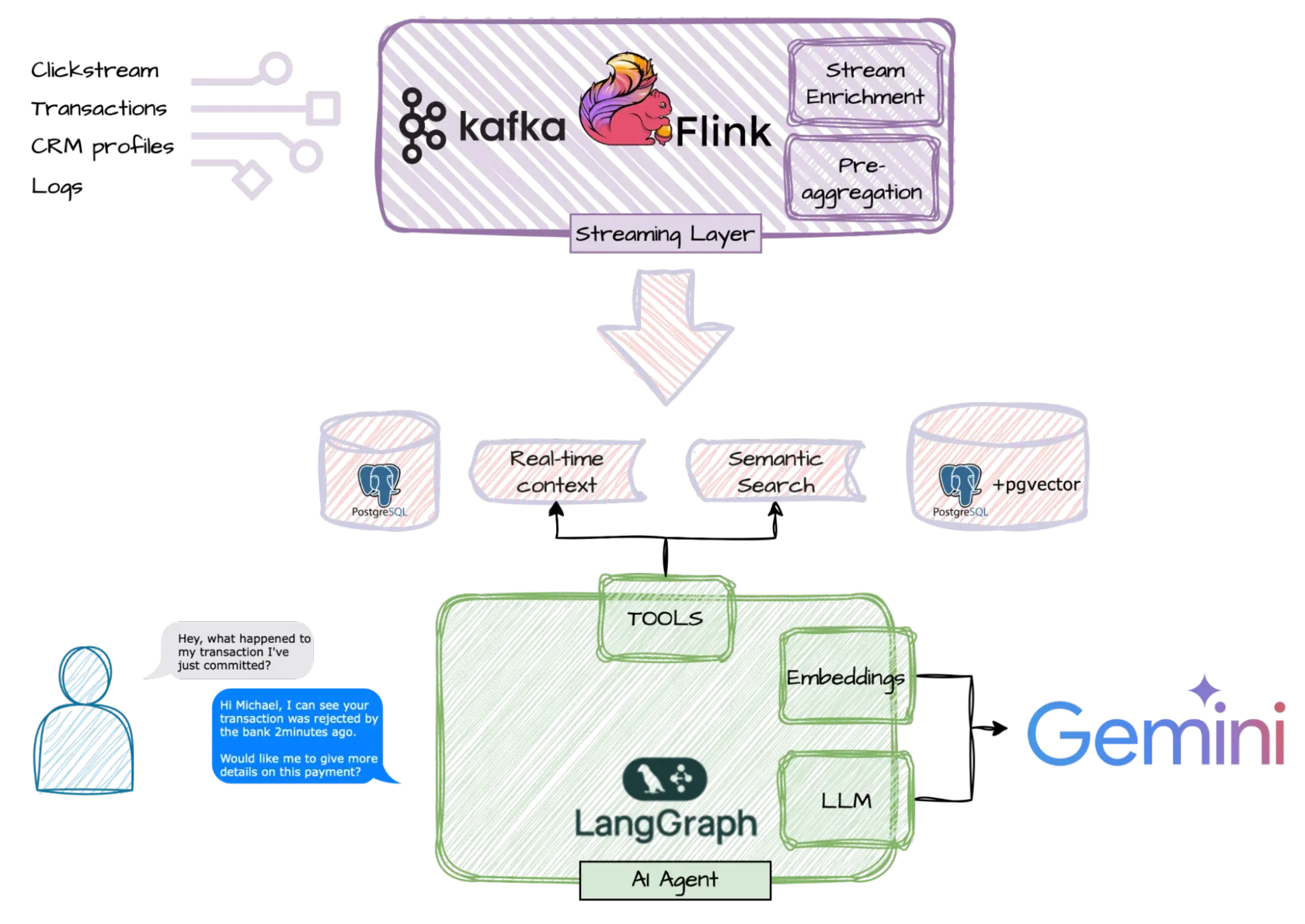
Beyond RAG: AI agents with a real‑time context | 9 min | AI Agents | Marek Maj
This post argues that retrieval‑augmented chatbots suffer from “contextual blindness” when relying on stale batch data. A new architecture combines Apache Kafka, Flink and LangGraph with pgvector to stream events and maintain real‑time context so agents can answer with up‑to‑the‑moment business information
Reading from DuckLake using Unity Catalog | 4 min | Data Lakehouse | Diederik Greveling
Diederik shows how to connect DuckDB’s DuckLake (via MotherDuck) to Databricks’ Unity Catalog. The tutorial walks through creating a DuckLake database, generating data with TPC‑H, storing Parquet files on S3 and mounting them as external tables. Because DuckLake uses delete files, the post recommends rewriting data and expiring snapshots as a workaround
The AI Guardian: Real‑time pattern detection for fair play in gaming | 7 min | Streaming & Gaming | Hojjat Jafarpour
Deltastream explains how streaming SQL (MATCH_RECOGNIZE) can detect cheating patterns such as aimbots by analysing ordered sequences of player actions in real time. By enriching live data with players’ historical headshot rates, the system distinguishes professional players from cheats
NEWS
StarRocks and Apache Polaris integration: Building a unified, high‑performance data lakehouse | 8 min | Data Lakehouse | Wayne Yang
This news brief highlights how coupling the StarRocks MPP database with Apache Polaris’s Iceberg REST catalog eliminates data silos and engine lock‑in. By keeping a single Iceberg copy with unified access controls, teams can run BI, ad‑hoc queries and ETL across Spark, Flink, Trino and StarRocks
DATA TUBE
Check the biggest obstacles enterprises face when adopting AI, including data quality, governance and talent shortages.
Ray Amjad tests Anthropic’s new “skills” feature for code generation and discusses how it compares to multi‑prompt methods.
Delta Lake Tips and Tricks | 60 min
NextGenLakehouse shares best practices for partitioning, vacuuming and performance optimisation when working with Delta Lake.
TOOL
Mistral’s production‑grade platform closes the loop from experimentation to deployment by providing built‑in evaluation, traceable feedback loops, versioning, governance and flexible deployment. Its observability, agent runtime and AI registry pillars help enterprise teams operate AI systems reliably
An AI agent that conducts research, provides citations and writes essays, blogs and market reports. CopyOwl boasts a 97 % satisfaction rate and emphasises fully referenced content and customizable tone. Users can produce ready‑to‑use reports in a few clicks
A mixture‑of‑experts code‑generation model trained via reinforcement learning on real coding tasks. Composer yields code four times faster than similar models, supports long‑context generation and is optimised for efficient tool usage and adherence to coding best practices
CONFS, EVENTS, WEBINARS AND MEETUPS
Compute Layer Unbundled – Market Trends Shaping Data Lakehouse in 2025 | 50 min | November 18, 3 PM CET| Data Engineering | Marek Wiewiórka & Radosław Szmit | Xebia
Part 4 of Xebia’s “Towards Data Lakehouse Architecture” webinar series. The session maps the compute landscape from single‑node to serverless options and examines emerging technologies like vectorised back‑ends and multi‑engine stacks.
INDUSTRY USE CASES
Nestlé completed the first phase of what it calls the world’s largest SAP S/4HANA Cloud Private Edition deployment. Over 50,000 employees across 112 countries already use the new platform, which embeds SAP’s AI copilot to support intelligent order fulfilment, real‑time decision‑making and standardized procurement. Executives say the upgrade frees resources for innovation and digital‑first marketing
Mondelez has invested more than $40 million in a generative‑AI tool built with Publicis Groupe and Accenture. The tool reduces marketing‑content production costs by 30–50 %, and the company plans to use it to produce short TV ads in time for next year’s holiday season. Early deployments include personalised social‑media videos for Chips Ahoy and Milka; the tool will expand to Oreo and Cadbury. All AI‑generated content is reviewed by humans to ensure compliance and avoid unhealthy or manipulative messages.
PINNACLE PICKS
Your last week top picks:
Apache Iceberg Explained in 10 Minutes – Everything You Need to Know! | 11 min | Data Engineering | Yusuf Ganiyu | Personal Channel
A quick, clear rundown of how Iceberg structures, stores, and optimizes modern data lakes.
Fivetran and dbt Labs Unite to Set the Standard for Open Data Infrastructure | 3 min | Fivetran Press Release
Parlant ensures safe and compliant AI agents using structured reasoning and strict mode response filters.
MaxCompute SQL Execution Engine's Comprehensive Refactoring of Complex Data Type Processing Ensures Smooth Migration from BigQuery | 6 min | Data and AI | Shuiqiang Chen | Alibaba Cloud Blog
Explore how Alibaba Cloud MaxCompute optimizes complex data types like ARRAY, MAP, and STRUCT to rival BigQuery—boosting performance and reducing costs.
_____________________
A quick, clear rundown of how Iceberg structures, stores, and optimizes modern data lakes.
Fivetran and dbt Labs Unite to Set the Standard for Open Data Infrastructure | 3 min | Fivetran Press Release
Parlant ensures safe and compliant AI agents using structured reasoning and strict mode response filters.
MaxCompute SQL Execution Engine's Comprehensive Refactoring of Complex Data Type Processing Ensures Smooth Migration from BigQuery | 6 min | Data and AI | Shuiqiang Chen | Alibaba Cloud Blog
Explore how Alibaba Cloud MaxCompute optimizes complex data types like ARRAY, MAP, and STRUCT to rival BigQuery—boosting performance and reducing costs.
_____________________
Have any interesting content to share in the DATA Pill newsletter?
