
ARTICLES
Using MLOps to Build a Real-time End-to-End Machine Learning Pipeline | 8 min | MLOps | Binance Blog
This article shows how Binance solves various business problems, including fraud, P2P scams, and stolen payment details. Read and understand better why they are using MLOps, how they effectively ensure the production model considers the latest data pattern, and see the standard operating procedure for real-time model development with a feature store.
Setting the Table: Benchmarking Open Table Formats | 6 min | Modern Data Stack | Brooklyn Data Co. Blog
Modern Data Stack is growing rapidly. Also, open table storage formats are getting more attention. Take a look at the article on the BROOKLYN DATA CO. blog and read how they ran a set of comprehensive workloads against each of them to test the performance of inserts and deletes, and the effect of these updates on the performance of subsequent reads.
Creative Testing: AI is the new A/B | 8 min | AI | Team Twigeo | Twigeo Blog
New limits for mobile tracking have led publishers like Meta and Google to shift from AB testing to dynamic creative formats, reliant on algorithms. It may look like marketers are losing creative control, but algorithms are reactive and the results sustain better campaign performance over time.
Search Pipeline | Part 1 | Part 2 | 10 min | Pipelines architecture | Stuart Cam | Canva Engineering Blog
In part 1 Stuart discusses the challenges Canva faced with current search architecture, the requirements needed for a new architecture and the considerations to take into account in designing a new solution. In the second part, we’ll dive into the details of our new search pipeline architecture.
Why Should I Care About Table Formats Like Apache Iceberg? | 7 min | Apache Iceberg | Alex Merced | Dremio Blog
Reducing your data warehouse footprint with an Apache Iceberg-based data lakehouse will open up your data to best-in-breed tools, reduce redundant storage/compute costs, and enable cutting-edge features like partition evolution/catalog branching to enhance your data architecture.
In the past, the Hive table format did not go far enough to make this a reality, but today Apache Iceberg offers robust features and performance for querying and manipulating your data on the lake.
Now is the time to turn your data lake into a data lakehouse and start seeing the time to insight shrink along with your data warehouse costs.
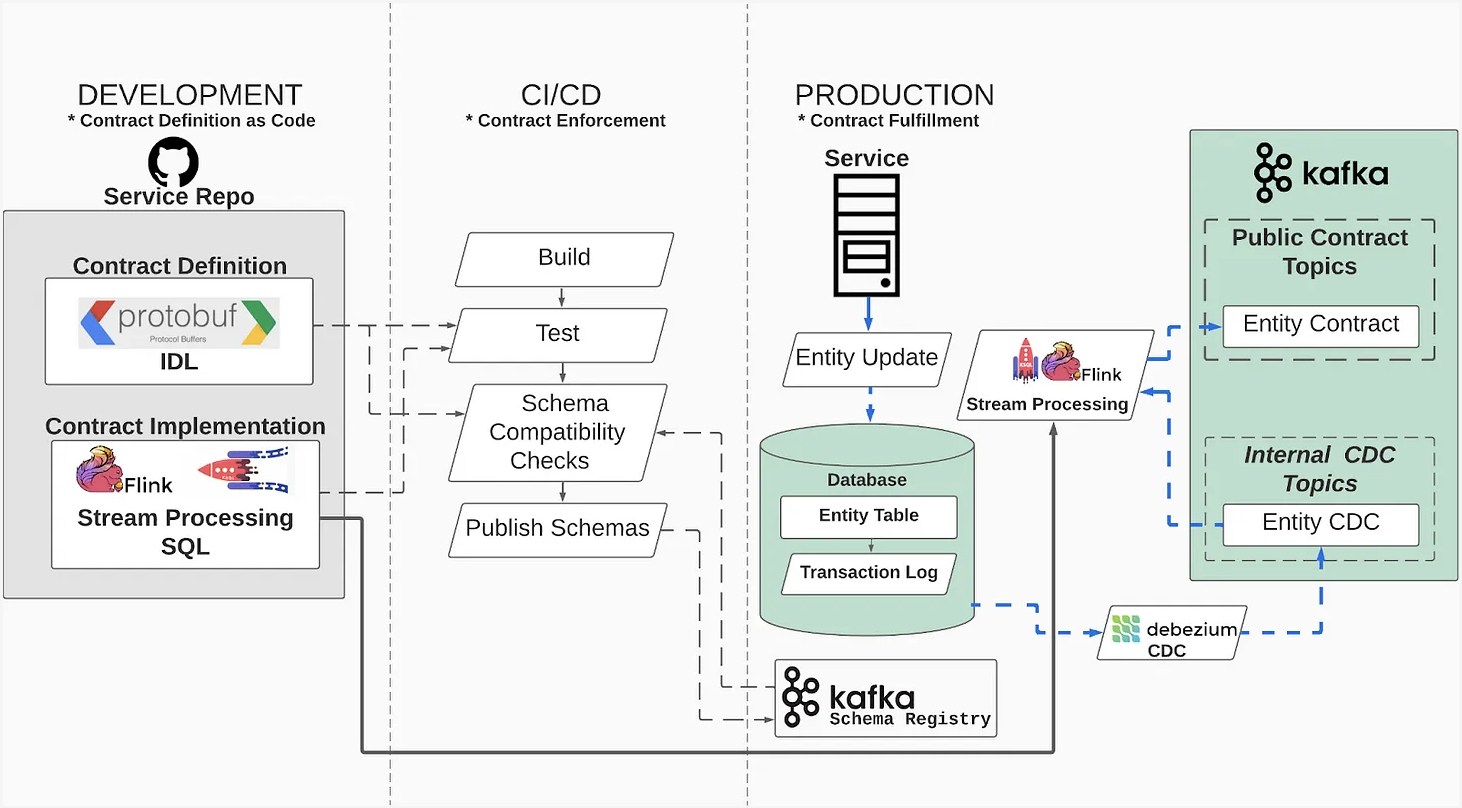
An Engineer's Guide to Data Contracts - Pt. 1 | 15 min | Change Data Capture | Chad Sanderson & Adrian Kreuziger | Data Products Blog
A review of a CDC-based implementation of Entity-based Data Contracts, covering contract definition, schema enforcement and fulfillment.
Vulnerability Management at Lyft: Enforcing the Cascade - Part 1 | 13 min | Security | Alex Chantavy | Lyft Engineering Blog
Lyft has built a vulnerability management program. This blog post focuses on the systems built to address OS and OS-package level vulnerabilities in a timely manner across hundreds of services run on Kubernetes. How did they eliminate most of the work required from other engineers? Alex describes the graph approach to finding where a given vulnerability was introduced — a key building block that enables the automation of most of the patch process.
How Pinterest Leverages Realtime User Actions in Recommendation to Boost Homefeed Engagement Volume | 10 min | ML | Xue Xia, Neng Gu, Dhruvil Deven Badani & Andrew Zhai | Pinterest Engineering Blog
How Pinterest improved the Homefeed engagement volume from a machine learning model design perspective — by leveraging real time user action features in the Homefeed recommender system.
Keeping up with Kedro — the latest developments in our development workflow framework | 3 min | Kedro | Merel Theisen | QuantumBlack, AI by McKinsey Blog
The benefits to Kedro users of having datasets in a separate package include:
- Kedro becomes more modular, making it possible for users to upgrade only the Kedro-datasets dependency in production rather than modifying the entire template.
- Users can deploy newer datasets with older versions of Kedro and can even use datasets without Kedro.
NEWS
Exciting new GitHub features powering machine learning | 5 min | ML | Seth Juarez | GitHub Blog
In November, GitHub released Universe announcements. How do they affect ML? Here are the findings from building machine learning projects directly on GitHub.
Jupyter Notebooks: Not only can I see the cells that have been added, but I can also see side-by-side the code differences within the cells, as well as the literal outputs. I can see at a glance the code that has changed and the effect it produces thanks to NbDime running under the hood.
While the rendering additions to GitHub are fantastic, there’s still the issue of executing the things in a reliable way when I’m away from my desk. Here’s a couple of gems to make these issues go away:
- GPUs for Codespaces
- Zero-config notebooks in Codespaces
- Edit your notebooks from VS Code, PyCharm, JupyterLab, on the web, or even using the CLI (powered by Codespaces)
AWS Announces DataZone, a New Data Management Service to Govern Data | 2 min | AWS | Daniel Dominguez | InfoQ Blog
At AWS re:Invent, Amazon Web Services announced Amazon DataZone, a new data management service that makes it faster and easier for customers to catalog, discover, share and govern data stored across AWS, on-premises and third-party sources.
AWS Glue for Apache Spark Native support for Data Lake Frameworks (Apache Hudi, Apache Iceberg, Delta Lake) | 2 min | AWS | Daniel Dominguez | AWS Blog
AWS Glue for Apache Spark now supports three open source data lake storage frameworks: Apache Hudi, Apache Iceberg and Linux Foundation Delta Lake. These frameworks allow you to read and write data in Amazon Simple Storage Service (Amazon S3) in a transactionally consistent manner. AWS Glue is a serverless, scalable data integration service that makes it easier to discover, prepare, move and integrate data from multiple sources.
TUTORIALS
How to create a Devcontainer for your Python project | 8 min | MLOps & Docker | Jeroen Overschie | GoDataDriven Blog
Dev Containers can help us:
- Get a reproducible development environment
- Instantly onboard new team members onto your project
- Better align the environments between team members
- Keep your dev environment up-to-date & reproducible, which saves your team time with going into production later
Let’s explore how we can set up a Dev container for your Python project!
Pursuing Lineage from Airflow using Custom Extractors | 8 min | Airflow | Maciej Obuchowski & Michael Robinson | OpenLineage Blog
Built-in support for custom extractors makes OpenLineage a flexible, highly adaptable solution for pipelines that use Airflow for orchestration.
PODCAST
Data Journey with Kevin Goldsmith (Anaconda) - Data & analytics used internally at Anaconda, SQL vs. Python, Layoffs and hiring in the tech sector, Agile data projects | 50 min | Analytics & Data | host: Adam Kawa ; guest: Kevin Goldsmith | Radio DaTa
- Data and analytics used internally by Anaconda
- The role and responsibilities of CTO at Anaconda
- SQL vs. Python in data science
- Hiring and layoffs in the tech industry
- An agile approach to data engineering and data science projects
Data Analytics Career Orientation | 1 h | Analytics | host: Jon Krohn; guest: Luke Barousse | Super Data Science
Talk with Luke Barousse, a full-time YouTuber who produces content to help aspiring data scientists, founder of MacroFit, a data-driven company that helps with meal planning.
- how data science can help you while working on a submarine
- helpful hacks for data science beginners
The Tech Unifying Search, Feed, Ads, and Promotions for Marketplaces | 30 min | Data Engineering | hosts: Neil C. Hughes; guest: Andrew Yates | Promoted.ai & The Tech Talks Daily Podcast
Andrew shares:
- how Promoted.ai plans to better match every buyer with a seller across all marketplaces on web or mobile
- how ad engineering works behind the scenes and tips ad engineers can use to design great ad marketplaces
- his experiences of getting Promoted.ai into Y Combinator and what the experience has been like
DATA TUBE
AI for Anomaly Detection and Root Cause Analysis in network area | 27 min | AI | Catherine Chevanet & Marzena Ołubek | Data Science Summit
Watch the video from the Data Science Summit. If you've ever wondered how AI is used in the telco network sector, then you are in luck. Orange, as a data-driven and AI-powered telco company, places Data and AI at the heart of our innovations for Smarter Networks. In this case, network management is supported by Machine Learning models for detecting anomalies based on different types of network data.
During the performance, Catherine and Marzena introduce the following topics:
- Co-create a Data Democracy
- Smarter Networks Ops (r) evolution with data-driven architecture
- Predictive Network Maintenance use cases for network data
- Challenges of network data syslogs
- ML models for anomaly detection based on network logs
- Deployment on GCP
Trino at Apple | 23 min | Analytics | Vinitha Gankid | Trino
Listen to how engineers from Apple shared the current usage of Trino at their company. They discuss how they support Trino as a service for multiple end-users, and the critical features that drew Apple to Trino. They wrap up with some challenges they faced and some development they have planned to contribute to Trino.
CONFS EVENTS AND MEETUPS
move(data) The Data Practitioner Conference | 1-8 December | Online
In the conference, speakers who have spent countless hours working on data integration take part. Best practices, horror stories, tools and workflows that will improve the way you work.
Security Best Practices with Databricks | 14 December | Live Webinar
- How to build a secure Databricks environment which complies with industry best practices;
- Where to find the best practices for your chosen Cloud provider;
- How to stay informed proactively about security risks before they manifest;
- About staying vigilant on any settings changes to remain compliant.
________________________
Have any interesting content to share in the DATA Pill newsletter?
➡ Join us on GitHub
